 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWenchao Xu
Disentangle Estimation of Causal Effects from Cross-Silo Data
Jan 04, 2024
Estimating causal effects among different events is of great importance to critical fields such as drug development. Nevertheless, the data features associated with events may be distributed across various silos and remain private within respective parties, impeding direct information exchange between them. This, in turn, can result in biased estimations of local causal effects, which rely on the characteristics of only a subset of the covariates. To tackle this challenge, we introduce an innovative disentangle architecture designed to facilitate the seamless cross-silo transmission of model parameters, enriched with causal mechanisms, through a combination of shared and private branches. Besides, we introduce global constraints into the equation to effectively mitigate bias within the various missing domains, thereby elevating the accuracy of our causal effect estimation. Extensive experiments conducted on new semi-synthetic datasets show that our method outperforms state-of-the-art baselines.
Balanced Multi-modal Federated Learning via Cross-Modal Infiltration
Dec 31, 2023Federated learning (FL) underpins advancements in privacy-preserving distributed computing by collaboratively training neural networks without exposing clients' raw data. Current FL paradigms primarily focus on uni-modal data, while exploiting the knowledge from distributed multimodal data remains largely unexplored. Existing multimodal FL (MFL) solutions are mainly designed for statistical or modality heterogeneity from the input side, however, have yet to solve the fundamental issue,"modality imbalance", in distributed conditions, which can lead to inadequate information exploitation and heterogeneous knowledge aggregation on different modalities.In this paper, we propose a novel Cross-Modal Infiltration Federated Learning (FedCMI) framework that effectively alleviates modality imbalance and knowledge heterogeneity via knowledge transfer from the global dominant modality. To avoid the loss of information in the weak modality due to merely imitating the behavior of dominant modality, we design the two-projector module to integrate the knowledge from dominant modality while still promoting the local feature exploitation of weak modality. In addition, we introduce a class-wise temperature adaptation scheme to achieve fair performance across different classes. Extensive experiments over popular datasets are conducted and give us a gratifying confirmation of the proposed framework for fully exploring the information of each modality in MFL.
Client-wise Modality Selection for Balanced Multi-modal Federated Learning
Dec 31, 2023Selecting proper clients to participate in the iterative federated learning (FL) rounds is critical to effectively harness a broad range of distributed datasets. Existing client selection methods simply consider the variability among FL clients with uni-modal data, however, have yet to consider clients with multi-modalities. We reveal that traditional client selection scheme in MFL may suffer from a severe modality-level bias, which impedes the collaborative exploitation of multi-modal data, leading to insufficient local data exploration and global aggregation. To tackle this challenge, we propose a Client-wise Modality Selection scheme for MFL (CMSFed) that can comprehensively utilize information from each modality via avoiding such client selection bias caused by modality imbalance. Specifically, in each MFL round, the local data from different modalities are selectively employed to participate in local training and aggregation to mitigate potential modality imbalance of the global model. To approximate the fully aggregated model update in a balanced way, we introduce a novel local training loss function to enhance the weak modality and align the divergent feature spaces caused by inconsistent modality adoption strategies for different clients simultaneously. Then, a modality-level gradient decoupling method is designed to derive respective submodular functions to maintain the gradient diversity during the selection progress and balance MFL according to local modality imbalance in each iteration. Our extensive experiments showcase the superiority of CMSFed over baselines and its effectiveness in multi-modal data exploitation.
