 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKonrad Schindler
I-Design: Personalized LLM Interior Designer
Apr 03, 2024
Interior design allows us to be who we are and live how we want - each design is as unique as our distinct personality. However, it is not trivial for non-professionals to express and materialize this since it requires aligning functional and visual expectations with the constraints of physical space; this renders interior design a luxury. To make it more accessible, we present I-Design, a personalized interior designer that allows users to generate and visualize their design goals through natural language communication. I-Design starts with a team of large language model agents that engage in dialogues and logical reasoning with one another, transforming textual user input into feasible scene graph designs with relative object relationships. Subsequently, an effective placement algorithm determines optimal locations for each object within the scene. The final design is then constructed in 3D by retrieving and integrating assets from an existing object database. Additionally, we propose a new evaluation protocol that utilizes a vision-language model and complements the design pipeline. Extensive quantitative and qualitative experiments show that I-Design outperforms existing methods in delivering high-quality 3D design solutions and aligning with abstract concepts that match user input, showcasing its advantages across detailed 3D arrangement and conceptual fidelity.
StegoGAN: Leveraging Steganography for Non-Bijective Image-to-Image Translation
Mar 29, 2024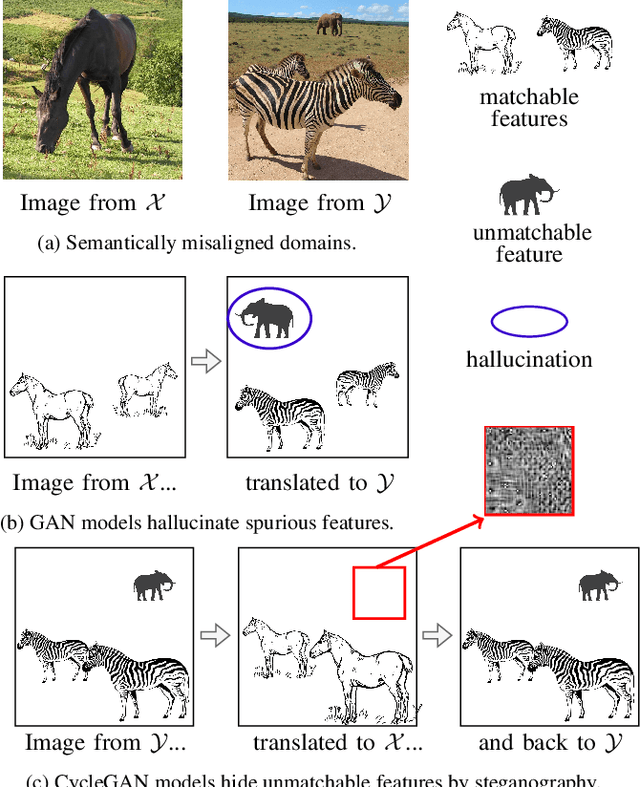
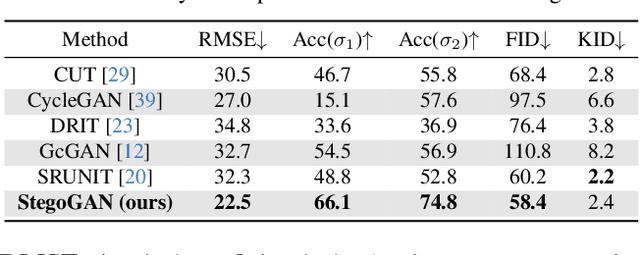
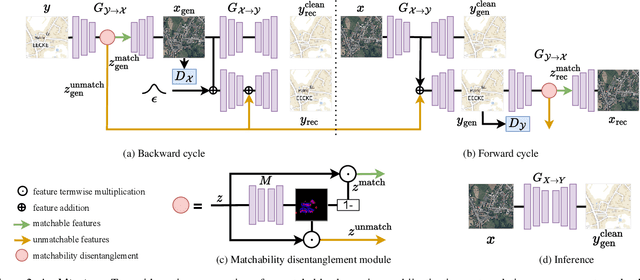
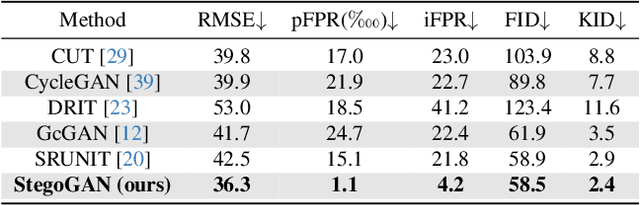
Most image-to-image translation models postulate that a unique correspondence exists between the semantic classes of the source and target domains. However, this assumption does not always hold in real-world scenarios due to divergent distributions, different class sets, and asymmetrical information representation. As conventional GANs attempt to generate images that match the distribution of the target domain, they may hallucinate spurious instances of classes absent from the source domain, thereby diminishing