 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSidi Wu
StegoGAN: Leveraging Steganography for Non-Bijective Image-to-Image Translation
Mar 29, 2024
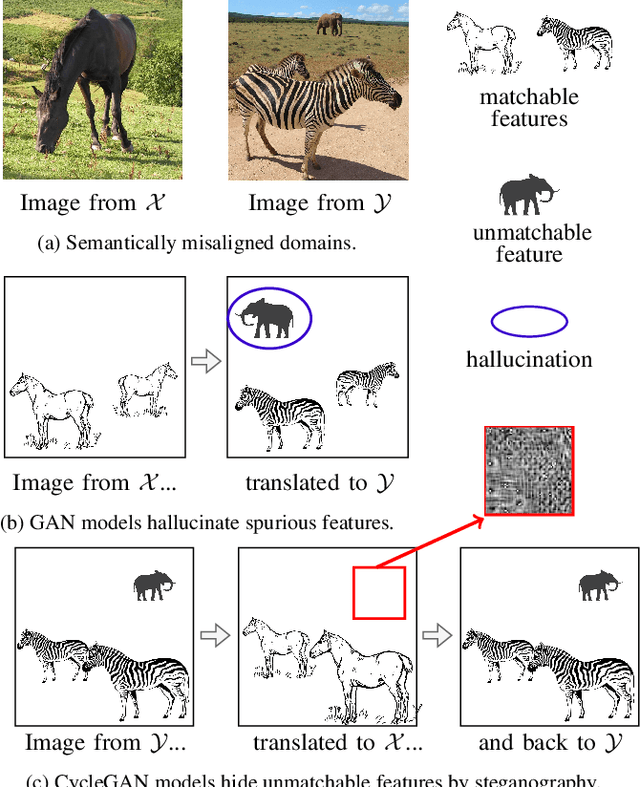
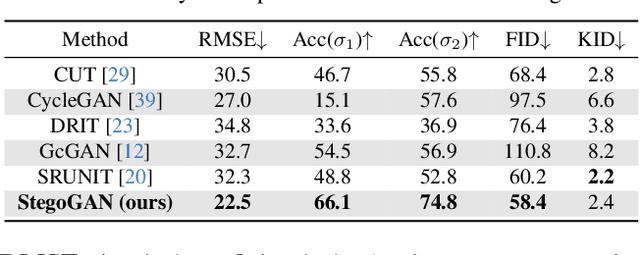
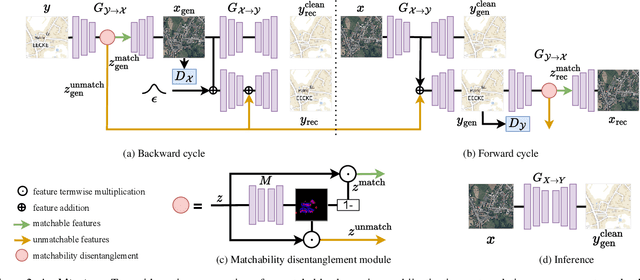
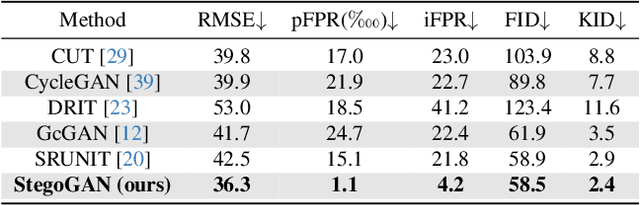
Most image-to-image translation models postulate that a unique correspondence exists between the semantic classes of the source and target domains. However, this assumption does not always hold in real-world scenarios due to divergent distributions, different class sets, and asymmetrical information representation. As conventional GANs attempt to generate images that match the distribution of the target domain, they may hallucinate spurious instances of classes absent from the source domain, thereby diminishing the usefulness and reliability of translated images. CycleGAN-based methods are also known to hide the mismatched information in the generated images to bypass cycle consistency objectives, a process known as steganography. In response to the challenge of non-bijective image translation, we introduce StegoGAN, a novel model that leverages steganography to prevent spurious features in generated images. Our approach enhances the semantic consistency of the translated images without requiring additional postprocessing or supervision. Our experimental evaluations demonstrate that StegoGAN outperforms existing GAN-based models across various non-bijective image-to-image translation tasks, both qualitatively and quantitatively. Our code and pretrained models are accessible at https://github.com/sian-wusidi/StegoGAN.
