 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFulong Ma
Dragtraffic: A Non-Expert Interactive and Point-Based Controllable Traffic Scene Generation Framework
Apr 19, 2024
The evaluation and training of autonomous driving systems require diverse and scalable corner cases. However, most existing scene generation methods lack controllability, accuracy, and versatility, resulting in unsatisfactory generation results. To address this problem, we propose Dragtraffic, a generalized, point-based, and controllable traffic scene generation framework based on conditional diffusion. Dragtraffic enables non-experts to generate a variety of realistic driving scenarios for different types of traffic agents through an adaptive mixture expert architecture. We use a regression model to provide a general initial solution and a refinement process based on the conditional diffusion model to ensure diversity. User-customized context is introduced through cross-attention to ensure high controllability. Experiments on a real-world driving dataset show that Dragtraffic outperforms existing methods in terms of authenticity, diversity, and freedom.
Monocular 3D lane detection for Autonomous Driving: Recent Achievements, Challenges, and Outlooks
Apr 10, 20243D lane detection plays a crucial role in autonomous driving by extracting structural and traffic information from the road in 3D space to assist the self-driving car in rational, safe, and comfortable path planning and motion control. Due to the consideration of sensor costs and the advantages of visual data in color information, in practical applications, 3D lane detection based on monocular vision is one of the important research directions in the field of autonomous driving, which has attracted more and more attention in both industry and academia. Unfortunately, recent progress in visual perception seems insufficient to develop completely reliable 3D lane detection algorithms, which also hinders the development of vision-based fully autonomous self-driving cars, i.e., achieving level 5 autonomous driving, driving like human-controlled cars. This is one of the conclusions drawn from this review paper: there is still a lot of room for improvement and significant improvements are still needed in the 3D lane detection algorithm for autonomous driving cars using visual sensors. Motivated by this, this review defines, analyzes, and reviews the current achievements in the field of 3D lane detection research, and the vast majority of the current progress relies heavily on computationally complex deep learning models. In addition, this review covers the 3D lane detection pipeline, investigates the performance of state-of-the-art algorithms, analyzes the time complexity of cutting-edge modeling choices, and highlights the main achievements and limitations of current research efforts. The survey also includes a comprehensive discussion of available 3D lane detection datasets and the challenges that researchers have faced but have not yet resolved. Finally, our work outlines future research directions and welcomes researchers and practitioners to enter this exciting field.
CurbNet: Curb Detection Framework Based on LiDAR Point Cloud Segmentation
Mar 25, 2024Curb detection is an important function in intelligent driving and can be used to determine drivable areas of the road. However, curbs are difficult to detect due to the complex road environment. This paper introduces CurbNet, a novel framework for curb detection, leveraging point cloud segmentation. Addressing the dearth of comprehensive curb datasets and the absence of 3D annotations, we have developed the 3D-Curb dataset, encompassing 7,100 frames, which represents the largest and most categorically diverse collection of curb point clouds currently available. Recognizing that curbs are primarily characterized by height variations, our approach harnesses spatially-rich 3D point clouds for training. To tackle the challenges presented by the uneven distribution of curb features on the xy-plane and their reliance on z-axis high-frequency features, we introduce the multi-scale and channel attention (MSCA) module, a bespoke solution designed to optimize detection performance. Moreover, we propose an adaptive weighted loss function group, specifically formulated to counteract the imbalance in the distribution of curb point clouds relative to other categories. Our extensive experimentation on 2 major datasets has yielded results that surpass existing benchmarks set by leading curb detection and point cloud segmentation models. By integrating multi-clustering and curve fitting techniques in our post-processing stage, we have substantially reduced noise in curb detection, thereby enhancing precision to 0.8744. Notably, CurbNet has achieved an exceptional average metrics of over 0.95 at a tolerance of just 0.15m, thereby establishing a new benchmark. Furthermore, corroborative real-world experiments and dataset analyzes mutually validate each other, solidifying CurbNet's superior detection proficiency and its robust generalizability.
Every Dataset Counts: Scaling up Monocular 3D Object Detection with Joint Datasets Training
Oct 02, 2023



Monocular 3D object detection plays a crucial role in autonomous driving. However, existing monocular 3D detection algorithms depend on 3D labels derived from LiDAR measurements, which are costly to acquire for new datasets and challenging to deploy in novel environments. Specifically, this study investigates the pipeline for training a monocular 3D object detection model on a diverse collection of 3D and 2D datasets. The proposed framework comprises three components: (1) a robust monocular 3D model capable of functioning across various camera settings, (2) a selective-training strategy to accommodate datasets with differing class annotations, and (3) a pseudo 3D training approach using 2D labels to enhance detection performance in scenes containing only 2D labels. With this framework, we could train models on a joint set of various open 3D/2D datasets to obtain models with significantly stronger generalization capability and enhanced performance on new dataset with only 2D labels. We conduct extensive experiments on KITTI/nuScenes/ONCE/Cityscapes/BDD100K datasets to demonstrate the scaling ability of the proposed method.