Mobility and Cost Aware Inference Accelerating Algorithm for Edge Intelligence
Dec 27, 2023The edge intelligence (EI) has been widely applied recently. Spliting the model between device, edge server, and cloud can improve the performance of EI greatly. The model segmentation without user mobility has been investigated deeply by previous works. However, in most use cases of EI, the end devices are mobile. Only a few works have been carried out on this aspect. These works still have many issues, such as ignoring the energy consumption of mobile device, inappropriate network assumption, and low effectiveness on adaptiving user mobility, etc. Therefore, for addressing the disadvantages of model segmentation and resource allocation in previous works, we propose mobility and cost aware model segmentation and resource allocation algorithm for accelerating the inference at edge (MCSA). Specfically, in the scenario without user mobility, the loop interation gradient descent (Li-GD) algorithm is provided. When the mobile user has a large model inference task needs to be calculated, it will take the energy consumption of mobile user, the communication and computing resource renting cost, and the inference delay into account to find the optimal model segmentation and resource allocation strategy. In the scenario with user mobility, the mobiity aware Li-GD (MLi-GD) algorithm is proposed to calculate the optimal strategy. Then, the properties of the proposed algorithms are investigated, including convergence, complexity, and approximation ratio. The experimental results demonstrate the effectiveness of the proposed algorithms.
MDENet: Multi-modal Dual-embedding Networks for Malware Open-set Recognition
May 02, 2023
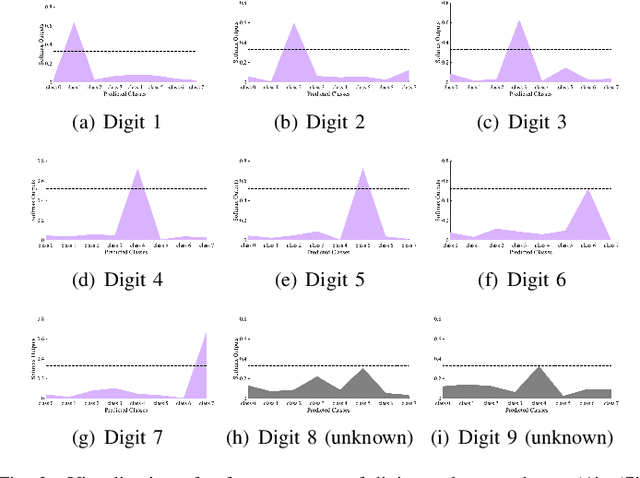
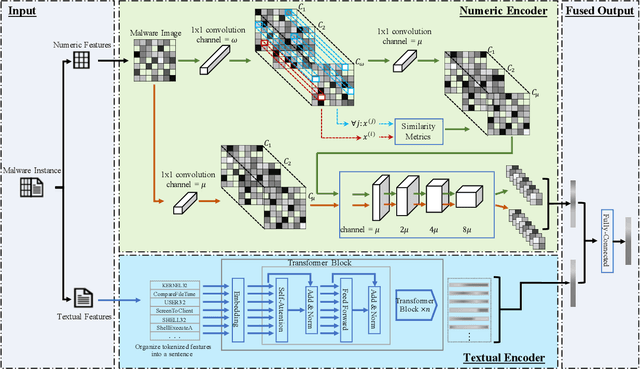
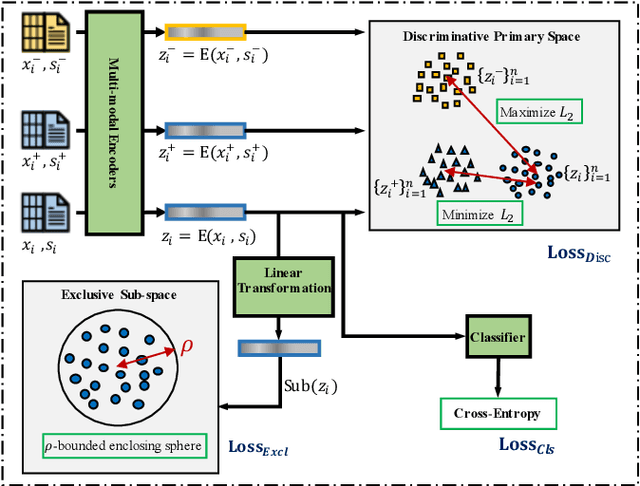
Malware open-set recognition (MOSR) aims at jointly classifying malware samples from known families and detect the ones from novel unknown families, respectively. Existing works mostly rely on a well-trained classifier considering the predicted probabilities of each known family with a threshold-based detection to achieve the MOSR. However, our observation reveals that the feature distributions of malware samples are extremely similar to each other even between known and unknown families. Thus the obtained classifier may produce overly high probabilities of testing unknown samples toward known families and degrade the model performance. In this paper, we propose the Multi-modal Dual-Embedding Networks, dubbed MDENet, to take advantage of comprehensive malware features (i.e., malware images and malware sentences) from different modalities to enhance the diversity of malware feature space, which is more representative and discriminative for down-stream recognition. Last, to further guarantee the open-set recognition, we dually embed the fused multi-modal representation into one primary space and an associated sub-space, i.e., discriminative and exclusive spaces, with contrastive sampling and rho-bounded enclosing sphere regularizations, which resort to classification and detection, respectively. Moreover, we also enrich our previously proposed large-scaled malware dataset MAL-100 with multi-modal characteristics and contribute an improved version dubbed MAL-100+. Experimental results on the widely used malware dataset Mailing and the proposed MAL-100+ demonstrate the effectiveness of our method.