A Physics-driven GraphSAGE Method for Physical Process Simulations Described by Partial Differential Equations
Mar 13, 2024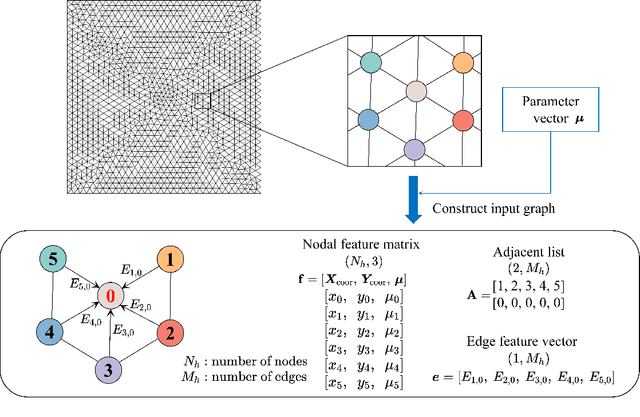
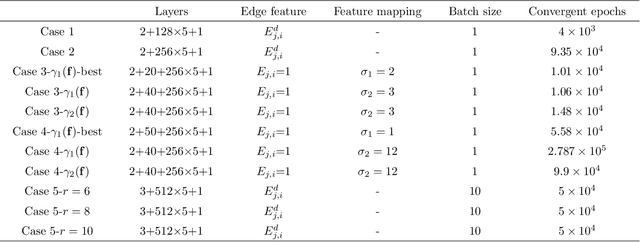
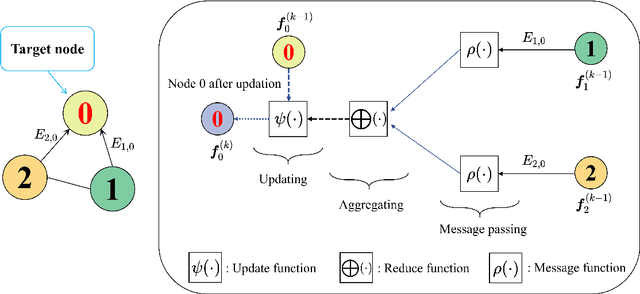

Physics-informed neural networks (PINNs) have successfully addressed various computational physics problems based on partial differential equations (PDEs). However, while tackling issues related to irregularities like singularities and oscillations, trained solutions usually suffer low accuracy. In addition, most current works only offer the trained solution for predetermined input parameters. If any change occurs in input parameters, transfer learning or retraining is required, and traditional numerical techniques also need an independent simulation. In this work, a physics-driven GraphSAGE approach (PD-GraphSAGE) based on the Galerkin method and piecewise polynomial nodal basis functions is presented to solve computational problems governed by irregular PDEs and to develop parametric PDE surrogate models. This approach employs graph representations of physical domains, thereby reducing the demands for evaluated points due to local refinement. A distance-related edge feature and a feature mapping strategy are devised to help training and convergence for singularity and oscillation situations, respectively. The merits of the proposed method are demonstrated through a couple of cases. Moreover, the robust PDE surrogate model for heat conduction problems parameterized by the Gaussian random field source is successfully established, which not only provides the solution accurately but is several times faster than the finite element method in our experiments.
Functional Autoencoder for Smoothing and Representation Learning
Jan 17, 2024A common pipeline in functional data analysis is to first convert the discretely observed data to smooth functions, and then represent the functions by a finite-dimensional vector of coefficients summarizing the information. Existing methods for data smoothing and dimensional reduction mainly focus on learning the linear mappings from the data space to the representation space, however, learning only the linear representations may not be sufficient. In this study, we propose to learn the nonlinear representations of functional data using neural network autoencoders designed to process data in the form it is usually collected without the need of preprocessing. We design the encoder to employ a projection layer computing the weighted inner product of the functional data and functional weights over the observed timestamp, and the decoder to apply a recovery layer that maps the finite-dimensional vector extracted from the functional data back to functional space using a set of predetermined basis functions. The developed architecture can accommodate both regularly and irregularly spaced data. Our experiments demonstrate that the proposed method outperforms functional principal component analysis in terms of prediction and classification, and maintains superior smoothing ability and better computational efficiency in comparison to the conventional autoencoders under both linear and nonlinear settings.
Cross-attention Spatio-temporal Context Transformer for Semantic Segmentation of Historical Maps
Oct 19, 2023Historical maps provide useful spatio-temporal information on the Earth's surface before modern earth observation techniques came into being. To extract information from maps, neural networks, which gain wide popularity in recent years, have replaced hand-crafted map processing methods and tedious manual labor. However, aleatoric uncertainty, known as data-dependent uncertainty, inherent in the drawing/scanning/fading defects of the original map sheets and inadequate contexts when cropping maps into small tiles considering the memory limits of the training process, challenges the model to make correct predictions. As aleatoric uncertainty cannot be reduced even with more training data collected, we argue that complementary spatio-temporal contexts can be helpful. To achieve this, we propose a U-Net-based network that fuses spatio-temporal features with cross-attention transformers (U-SpaTem), aggregating information at a larger spatial range as well as through a temporal sequence of images. Our model achieves a better performance than other state-or-art models that use either temporal or spatial contexts. Compared with pure vision transformers, our model is more lightweight and effective. To the best of our knowledge, leveraging both spatial and temporal contexts have been rarely explored before in the segmentation task. Even though our application is on segmenting historical maps, we believe that the method can be transferred into other fields with similar problems like temporal sequences of satellite images. Our code is freely accessible at https://github.com/chenyizi086/wu.2023.sigspatial.git.
