 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXunliang Cai
LLMs Know What They Need: Leveraging a Missing Information Guided Framework to Empower Retrieval-Augmented Generation
Apr 22, 2024
Retrieval-Augmented Generation (RAG) demonstrates great value in alleviating outdated knowledge or hallucination by supplying LLMs with updated and relevant knowledge. However, there are still several difficulties for RAG in understanding complex multi-hop query and retrieving relevant documents, which require LLMs to perform reasoning and retrieve step by step. Inspired by human's reasoning process in which they gradually search for the required information, it is natural to ask whether the LLMs could notice the missing information in each reasoning step. In this work, we first experimentally verified the ability of LLMs to extract information as well as to know the missing. Based on the above discovery, we propose a Missing Information Guided Retrieve-Extraction-Solving paradigm (MIGRES), where we leverage the identification of missing information to generate a targeted query that steers the subsequent knowledge retrieval. Besides, we design a sentence-level re-ranking filtering approach to filter the irrelevant content out from document, along with the information extraction capability of LLMs to extract useful information from cleaned-up documents, which in turn to bolster the overall efficacy of RAG. Extensive experiments conducted on multiple public datasets reveal the superiority of the proposed MIGRES method, and analytical experiments demonstrate the effectiveness of our proposed modules.
Parallel Decoding via Hidden Transfer for Lossless Large Language Model Acceleration
Apr 18, 2024Large language models (LLMs) have recently shown remarkable performance across a wide range of tasks. However, the substantial number of parameters in LLMs contributes to significant latency during model inference. This is particularly evident when utilizing autoregressive decoding methods, which generate one token in a single forward process, thereby not fully capitalizing on the parallel computing capabilities of GPUs. In this paper, we propose a novel parallel decoding approach, namely \textit{hidden transfer}, which decodes multiple successive tokens simultaneously in a single forward pass. The idea is to transfer the intermediate hidden states of the previous context to the \textit{pseudo} hidden states of the future tokens to be generated, and then the pseudo hidden states will pass the following transformer layers thereby assimilating more semantic information and achieving superior predictive accuracy of the future tokens. Besides, we use the novel tree attention mechanism to simultaneously generate and verify multiple candidates of output sequences, which ensure the lossless generation and further improves the generation efficiency of our method. Experiments demonstrate the effectiveness of our method. We conduct a lot of analytic experiments to prove our motivation. In terms of acceleration metrics, we outperform all the single-model acceleration techniques, including Medusa and Self-Speculative decoding.
Not All Contexts Are Equal: Teaching LLMs Credibility-aware Generation
Apr 10, 2024The rapid development of large language models has led to the widespread adoption of Retrieval-Augmented Generation (RAG), which integrates external knowledge to alleviate knowledge bottlenecks and mitigate hallucinations. However, the existing RAG paradigm inevitably suffers from the impact of flawed information introduced during the retrieval phrase, thereby diminishing the reliability and correctness of the generated outcomes. In this paper, we propose Credibility-aware Generation (CAG), a universally applicable framework designed to mitigate the impact of flawed information in RAG. At its core, CAG aims to equip models with the ability to discern and process information based on its credibility. To this end, we propose an innovative data transformation framework that generates data based on credibility, thereby effectively endowing models with the capability of CAG. Furthermore, to accurately evaluate the models' capabilities of CAG, we construct a comprehensive benchmark covering three critical real-world scenarios. Experimental results demonstrate that our model can effectively understand and utilize credibility for generation, significantly outperform other models with retrieval augmentation, and exhibit resilience against the disruption caused by noisy documents, thereby maintaining robust performance. Moreover, our model supports customized credibility, offering a wide range of potential applications.
