 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuxuan Liu
Towards a Foundation Model for Partial Differential Equations: Multi-Operator Learning and Extrapolation
Apr 19, 2024
Foundation models, such as large language models, have demonstrated success in addressing various language and image processing tasks. In this work, we introduce a multi-modal foundation model for scientific problems, named PROSE-PDE. Our model, designed for bi-modality to bi-modality learning, is a multi-operator learning approach which can predict future states of spatiotemporal systems while concurrently learning the underlying governing equations of the physical system. Specifically, we focus on multi-operator learning by training distinct one-dimensional time-dependent nonlinear constant coefficient partial differential equations, with potential applications to many physical applications including physics, geology, and biology. More importantly, we provide three extrapolation studies to demonstrate that PROSE-PDE can generalize physical features through the robust training of multiple operators and that the proposed model can extrapolate to predict PDE solutions whose models or data were unseen during the training. Furthermore, we show through systematic numerical experiments that the utilization of the symbolic modality in our model effectively resolves the well-posedness problems with training multiple operators and thus enhances our model's predictive capabilities.
FusionPortableV2: A Unified Multi-Sensor Dataset for Generalized SLAM Across Diverse Platforms and Scalable Environments
Apr 12, 2024Simultaneous Localization and Mapping (SLAM) technology has been widely applied in various robotic scenarios, from rescue operations to autonomous driving. However, the generalization of SLAM algorithms remains a significant challenge, as current datasets often lack scalability in terms of platforms and environments. To address this limitation, we present FusionPortableV2, a multi-sensor SLAM dataset featuring notable sensor diversity, varied motion patterns, and a wide range of environmental scenarios. Our dataset comprises $27$ sequences, spanning over $2.5$ hours and collected from four distinct platforms: a handheld suite, wheeled and legged robots, and vehicles. These sequences cover diverse settings, including buildings, campuses, and urban areas, with a total length of $38.7km$. Additionally, the dataset includes ground-truth (GT) trajectories and RGB point cloud maps covering approximately $0.3km^2$. To validate the utility of our dataset in advancing SLAM research, we assess several state-of-the-art (SOTA) SLAM algorithms. Furthermore, we demonstrate the dataset's broad applicability beyond traditional SLAM tasks by investigating its potential for monocular depth estimation. The complete dataset, including sensor data, GT, and calibration details, is accessible at https://fusionportable.github.io/dataset/fusionportable_v2.
Plug-and-Play Grounding of Reasoning in Multimodal Large Language Models
Mar 28, 2024


The surge of Multimodal Large Language Models (MLLMs), given their prominent emergent capabilities in instruction following and reasoning, has greatly advanced the field of visual reasoning. However, constrained by their non-lossless image tokenization, most MLLMs fall short of comprehensively capturing details of text and objects, especially in high-resolution images. To address this, we propose P2G, a novel framework for plug-and-play grounding of reasoning in MLLMs. Specifically, P2G exploits the tool-usage potential of MLLMs to employ expert agents to achieve on-the-fly grounding to critical visual and textual objects of image, thus achieving deliberate reasoning via multimodal prompting. We further create P2GB, a benchmark aimed at assessing MLLMs' ability to understand inter-object relationships and text in challenging high-resolution images. Comprehensive experiments on visual reasoning tasks demonstrate the superiority of P2G. Noteworthy, P2G achieved comparable performance with GPT-4V on P2GB, with a 7B backbone. Our work highlights the potential of plug-and-play grounding of reasoning and opens up a promising alternative beyond model scaling.