Towards Unbiased Training in Federated Open-world Semi-supervised Learning
May 01, 2023



Federated Semi-supervised Learning (FedSSL) has emerged as a new paradigm for allowing distributed clients to collaboratively train a machine learning model over scarce labeled data and abundant unlabeled data. However, existing works for FedSSL rely on a closed-world assumption that all local training data and global testing data are from seen classes observed in the labeled dataset. It is crucial to go one step further: adapting FL models to an open-world setting, where unseen classes exist in the unlabeled data. In this paper, we propose a novel Federatedopen-world Semi-Supervised Learning (FedoSSL) framework, which can solve the key challenge in distributed and open-world settings, i.e., the biased training process for heterogeneously distributed unseen classes. Specifically, since the advent of a certain unseen class depends on a client basis, the locally unseen classes (exist in multiple clients) are likely to receive differentiated superior aggregation effects than the globally unseen classes (exist only in one client). We adopt an uncertainty-aware suppressed loss to alleviate the biased training between locally unseen and globally unseen classes. Besides, we enable a calibration module supplementary to the global aggregation to avoid potential conflicting knowledge transfer caused by inconsistent data distribution among different clients. The proposed FedoSSL can be easily adapted to state-of-the-art FL methods, which is also validated via extensive experiments on benchmarks and real-world datasets (CIFAR-10, CIFAR-100 and CINIC-10).
* 12 pages
Offline-Online Class-incremental Continual Learning via Dual-prototype Self-augment and Refinement
Mar 20, 2023



This paper investigates a new, practical, but challenging problem named Offline-Online Class-incremental Continual Learning (O$^2$CL), which aims to preserve the discernibility of pre-trained (i.e., offline) base classes without buffering data examples, and efficiently learn novel classes continuously in a single-pass (i.e., online) data stream. The challenges of this task are mainly two-fold: 1) Both base and novel classes suffer from severe catastrophic forgetting as no previous samples are available for replay. 2) As the online data can only be observed once, there is no way to fully re-train the whole model, e.g., re-calibrate the decision boundaries via prototype alignment or feature distillation. In this paper, we propose a novel Dual-prototype Self-augment and Refinement method (DSR) for O$^2$CL problem, which consists of two strategies: 1) Dual class prototypes: Inner and hyper-dimensional prototypes are exploited to utilize the pre-trained information and obtain robust quasi-orthogonal representations rather than example buffers for both privacy preservation and memory reduction. 2) Self-augment and refinement: Instead of updating the whole network, we jointly optimize the extra projection module with the self-augment inner prototypes from base and novel classes, gradually refining the hyper-dimensional prototypes to obtain accurate decision boundaries for learned classes. Extensive experiments demonstrate the effectiveness and superiority of the proposed DSR in O$^2$CL.