Unraveling the Mystery of Scaling Laws: Part I
Mar 21, 2024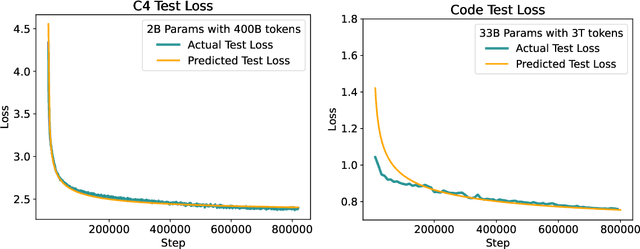
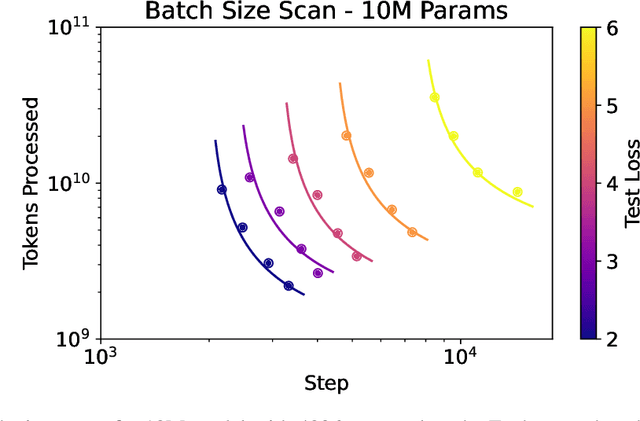
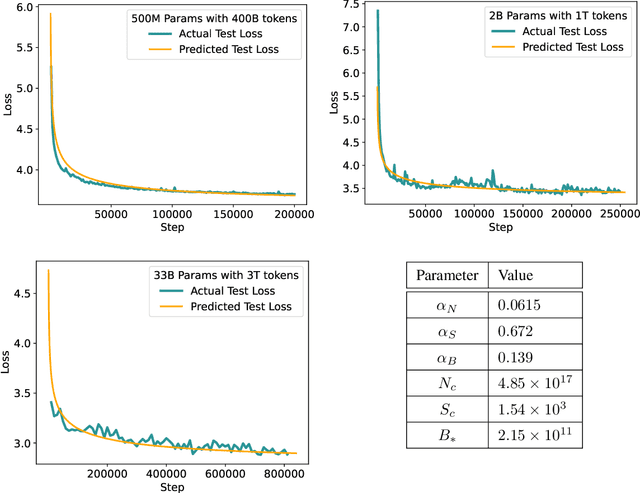
Scaling law principles indicate a power-law correlation between loss and variables such as model size, dataset size, and computational resources utilized during training. These principles play a vital role in optimizing various aspects of model pre-training, ultimately contributing to the success of large language models such as GPT-4, Llama and Gemini. However, the original scaling law paper by OpenAI did not disclose the complete details necessary to derive the precise scaling law formulas, and their conclusions are only based on models containing up to 1.5 billion parameters. Though some subsequent works attempt to unveil these details and scale to larger models, they often neglect the training dependency of important factors such as the learning rate, context length and batch size, leading to their failure to establish a reliable formula for predicting the test loss trajectory. In this technical report, we confirm that the scaling law formulations proposed in the original OpenAI paper remain valid when scaling the model size up to 33 billion, but the constant coefficients in these formulas vary significantly with the experiment setup. We meticulously identify influential factors and provide transparent, step-by-step instructions to estimate all constant terms in scaling-law formulas by training on models with only 1M~60M parameters. Using these estimated formulas, we showcase the capability to accurately predict various attributes for models with up to 33B parameters before their training, including (1) the minimum possible test loss; (2) the minimum required training steps and processed tokens to achieve a specific loss; (3) the critical batch size with an optimal time/computation trade-off at any loss value; and (4) the complete test loss trajectory with arbitrary batch size.