CurbNet: Curb Detection Framework Based on LiDAR Point Cloud Segmentation
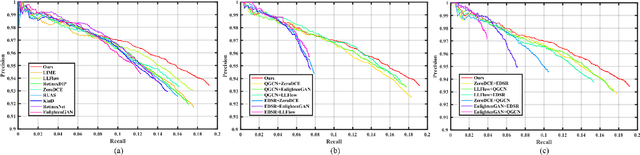
Mar 25, 2024Curb detection is an important function in intelligent driving and can be used to determine drivable areas of the road. However, curbs are difficult to detect due to the complex road environment. This paper introduces CurbNet, a novel framework for curb detection, leveraging point cloud segmentation. Addressing the dearth of comprehensive curb datasets and the absence of 3D annotations, we have developed the 3D-Curb dataset, encompassing 7,100 frames, which represents the largest and most categorically diverse collection of curb point clouds currently available. Recognizing that curbs are primarily characterized by height variations, our approach harnesses spatially-rich 3D point clouds for training. To tackle the challenges presented by the uneven distribution of curb features on the xy-plane and their reliance on z-axis high-frequency features, we introduce the multi-scale and channel attention (MSCA) module, a bespoke solution designed to optimize detection performance. Moreover, we propose an adaptive weighted loss function group, specifically formulated to counteract the imbalance in the distribution of curb point clouds relative to other categories. Our extensive experimentation on 2 major datasets has yielded results that surpass existing benchmarks set by leading curb detection and point cloud segmentation models. By integrating multi-clustering and curve fitting techniques in our post-processing stage, we have substantially reduced noise in curb detection, thereby enhancing precision to 0.8744. Notably, CurbNet has achieved an exceptional average metrics of over 0.95 at a tolerance of just 0.15m, thereby establishing a new benchmark. Furthermore, corroborative real-world experiments and dataset analyzes mutually validate each other, solidifying CurbNet's superior detection proficiency and its robust generalizability.
Multiple Latent Space Mapping for Compressed Dark Image Enhancement
Mar 12, 2024


Dark image enhancement aims at converting dark images to normal-light images. Existing dark image enhancement methods take uncompressed dark images as inputs and achieve great performance. However, in practice, dark images are often compressed before storage or transmission over the Internet. Current methods get poor performance when processing compressed dark images. Artifacts hidden in the dark regions are amplified by current methods, which results in uncomfortable visual effects for observers. Based on this observation, this study aims at enhancing compressed dark images while avoiding compression artifacts amplification. Since texture details intertwine with compression artifacts in compressed dark images, detail enhancement and blocking artifacts suppression contradict each other in image space. Therefore, we handle the task in latent space. To this end, we propose a novel latent mapping network based on variational auto-encoder (VAE). Firstly, different from previous VAE-based methods with single-resolution features only, we exploit multiple latent spaces with multi-resolution features, to reduce the detail blur and improve image fidelity. Specifically, we train two multi-level VAEs to project compressed dark images and normal-light images into their latent spaces respectively. Secondly, we leverage a latent mapping network to transform features from compressed dark space to normal-light space. Specifically, since the degradation models of darkness and compression are different from each other, the latent mapping process is divided mapping into enlightening branch and deblocking branch. Comprehensive experiments demonstrate that the proposed method achieves state-of-the-art performance in compressed dark image enhancement.