Hercules: An Autonomous Logistic Vehicle for Contact-less Goods Transportation During the COVID-19 Outbreak
Apr 16, 2020
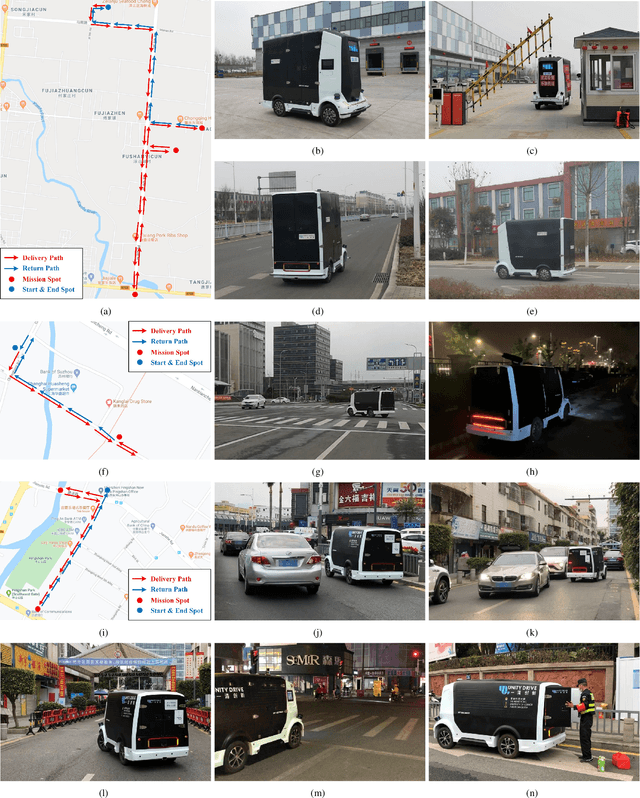
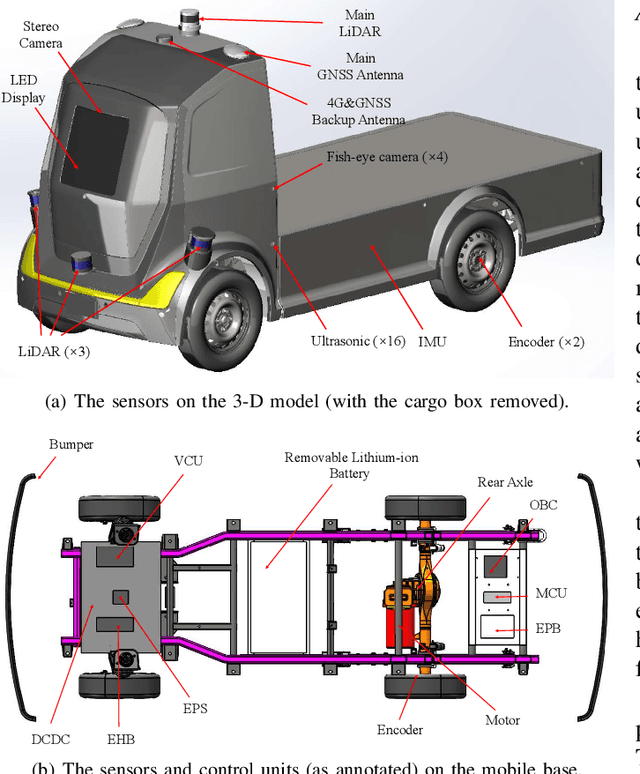
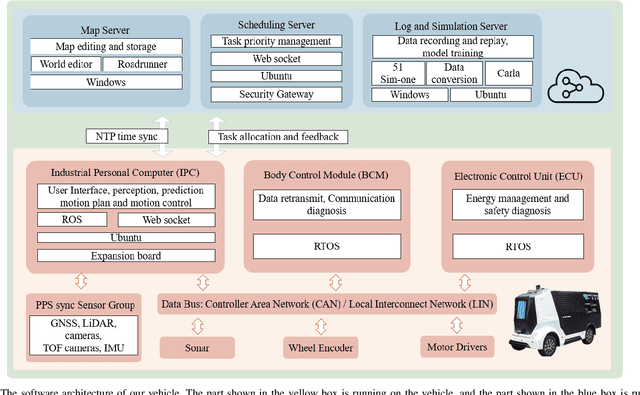
Since December 2019, the coronavirus disease 2019 (COVID-19) has spread rapidly across China. As at the date of writing this article, the disease has been globally reported in 100 countries, infected over 100,000 people and caused over 3,000 deaths. Avoiding person-to-person transmission is an effective approach to control and prevent the epidemic. However, many daily activities, such as logistics transporting goods in our daily life, inevitably involve person-to-person contact. To achieve contact-less goods transportation, using an autonomous logistic vehicle has become the preferred choice. This article presents Hercules, an autonomous logistic vehicle used for contact-less goods transportation during the outbreak of COVID-19. The vehicle is designed with autonomous navigation capability. We provide details on the hardware and software, as well as the algorithms to achieve autonomous navigation including perception, planning and control. This paper is accompanied by a demonstration video and a dataset, which are available here: https://sites.google.com/view/contact-less-transportation.
Road Crack Detection Using Deep Convolutional Neural Network and Adaptive Thresholding
Apr 18, 2019



Crack is one of the most common road distresses which may pose road safety hazards. Generally, crack detection is performed by either certified inspectors or structural engineers. This task is, however, time-consuming, subjective and labor-intensive. In this paper, we propose a novel road crack detection algorithm based on deep learning and adaptive image segmentation. Firstly, a deep convolutional neural network is trained to determine whether an image contains cracks or not. The images containing cracks are then smoothed using bilateral filtering, which greatly minimizes the number of noisy pixels. Finally, we utilize an adaptive thresholding method to extract the cracks from road surface. The experimental results illustrate that our network can classify images with an accuracy of 99.92%, and the cracks can be successfully extracted from the images using our proposed thresholding algorithm.