 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuanglu Wan
Learning or Self-aligning? Rethinking Instruction Fine-tuning
Mar 02, 2024
Instruction Fine-tuning~(IFT) is a critical phase in building large language models~(LLMs). Previous works mainly focus on the IFT's role in the transfer of behavioral norms and the learning of additional world knowledge. However, the understanding of the underlying mechanisms of IFT remains significantly limited. In this paper, we design a knowledge intervention framework to decouple the potential underlying factors of IFT, thereby enabling individual analysis of different factors. Surprisingly, our experiments reveal that attempting to learn additional world knowledge through IFT often struggles to yield positive impacts and can even lead to markedly negative effects. Further, we discover that maintaining internal knowledge consistency before and after IFT is a critical factor for achieving successful IFT. Our findings reveal the underlying mechanisms of IFT and provide robust support for some very recent and potential future works.
A Task-oriented Dialog Model with Task-progressive and Policy-aware Pre-training
Oct 01, 2023Pre-trained conversation models (PCMs) have achieved promising progress in recent years. However, existing PCMs for Task-oriented dialog (TOD) are insufficient for capturing the sequential nature of the TOD-related tasks, as well as for learning dialog policy information. To alleviate these problems, this paper proposes a task-progressive PCM with two policy-aware pre-training tasks. The model is pre-trained through three stages where TOD-related tasks are progressively employed according to the task logic of the TOD system. A global policy consistency task is designed to capture the multi-turn dialog policy sequential relation, and an act-based contrastive learning task is designed to capture similarities among samples with the same dialog policy. Our model achieves better results on both MultiWOZ and In-Car end-to-end dialog modeling benchmarks with only 18\% parameters and 25\% pre-training data compared to the previous state-of-the-art PCM, GALAXY.
CPPF: A contextual and post-processing-free model for automatic speech recognition
Sep 21, 2023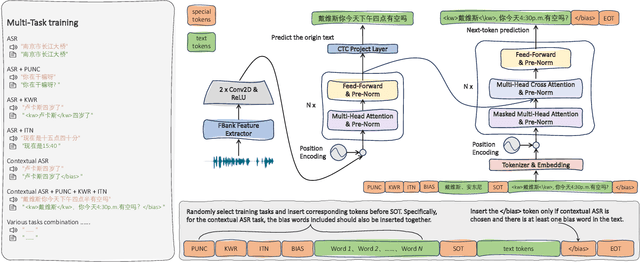
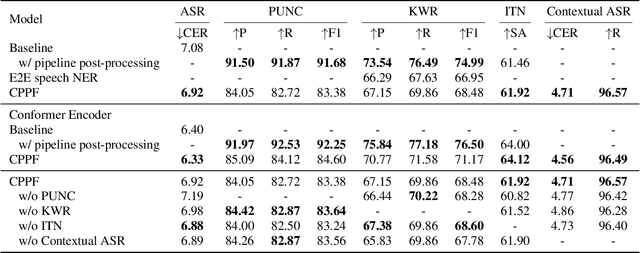

ASR systems have become increasingly widespread in recent years. However, their textual outputs often require post-processing tasks before they can be practically utilized. To address this issue, we draw inspiration from the multifaceted capabilities of LLMs and Whisper, and focus on integrating multiple ASR text processing tasks related to speech recognition into the ASR model. This integration not only shortens the multi-stage pipeline, but also prevents the propagation of cascading errors, resulting in direct generation of post-processed text. In this study, we focus on ASR-related processing tasks, including Contextual ASR and multiple ASR post processing tasks. To achieve this objective, we introduce the CPPF model, which offers a versatile and highly effective alternative to ASR processing. CPPF seamlessly integrates these tasks without any significant loss in recognition performance.