DualMix: Unleashing the Potential of Data Augmentation for Online Class-Incremental Learning
Mar 14, 2023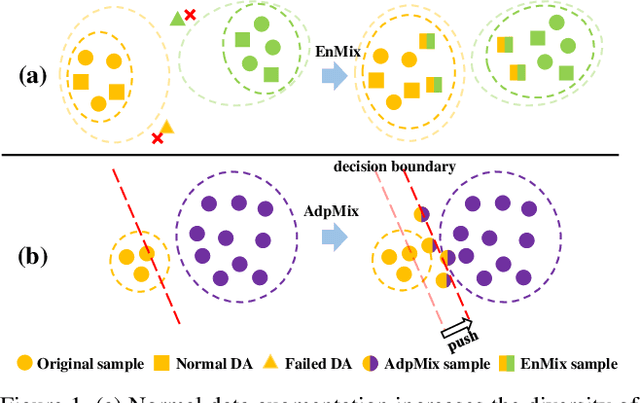
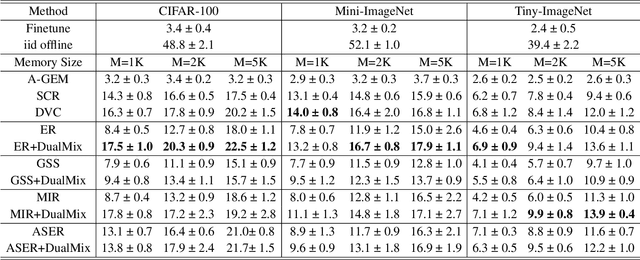
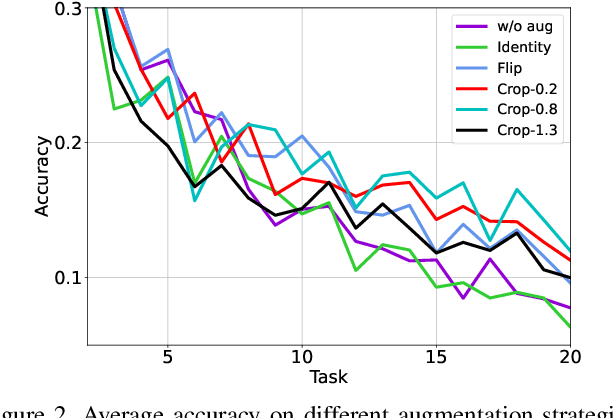

Online Class-Incremental (OCI) learning has sparked new approaches to expand the previously trained model knowledge from sequentially arriving data streams with new classes. Unfortunately, OCI learning can suffer from catastrophic forgetting (CF) as the decision boundaries for old classes can become inaccurate when perturbated by new ones. Existing literature have applied the data augmentation (DA) to alleviate the model forgetting, while the role of DA in OCI has not been well understood so far. In this paper, we theoretically show that augmented samples with lower correlation to the original data are more effective in preventing forgetting. However, aggressive augmentation may also reduce the consistency between data and corresponding labels, which motivates us to exploit proper DA to boost the OCI performance and prevent the CF problem. We propose the Enhanced Mixup (EnMix) method that mixes the augmented samples and their labels simultaneously, which is shown to enhance the sample diversity while maintaining strong consistency with corresponding labels. Further, to solve the class imbalance problem, we design an Adaptive Mixup (AdpMix) method to calibrate the decision boundaries by mixing samples from both old and new classes and dynamically adjusting the label mixing ratio. Our approach is demonstrated to be effective on several benchmark datasets through extensive experiments, and it is shown to be compatible with other replay-based techniques.