What Makes Quantization for Large Language Models Hard? An Empirical Study from the Lens of Perturbation
Mar 11, 2024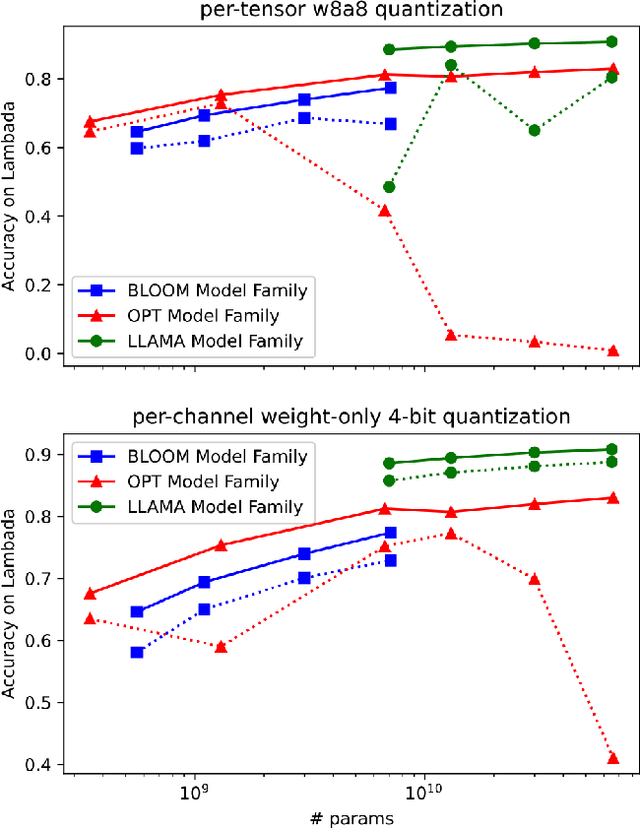
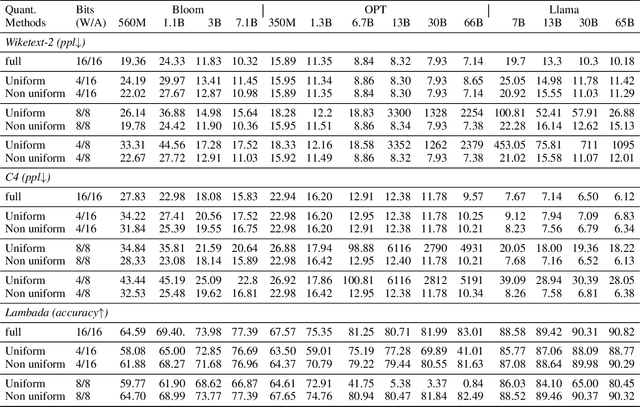
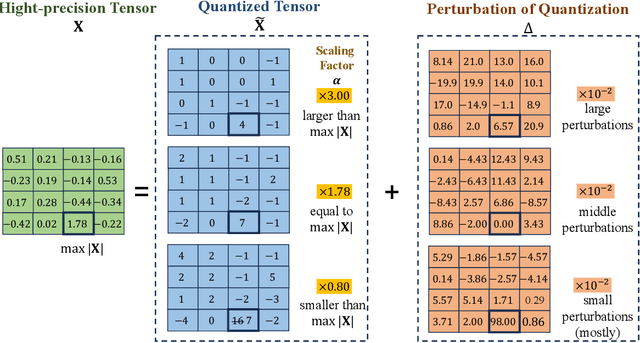
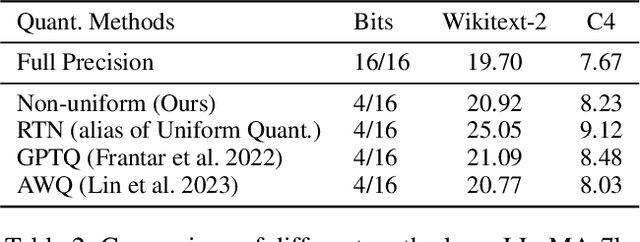
Quantization has emerged as a promising technique for improving the memory and computational efficiency of large language models (LLMs). Though the trade-off between performance and efficiency is well-known, there is still much to be learned about the relationship between quantization and LLM performance. To shed light on this relationship, we propose a new perspective on quantization, viewing it as perturbations added to the weights and activations of LLMs. We call this approach "the lens of perturbation". Using this lens, we conduct experiments with various artificial perturbations to explore their impact on LLM performance. Our findings reveal several connections between the properties of perturbations and LLM performance, providing insights into the failure cases of uniform quantization and suggesting potential solutions to improve the robustness of LLM quantization. To demonstrate the significance of our findings, we implement a simple non-uniform quantization approach based on our insights. Our experiments show that this approach achieves minimal performance degradation on both 4-bit weight quantization and 8-bit quantization for weights and activations. These results validate the correctness of our approach and highlight its potential to improve the efficiency of LLMs without sacrificing performance.