Enhancing Multilingual Speech Recognition through Language Prompt Tuning and Frame-Level Language Adapter
Sep 19, 2023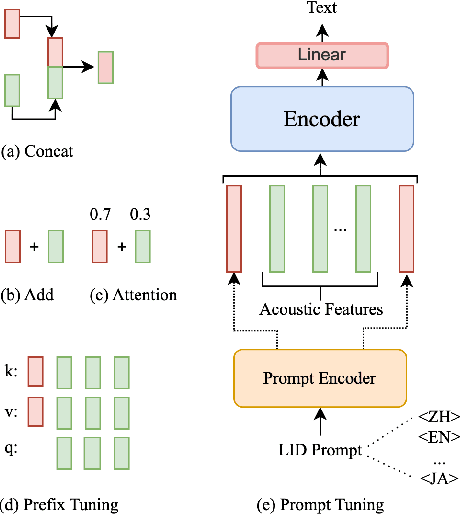
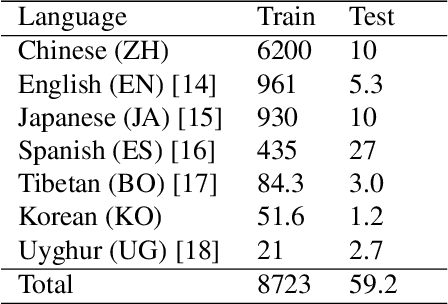

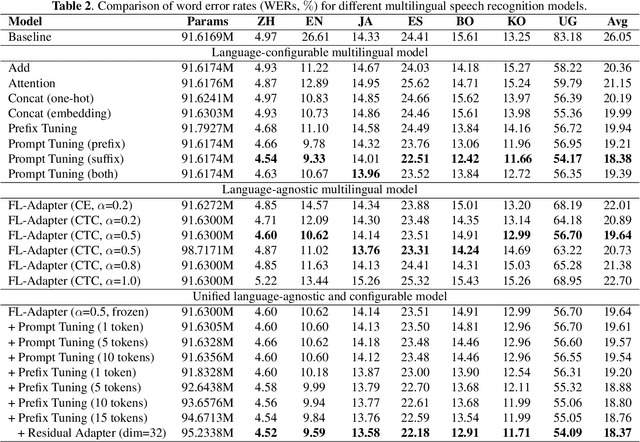
Multilingual intelligent assistants, such as ChatGPT, have recently gained popularity. To further expand the applications of multilingual artificial intelligence assistants and facilitate international communication, it is essential to enhance the performance of multilingual speech recognition, which is a crucial component of speech interaction. In this paper, we propose two simple and parameter-efficient methods: language prompt tuning and frame-level language adapter, to respectively enhance language-configurable and language-agnostic multilingual speech recognition. Additionally, we explore the feasibility of integrating these two approaches using parameter-efficient fine-tuning methods. Our experiments demonstrate significant performance improvements across seven languages using our proposed methods.
Exploiting Pseudo Future Contexts for Emotion Recognition in Conversations
Jun 27, 2023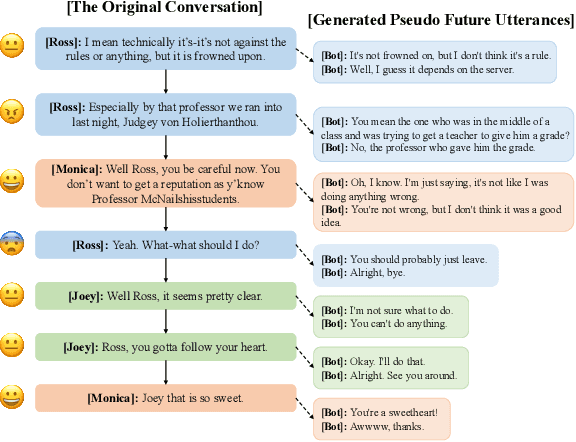
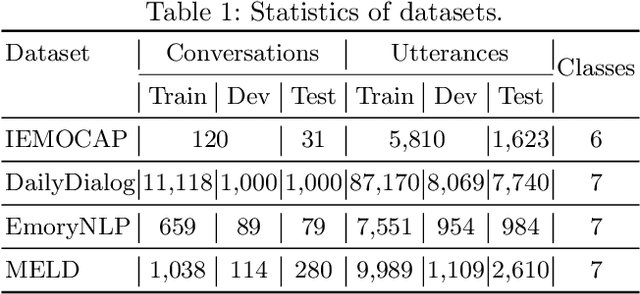
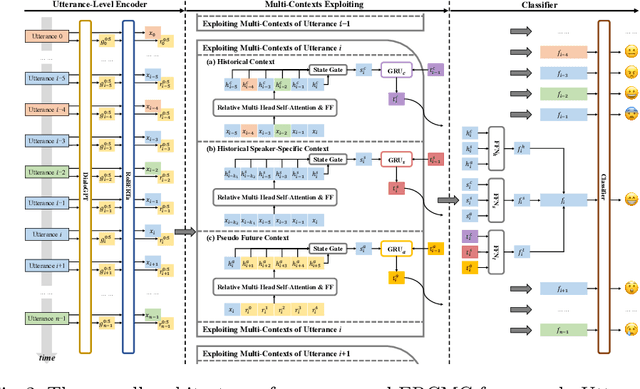
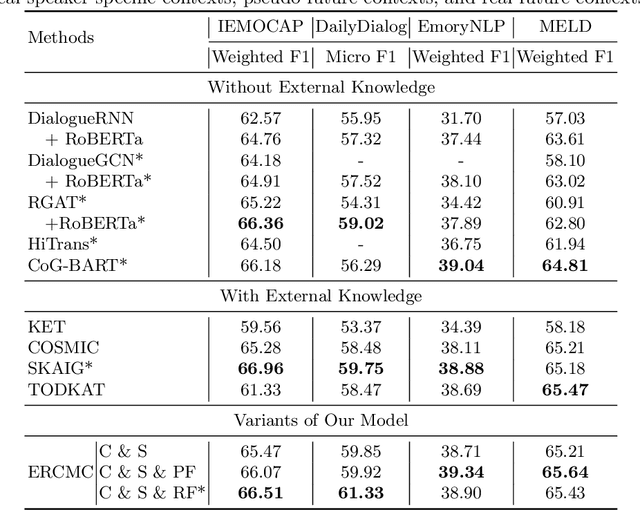
With the extensive accumulation of conversational data on the Internet, emotion recognition in conversations (ERC) has received increasing attention. Previous efforts of this task mainly focus on leveraging contextual and speaker-specific features, or integrating heterogeneous external commonsense knowledge. Among them, some heavily rely on future contexts, which, however, are not always available in real-life scenarios. This fact inspires us to generate pseudo future