the usefulness and reliability of translated images. CycleGAN-based methods are also known to hide the mismatched information in the generated images to bypass cycle consistency objectives, a process known as steganography. In response to the challenge of non-bijective image translation, we introduce StegoGAN, a novel model that leverages steganography to prevent spurious features in generated images. Our approach enhances the semantic consistency of the translated images without requiring additional postprocessing or supervision. Our experimental evaluations demonstrate that StegoGAN outperforms existing GAN-based models across various non-bijective image-to-image translation tasks, both qualitatively and quantitatively. Our code and pretrained models are accessible at https://github.com/sian-wusidi/StegoGAN.
Point2Building: Reconstructing Buildings from Airborne LiDAR Point Clouds
Mar 04, 2024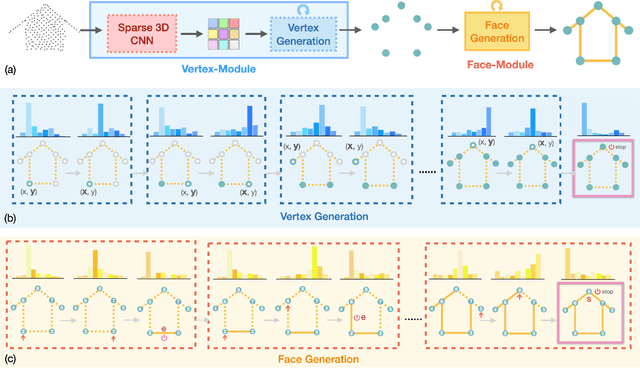
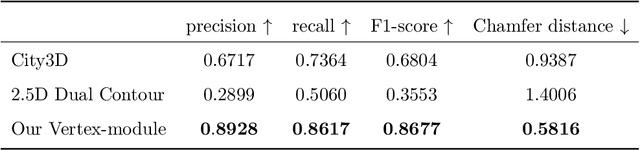
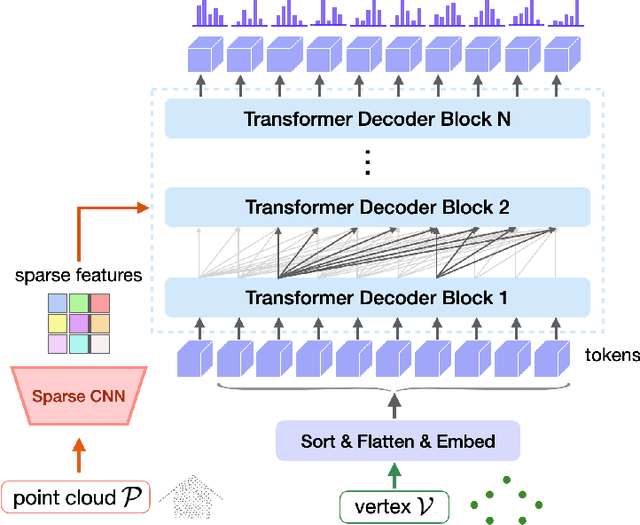

We present a learning-based approach to reconstruct buildings as 3D polygonal meshes from airborne LiDAR point clouds. What makes 3D building reconstruction from airborne LiDAR hard is the large diversity of building designs and especially roof shapes, the low and varying point density across the scene, and the often incomplete coverage of building facades due to occlusions by vegetation or to the viewing angle of the sensor. To cope with the diversity of shapes and inhomogeneous and incomplete object coverage, we introduce a generative model that directly predicts 3D polygonal meshes from input point clouds. Our autoregressive model, called Point2Building, iteratively builds up the mesh by generating sequences of vertices and faces. This approach enables our model to adapt flexibly to diverse geometries and building structures. Unlike many existing methods that rely heavily on pre-processing steps like exhaustive plane detection, our model learns directly from the point cloud data, thereby reducing error propagation and increasing the fidelity of the reconstruction. We experimentally validate our method on a collection of airborne LiDAR data of Zurich, Berlin and Tallinn. Our method shows good generalization to diverse urban styles.