Beyond the Known: Investigating LLMs Performance on Out-of-Domain Intent Detection
Mar 04, 2024Out-of-domain (OOD) intent detection aims to examine whether the user's query falls outside the predefined domain of the system, which is crucial for the proper functioning of task-oriented dialogue (TOD) systems. Previous methods address it by fine-tuning discriminative models. Recently, some studies have been exploring the application of large language models (LLMs) represented by ChatGPT to various downstream tasks, but it is still unclear for their ability on OOD detection task.This paper conducts a comprehensive evaluation of LLMs under various experimental settings, and then outline the strengths and weaknesses of LLMs. We find that LLMs exhibit strong zero-shot and few-shot capabilities, but is still at a disadvantage compared to models fine-tuned with full resource. More deeply, through a series of additional analysis experiments, we discuss and summarize the challenges faced by LLMs and provide guidance for future work including injecting domain knowledge, strengthening knowledge transfer from IND(In-domain) to OOD, and understanding long instructions.
Learning or Self-aligning? Rethinking Instruction Fine-tuning
Mar 02, 2024Instruction Fine-tuning~(IFT) is a critical phase in building large language models~(LLMs). Previous works mainly focus on the IFT's role in the transfer of behavioral norms and the learning of additional world knowledge. However, the understanding of the underlying mechanisms of IFT remains significantly limited. In this paper, we design a knowledge intervention framework to decouple the potential underlying factors of IFT, thereby enabling individual analysis of different factors. Surprisingly, our experiments reveal that attempting to learn additional world knowledge through IFT often struggles to yield positive impacts and can even lead to markedly negative effects. Further, we discover that maintaining internal knowledge consistency before and after IFT is a critical factor for achieving successful IFT. Our findings reveal the underlying mechanisms of IFT and provide robust support for some very recent and potential future works.
DolphCoder: Echo-Locating Code Large Language Models with Diverse and Multi-Objective Instruction Tuning
Feb 14, 2024Code Large Language Models (Code LLMs) have demonstrated outstanding performance in code-related tasks. Several instruction tuning approaches have been proposed to boost the code generation performance of pre-trained Code LLMs. In this paper, we introduce a diverse instruction model (DolphCoder) with self-evaluating for code generation. It learns diverse instruction targets and combines a code evaluation objective to enhance its code generation ability. Our model achieves superior performance on the HumanEval and MBPP benchmarks, demonstrating new insights for future code instruction tuning work. Our key findings are: (1) Augmenting more diverse responses with distinct reasoning paths increases the code capability of LLMs. (2) Improving one's ability to evaluate the correctness of code solutions also enhances their ability to create it.
Improving Input-label Mapping with Demonstration Replay for In-context Learning
Oct 30, 2023In-context learning (ICL) is an emerging capability of large autoregressive language models where a few input-label demonstrations are appended to the input to enhance the model's understanding of downstream NLP tasks, without directly adjusting the model parameters. The effectiveness of ICL can be attributed to the strong language modeling capabilities of large language models (LLMs), which enable them to learn the mapping between input and labels based on in-context demonstrations. Despite achieving promising results, the causal nature of language modeling in ICL restricts the attention to be backward only, i.e., a token only attends to its previous tokens, failing to capture the full input-label information and limiting the model's performance. In this paper, we propose a novel ICL method called Repeated Demonstration with Sliding Causal Attention, (RdSca). Specifically, we duplicate later demonstrations and concatenate them to the front, allowing the model to `observe' the later information even under the causal restriction. Besides, we introduce sliding causal attention, which customizes causal attention to avoid information leakage. Experimental results show that our method significantly improves the input-label mapping in ICL demonstrations. We also conduct an in-depth analysis of how to customize the causal attention without training, which has been an unexplored area in previous research.