contexts to improve ERC. Specifically, for an utterance, we generate its future context with pre-trained language models, potentially containing extra beneficial knowledge in a conversational form homogeneous with the historical ones. These characteristics make pseudo future contexts easily fused with historical contexts and historical speaker-specific contexts, yielding a conceptually simple framework systematically integrating multi-contexts. Experimental results on four ERC datasets demonstrate our method's superiority. Further in-depth analyses reveal that pseudo future contexts can rival real ones to some extent, especially in relatively context-independent conversations.
Dialog-to-Actions: Building Task-Oriented Dialogue System via Action-Level Generation
Apr 03, 2023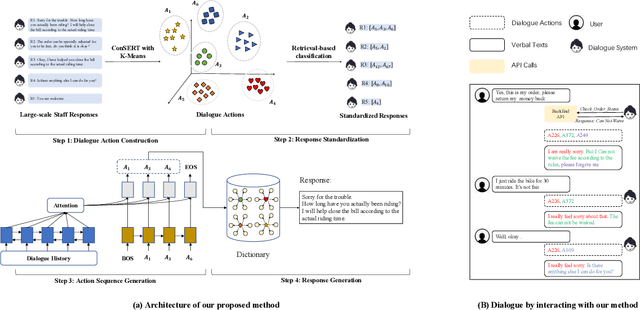

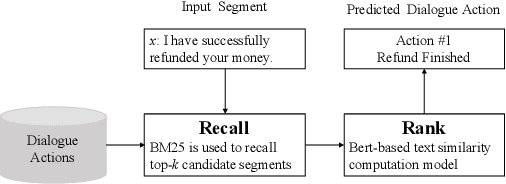
End-to-end generation-based approaches have been investigated and applied in task-oriented dialogue systems. However, in industrial scenarios, existing methods face the bottlenecks of controllability (e.g., domain-inconsistent responses, repetition problem, etc) and efficiency (e.g., long computation time, etc). In this paper, we propose a task-oriented dialogue system via action-level generation. Specifically, we first construct dialogue actions from large-scale dialogues and represent each natural language (NL) response as a sequence of dialogue actions. Further, we train a Sequence-to-Sequence model which takes the dialogue history as input and outputs sequence of dialogue actions. The generated dialogue actions are transformed into verbal responses. Experimental results show that our light-weighted method achieves competitive performance, and has the advantage of controllability and efficiency.