Is Continual Learning Ready for Real-world Challenges?
Feb 15, 2024Despite continual learning's long and well-established academic history, its application in real-world scenarios remains rather limited. This paper contends that this gap is attributable to a misalignment between the actual challenges of continual learning and the evaluation protocols in use, rendering proposed solutions ineffective for addressing the complexities of real-world setups. We validate our hypothesis and assess progress to date, using a new 3D semantic segmentation benchmark, OCL-3DSS. We investigate various continual learning schemes from the literature by utilizing more realistic protocols that necessitate online and continual learning for dynamic, real-world scenarios (eg., in robotics and 3D vision applications). The outcomes are sobering: all considered methods perform poorly, significantly deviating from the upper bound of joint offline training. This raises questions about the applicability of existing methods in realistic settings. Our paper aims to initiate a paradigm shift, advocating for the adoption of continual learning methods through new experimental protocols that better emulate real-world conditions to facilitate breakthroughs in the field.
SegmentAnyTree: A sensor and platform agnostic deep learning model for tree segmentation using laser scanning data
Jan 28, 2024This research advances individual tree crown (ITC) segmentation in lidar data, using a deep learning model applicable to various laser scanning types: airborne (ULS), terrestrial (TLS), and mobile (MLS). It addresses the challenge of transferability across different data characteristics in 3D forest scene analysis. The study evaluates the model's performance based on platform (ULS, MLS) and data density, testing five scenarios with varying input data, including sparse versions, to gauge adaptability and canopy layer efficacy. The model, based on PointGroup architecture, is a 3D CNN with separate heads for semantic and instance segmentation, validated on diverse point cloud datasets. Results show point cloud sparsification enhances performance, aiding sparse data handling and improving detection in dense forests. The model performs well with >50 points per sq. m densities but less so at 10 points per sq. m due to higher omission rates. It outperforms existing methods (e.g., Point2Tree, TLS2trees) in detection, omission, commission rates, and F1 score, setting new benchmarks on LAUTx, Wytham Woods, and TreeLearn datasets. In conclusion, this study shows the feasibility of a sensor-agnostic model for diverse lidar data, surpassing sensor-specific approaches and setting new standards in tree segmentation, particularly in complex forests. This contributes to future ecological modeling and forest management advancements.
Automated forest inventory: analysis of high-density airborne LiDAR point clouds with 3D deep learning
Dec 22, 2023Detailed forest inventories are critical for sustainable and flexible management of forest resources, to conserve various ecosystem services. Modern airborne laser scanners deliver high-density point clouds with great potential for fine-scale forest inventory and analysis, but automatically partitioning those point clouds into meaningful entities like individual trees or tree components remains a challenge. The present study aims to fill this gap and introduces a deep learning framework that is able to perform such a segmentation across diverse forest types and geographic regions. From the segmented data, we then derive relevant biophysical parameters of individual trees as well as stands. The system has been tested on FOR-Instance, a dataset of point clouds that have been acquired in five different countries using surveying drones. The segmentation back-end achieves over 85% F-score for individual trees, respectively over 73% mean IoU across five semantic categories: ground, low vegetation, stems, live branches and dead branches. Building on the segmentation results our pipeline then densely calculates biophysical features of each individual tree (height, crown diameter, crown volume, DBH, and location) and properties per stand (digital terrain model and stand density). Especially crown-related features are in most cases retrieved with high accuracy, whereas the estimates for DBH and location are less reliable, due to the airborne scanning setup.