RMMDet: Road-Side Multitype and Multigroup Sensor Detection System for Autonomous Driving
Mar 10, 2023

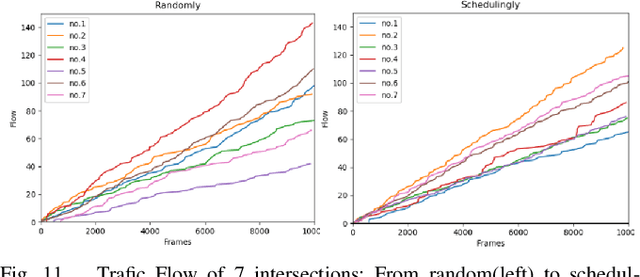
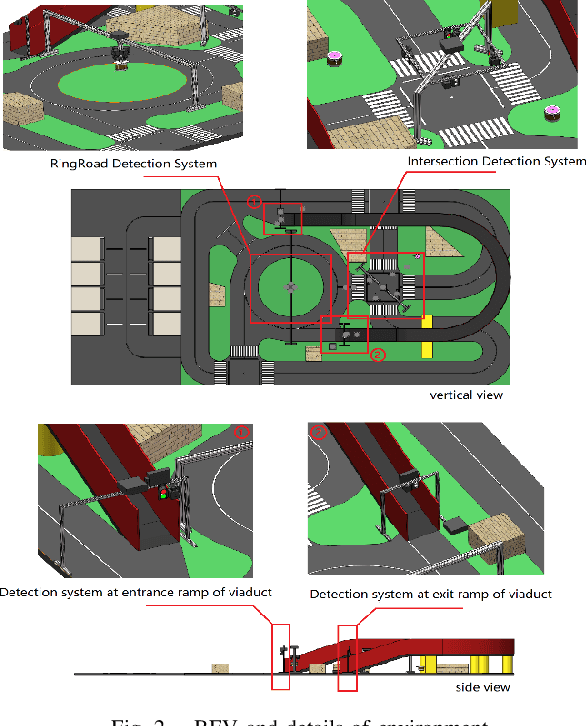
Autonomous driving has now made great strides thanks to artificial intelligence, and numerous advanced methods have been proposed for vehicle end target detection, including single sensor or multi sensor detection methods. However, the complexity and diversity of real traffic situations necessitate an examination of how to use these methods in real road conditions. In this paper, we propose RMMDet, a road-side multitype and multigroup sensor detection system for autonomous driving. We use a ROS-based virtual environment to simulate real-world conditions, in particular the physical and functional construction of the sensors. Then we implement muti-type sensor detection and multi-group sensors fusion in this environment, including camera-radar and camera-lidar detection based on result-level fusion. We produce local datasets and real sand table field, and conduct various experiments. Furthermore, we link a multi-agent collaborative scheduling system to the fusion detection system. Hence, the whole roadside detection system is formed by roadside perception, fusion detection, and scheduling planning. Through the experiments, it can be seen that RMMDet system we built plays an important role in vehicle-road collaboration and its optimization. The code and supplementary materials can be found at: https://github.com/OrangeSodahub/RMMDet
AirCon: Over-the-Air Consensus for Wireless Blockchain Networks
Nov 30, 2022



Blockchain has been deemed as a promising solution for providing security and privacy protection in the next-generation wireless networks. Large-scale concurrent access for massive wireless devices to accomplish the consensus procedure may consume prohibitive communication and computing resources, and thus may limit the application of blockchain in wireless conditions. As most existing consensus protocols are designed for wired networks, directly apply them for wireless users may exhaust their scarce spectrum and computing resources. In this paper, we propose AirCon, a byzantine fault-tolerant (BFT) consensus protocol for wireless users via the over-the-air computation. The novelty of AirCon is to take advantage of the intrinsic characteristic of the wireless channel and automatically achieve the consensus in the physical layer while receiving from the end users, which greatly reduces the communication and computational cost that would be caused by traditional consensus protocols. We implement the AirCon protocol integrated into an LTE system and provide solutions to the critical issues for over-the-air consensus implementation. Experimental results are provided to show the feasibility of the proposed protocol, and simulation results to show the performance of the AirCon protocol under different wireless conditions.