Covariance Regularization for Probabilistic Linear Discriminant Analysis
Dec 06, 2022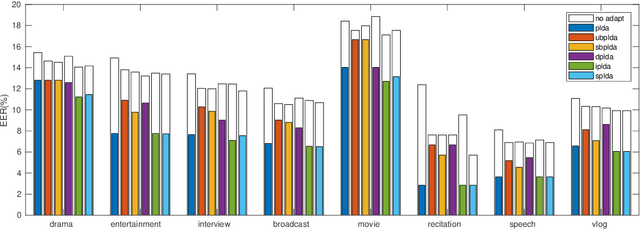
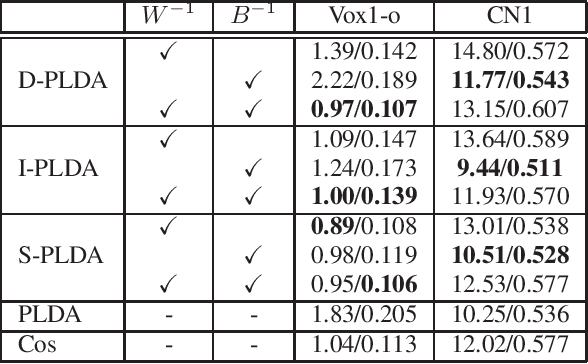
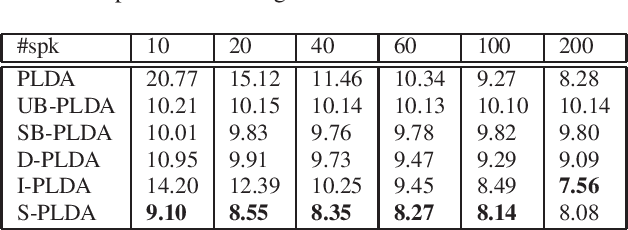
Probabilistic linear discriminant analysis (PLDA) is commonly used in speaker verification systems to score the similarity of speaker embeddings. Recent studies improved the performance of PLDA in domain-matched conditions by diagonalizing its covariance. We suspect such brutal pruning approach could eliminate its capacity in modeling dimension correlation of speaker embeddings, leading to inadequate performance with domain adaptation. This paper explores two alternative covariance regularization approaches, namely, interpolated PLDA and sparse PLDA, to tackle the problem. The interpolated PLDA incorporates the prior knowledge from cosine scoring to interpolate the covariance of PLDA. The sparse PLDA introduces a sparsity penalty to update the covariance. Experimental results demonstrate that both approaches outperform diagonal regularization noticeably with domain adaptation. In addition, in-domain data can be significantly reduced when training sparse PLDA for domain adaptation.