Living Scenes: Multi-object Relocalization and Reconstruction in Changing 3D Environments
Dec 14, 2023Research into dynamic 3D scene understanding has primarily focused on short-term change tracking from dense observations, while little attention has been paid to long-term changes with sparse observations. We address this gap with MoRE, a novel approach for multi-object relocalization and reconstruction in evolving environments. We view these environments as "living scenes" and consider the problem of transforming scans taken at different points in time into a 3D reconstruction of the object instances, whose accuracy and completeness increase over time. At the core of our method lies an SE(3)-equivariant representation in a single encoder-decoder network, trained on synthetic data. This representation enables us to seamlessly tackle instance matching, registration, and reconstruction. We also introduce a joint optimization algorithm that facilitates the accumulation of point clouds originating from the same instance across multiple scans taken at different points in time. We validate our method on synthetic and real-world data and demonstrate state-of-the-art performance in both end-to-end performance and individual subtasks.
Dynamic LiDAR Re-simulation using Compositional Neural Fields
Dec 08, 2023We introduce DyNFL, a novel neural field-based approach for high-fidelity re-simulation of LiDAR scans in dynamic driving scenes. DyNFL processes LiDAR measurements from dynamic environments, accompanied by bounding boxes of moving objects, to construct an editable neural field. This field, comprising separately reconstructed static backgrounds and dynamic objects, allows users to modify viewpoints, adjust object positions, and seamlessly add or remove objects in the re-simulated scene. A key innovation of our method is the neural field composition technique, which effectively integrates reconstructed neural assets from various scenes through a ray drop test, accounting for occlusions and transparent surfaces. Our evaluation with both synthetic and real-world environments demonstrates that \ShortName substantial improves dynamic scene simulation based on LiDAR scans, offering a combination of physical fidelity and flexible editing capabilities.
Point2CAD: Reverse Engineering CAD Models from 3D Point Clouds
Dec 07, 2023Computer-Aided Design (CAD) model reconstruction from point clouds is an important problem at the intersection of computer vision, graphics, and machine learning; it saves the designer significant time when iterating on in-the-wild objects. Recent advancements in this direction achieve relatively reliable semantic segmentation but still struggle to produce an adequate topology of the CAD model. In this work, we analyze the current state of the art for that ill-posed task and identify shortcomings of existing methods. We propose a hybrid analytic-neural reconstruction scheme that bridges the gap between segmented point clouds and structured CAD models and can be readily combined with different segmentation backbones. Moreover, to power the surface fitting stage, we propose a novel implicit neural representation of freeform surfaces, driving up the performance of our overall CAD reconstruction scheme. We extensively evaluate our method on the popular ABC benchmark of CAD models and set a new state-of-the-art for that dataset. Project page: https://www.obukhov.ai/point2cad}{https://www.obukhov.ai/point2cad.
DGInStyle: Domain-Generalizable Semantic Segmentation with Image Diffusion Models and Stylized Semantic Control
Dec 05, 2023Large, pretrained latent diffusion models (LDMs) have demonstrated an extraordinary ability to generate creative content, specialize to user data through few-shot fine-tuning, and condition their output on other modalities, such as semantic maps. However, are they usable as large-scale data generators, e.g., to improve tasks in the perception stack, like semantic segmentation? We investigate this question in the context of autonomous driving, and answer it with a resounding "yes". We propose an efficient data generation pipeline termed DGInStyle. First, we examine the problem of specializing a pretrained LDM to semantically-controlled generation within a narrow domain. Second, we design a Multi-resolution Latent Fusion technique to overcome the bias of LDMs towards dominant objects. Third, we propose a Style Swap technique to endow the rich generative prior with the learned semantic control. Using DGInStyle, we generate a diverse dataset of street scenes, train a domain-agnostic semantic segmentation model on it, and evaluate the model on multiple popular autonomous driving datasets. Our approach consistently increases the performance of several domain generalization methods, in some cases by +2.5 mIoU compared to the previous state-of-the-art method without our generative augmentation scheme. Source code and dataset are available at https://dginstyle.github.io .