Harnessing Multi-Role Capabilities of Large Language Models for Open-Domain Question Answering
Mar 08, 2024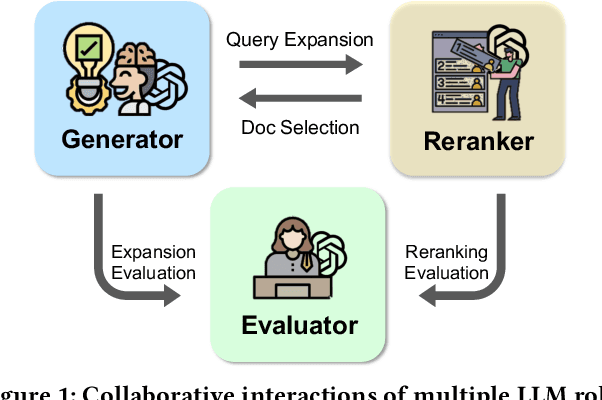
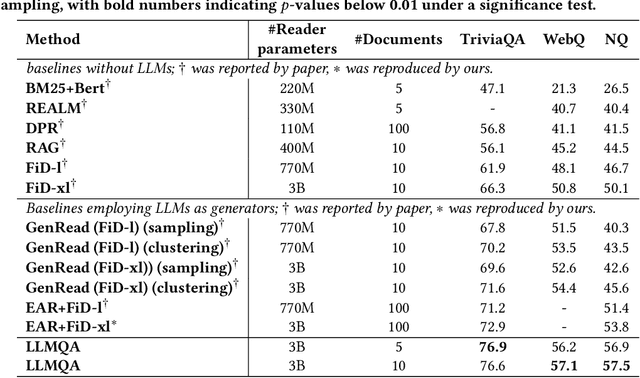
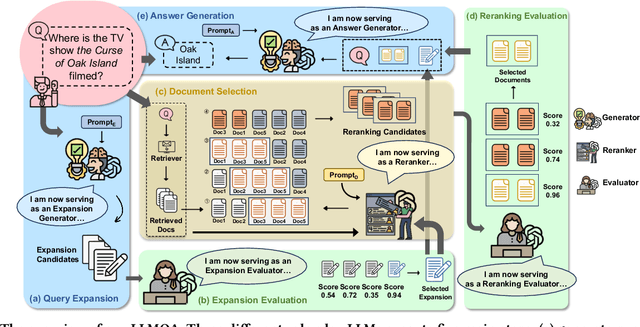

Open-domain question answering (ODQA) has emerged as a pivotal research spotlight in information systems. Existing methods follow two main paradigms to collect evidence: (1) The \textit{retrieve-then-read} paradigm retrieves pertinent documents from an external corpus; and (2) the \textit{generate-then-read} paradigm employs large language models (LLMs) to generate relevant documents. However, neither can fully address multifaceted requirements for evidence. To this end, we propose LLMQA, a generalized framework that formulates the ODQA process into three basic steps: query expansion, document selection, and answer generation, combining the superiority of both retrieval-based and generation-based evidence. Since LLMs exhibit their excellent capabilities to accomplish various tasks, we instruct LLMs to play multiple roles as generators, rerankers, and evaluators within our framework, integrating them to collaborate in the ODQA process. Furthermore, we introduce a novel prompt optimization algorithm to refine role-playing prompts and steer LLMs to produce higher-quality evidence and answers. Extensive experimental results on widely used benchmarks (NQ, WebQ, and TriviaQA) demonstrate that LLMQA achieves the best performance in terms of both answer accuracy and evidence quality, showcasing its potential for advancing ODQA research and applications.
Scalable Vision-Based 3D Object Detection and Monocular Depth Estimation for Autonomous Driving
Mar 04, 2024
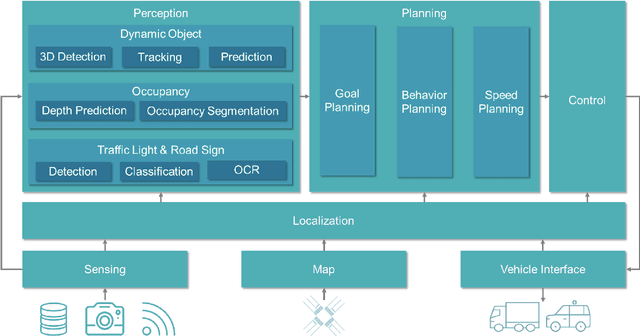
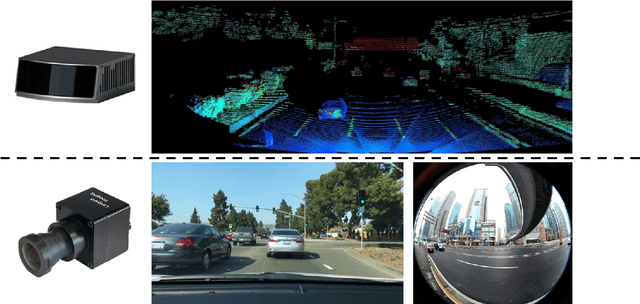
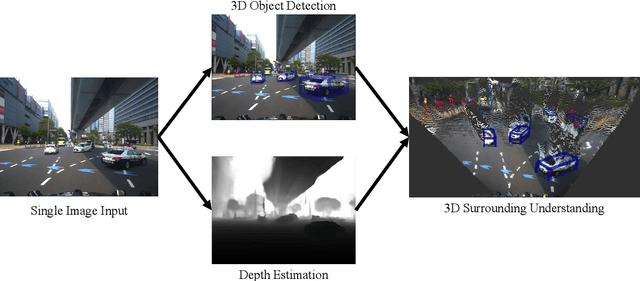
This dissertation is a multifaceted contribution to the advancement of vision-based 3D perception technologies. In the first segment, the thesis introduces structural enhancements to both monocular and stereo 3D object detection algorithms. By integrating ground-referenced geometric priors into monocular detection models, this research achieves unparalleled accuracy in benchmark evaluations for monocular 3D detection. Concurrently, the work refines stereo 3D detection paradigms by incorporating insights and inferential structures gleaned from monocular networks, thereby augmenting the operational efficiency of stereo detection systems. The second segment is devoted to data-driven strategies and their real-world applications in 3D vision detection. A novel training regimen is introduced that amalgamates datasets annotated with either 2D or 3D labels. This approach not only augments the detection models through the utilization of a substantially expanded dataset but also facilitates economical model deployment in real-world scenarios where only 2D annotations are readily available. Lastly, the dissertation presents an innovative pipeline tailored for unsupervised depth estimation in autonomous driving contexts. Extensive empirical analyses affirm the robustness and efficacy of this newly proposed pipeline. Collectively, these contributions lay a robust foundation for the widespread adoption of vision-based 3D perception technologies in autonomous driving applications.