Label-free Knowledge Distillation with Contrastive Loss for Light-weight Speaker Recognition
Dec 06, 2022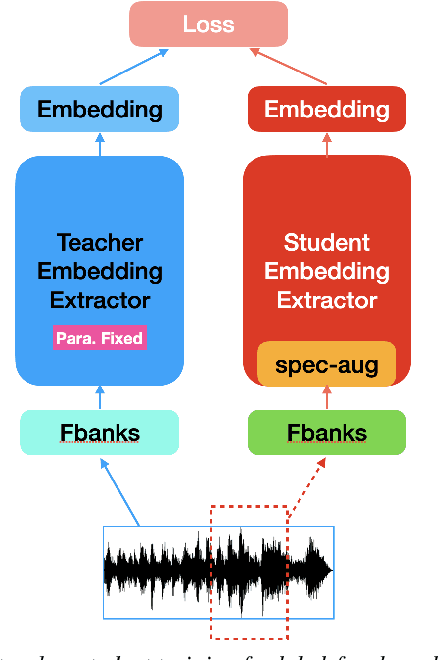
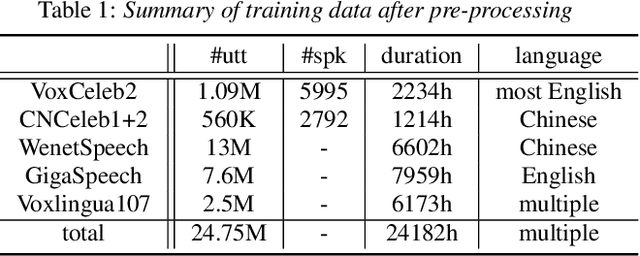
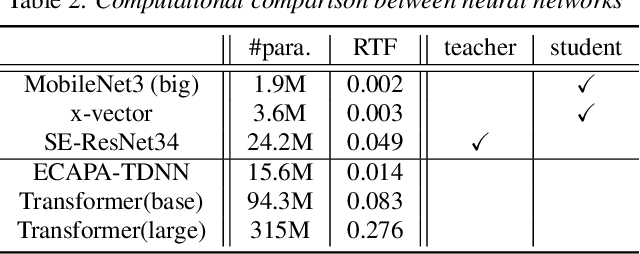
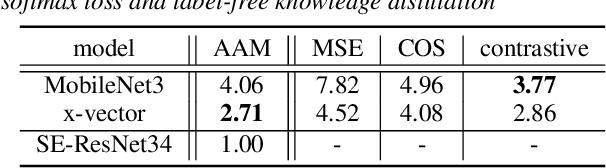
Very deep models for speaker recognition (SR) have demonstrated remarkable performance improvement in recent research. However, it is impractical to deploy these models for on-device applications with constrained computational resources. On the other hand, light-weight models are highly desired in practice despite their sub-optimal performance. This research aims to improve light-weight SR models through large-scale label-free knowledge distillation (KD). Existing KD approaches for SR typically require speaker labels to learn task-specific knowledge, due to the inefficiency of conventional loss for distillation. To address the inefficiency problem and achieve label-free KD, we propose to employ the contrastive loss from self-supervised learning for distillation. Extensive experiments are conducted on a collection of public speech datasets from diverse sources. Results on light-weight SR models show that the proposed approach of label-free KD with contrastive loss consistently outperforms both conventional distillation methods and self-supervised learning methods by a significant margin.
MUSIED: A Benchmark for Event Detection from Multi-Source Heterogeneous Informal Texts
Nov 25, 2022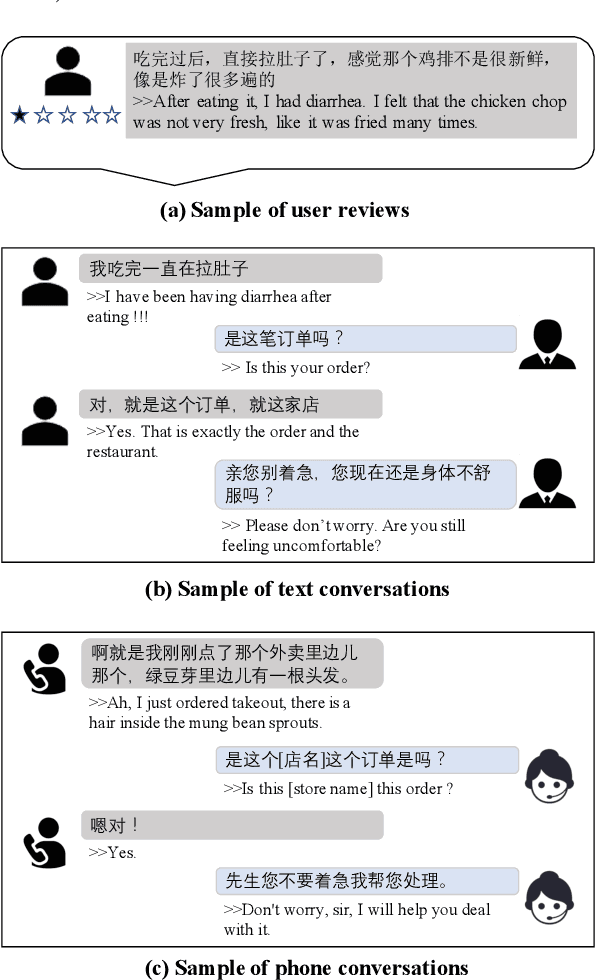
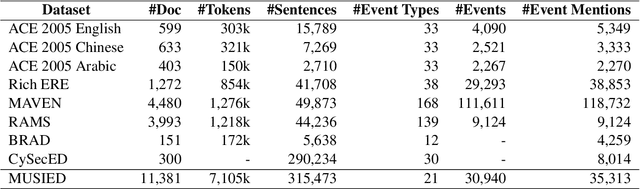

Event detection (ED) identifies and classifies event triggers from unstructured texts, serving as a fundamental task for information extraction. Despite the remarkable progress achieved in the past several years, most research efforts focus on detecting events from formal texts (e.g., news articles, Wikipedia documents, financial announcements). Moreover, the texts in each dataset are either from a single source or multiple yet relatively homogeneous sources. With massive amounts of user-generated text accumulating on the Web and inside enterprises, identifying meaningful events in these informal texts, usually from multiple heterogeneous sources, has become a problem of significant practical value. As a pioneering exploration that expands event detection to the