Retrieval-based Knowledge Transfer: An Effective Approach for Extreme Large Language Model Compression
Oct 24, 2023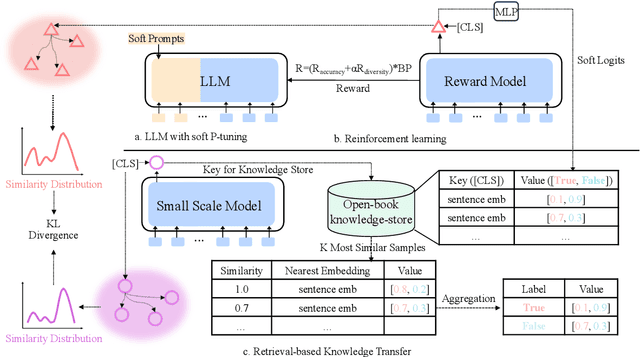
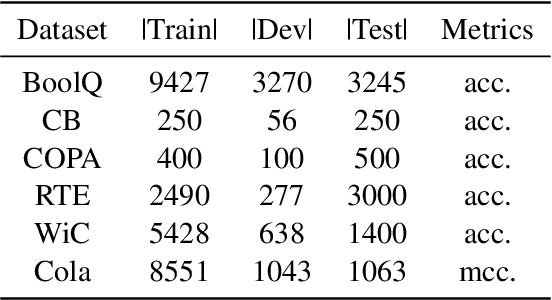
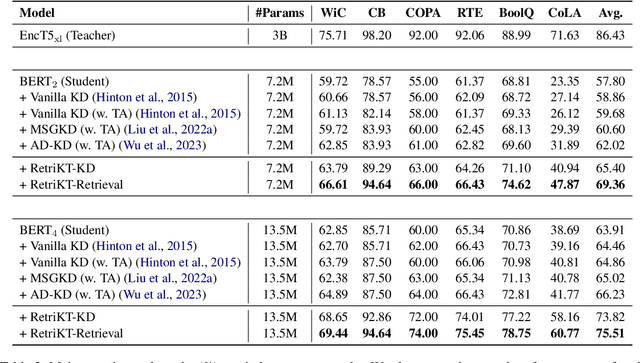
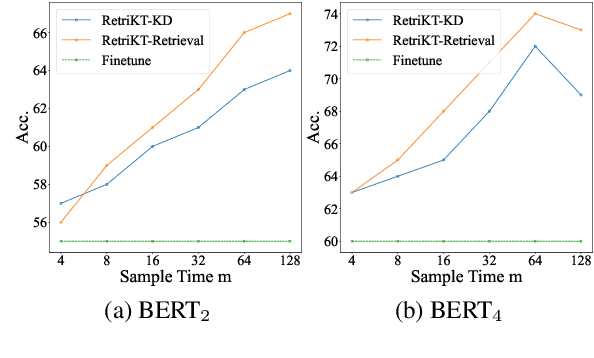
Large-scale pre-trained language models (LLMs) have demonstrated exceptional performance in various natural language processing (NLP) tasks. However, the massive size of these models poses huge challenges for their deployment in real-world applications. While numerous model compression techniques have been proposed, most of them are not well-suited for achieving extreme model compression when there is a significant gap in model scale. In this paper, we introduce a novel compression paradigm called Retrieval-based Knowledge Transfer (RetriKT), which effectively transfers the knowledge of LLMs to extremely small-scale models (e.g., 1%). In particular, our approach extracts knowledge from LLMs to construct a knowledge store, from which the small-scale model can retrieve relevant information and leverage it for effective inference. To improve the quality of the model, soft prompt tuning and Proximal Policy Optimization (PPO) reinforcement learning techniques are employed. Extensive experiments are conducted on low-resource tasks from SuperGLUE and GLUE benchmarks. The results demonstrate that the proposed approach significantly enhances the performance of small-scale models by leveraging the knowledge from LLMs.