HD-Eval: Aligning Large Language Model Evaluators Through Hierarchical Criteria Decomposition
Feb 24, 2024Large language models (LLMs) have emerged as a promising alternative to expensive human evaluations. However, the alignment and coverage of LLM-based evaluations are often limited by the scope and potential bias of the evaluation prompts and criteria. To address this challenge, we propose HD-Eval, a novel framework that iteratively aligns LLM-based evaluators with human preference via Hierarchical Criteria Decomposition. HD-Eval inherits the essence from the evaluation mindset of human experts and enhances the alignment of LLM-based evaluators by decomposing a given evaluation task into finer-grained criteria, aggregating them according to estimated human preferences, pruning insignificant criteria with attribution, and further decomposing significant criteria. By integrating these steps within an iterative alignment training process, we obtain a hierarchical decomposition of criteria that comprehensively captures aspects of natural language at multiple levels of granularity. Implemented as a white box, the human preference-guided aggregator is efficient to train and more explainable than relying solely on prompting, and its independence from model parameters makes it applicable to closed-source LLMs. Extensive experiments on three evaluation domains demonstrate the superiority of HD-Eval in further aligning state-of-the-art evaluators and providing deeper insights into the explanation of evaluation results and the task itself.
Text Diffusion with Reinforced Conditioning
Feb 19, 2024Diffusion models have demonstrated exceptional capability in generating high-quality images, videos, and audio. Due to their adaptiveness in iterative refinement, they provide a strong potential for achieving better non-autoregressive sequence generation. However, existing text diffusion models still fall short in their performance due to a challenge in handling the discreteness of language. This paper thoroughly analyzes text diffusion models and uncovers two significant limitations: degradation of self-conditioning during training and misalignment between training and sampling. Motivated by our findings, we propose a novel Text Diffusion model called TREC, which mitigates the degradation with Reinforced Conditioning and the misalignment by Time-Aware Variance Scaling. Our extensive experiments demonstrate the competitiveness of TREC against autoregressive, non-autoregressive, and diffusion baselines. Moreover, qualitative analysis shows its advanced ability to fully utilize the diffusion process in refining samples.
Disentangle Estimation of Causal Effects from Cross-Silo Data
Jan 04, 2024Estimating causal effects among different events is of great importance to critical fields such as drug development. Nevertheless, the data features associated with events may be distributed across various silos and remain private within respective parties, impeding direct information exchange between them. This, in turn, can result in biased estimations of local causal effects, which rely on the characteristics of only a subset of the covariates. To tackle this challenge, we introduce an innovative disentangle architecture designed to facilitate the seamless cross-silo transmission of model parameters, enriched with causal mechanisms, through a combination of shared and private branches. Besides, we introduce global constraints into the equation to effectively mitigate bias within the various missing domains, thereby elevating the accuracy of our causal effect estimation. Extensive experiments conducted on new semi-synthetic datasets show that our method outperforms state-of-the-art baselines.