scenarios involving informal and heterogeneous texts, we propose a new large-scale Chinese event detection dataset based on user reviews, text conversations, and phone conversations in a leading e-commerce platform for food service. We carefully investigate the proposed dataset's textual informality and multi-source heterogeneity characteristics by inspecting data samples quantitatively and qualitatively. Extensive experiments with state-of-the-art event detection methods verify the unique challenges posed by these characteristics, indicating that multi-source informal event detection remains an open problem and requires further efforts. Our benchmark and code are released at \url{https://github.com/myeclipse/MUSIED}.
Peak-First CTC: Reducing the Peak Latency of CTC Models by Applying Peak-First Regularization
Nov 07, 2022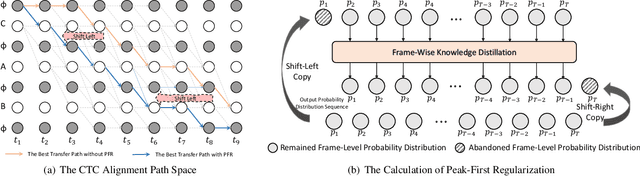
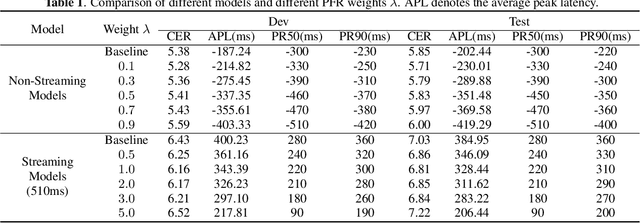
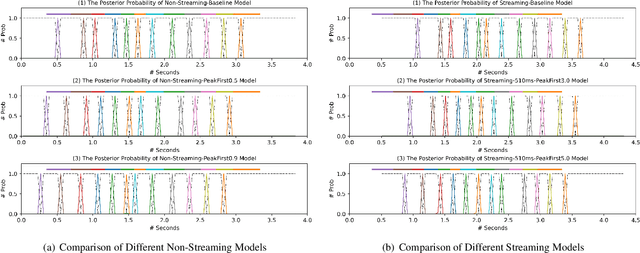
The CTC model has been widely applied to many application scenarios because of its simple structure, excellent performance, and fast inference speed. There are many peaks in the probability distribution predicted by the CTC models, and each peak represents a non-blank token. The recognition latency of CTC models can be reduced by encouraging the model to predict peaks earlier. Existing methods to reduce latency require modifying the transition relationship between tokens in the forward-backward algorithm, and the gradient calculation. Some of these methods even depend on the forced alignment results provided by other pretrained models. The above methods are complex to implement. To reduce the peak latency, we propose a simple and novel method named peak-first regularization, which utilizes a frame-wise knowledge distillation function to force the probability distribution of the CTC model to shift left along the time axis instead of directly modifying the calculation process of CTC loss and gradients. All the experiments are conducted on a Chinese Mandarin dataset AISHELL-1. We have verified the effectiveness of the proposed regularization on both streaming and non-streaming CTC models respectively. The results show that the proposed method can reduce the average peak latency by about 100 to 200 milliseconds with almost no degradation of recognition accuracy.