Neural Networks for Scalar Input and Functional Output
Aug 10, 2022
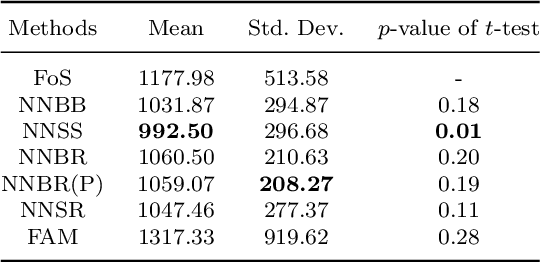
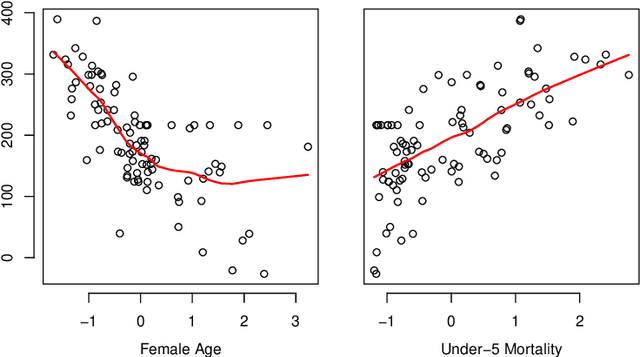
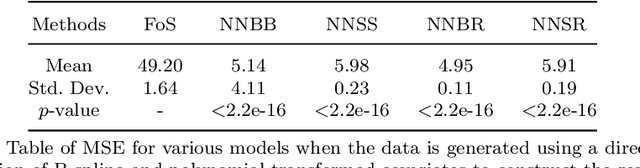
The regression of a functional response on a set of scalar predictors can be a challenging task, especially if there is a large number of predictors, these predictors have interaction effects, or the relationship between those predictors and the response is nonlinear. In this work, we propose a solution to this problem: a feed-forward neural network (NN) designed to predict a functional response using scalar inputs. First, we transform the functional response to a finite-dimension representation and then we construct a NN that outputs this representation. We proposed different objective functions to train the NN. The proposed models are suited for both regularly and irregularly spaced data and also provide multiple ways to apply a roughness penalty to control the smoothness of the predicted curve. The difficulty in implementing both those features lies in the definition of objective functions that can be back-propagated. In our experiments, we demonstrate that our model outperforms the conventional function-on-scalar regression model in multiple scenarios while computationally scaling better with the dimension of the predictors.
FuncNN: An R Package to Fit Deep Neural Networks Using Generalized Input Spaces
Sep 22, 2020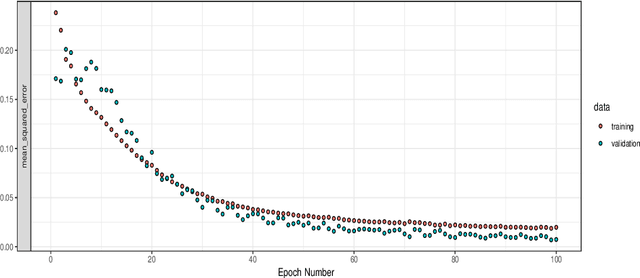
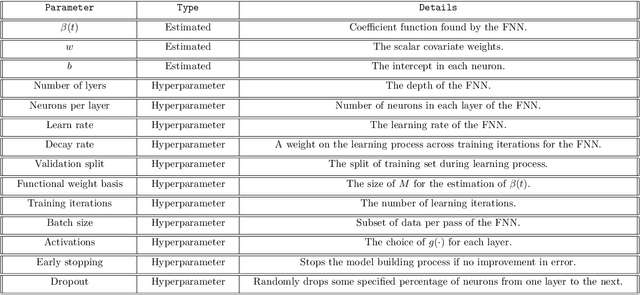
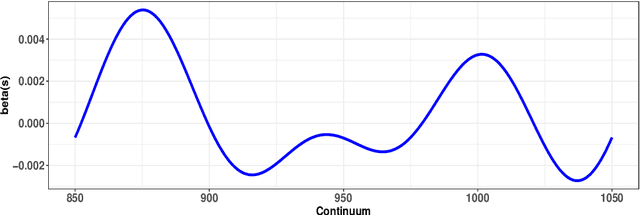

Neural networks have excelled at regression and classification problems when the input space consists of scalar variables. As a result of this proficiency, several popular packages have been developed that allow users to easily fit these kinds of models. However, the methodology has excluded the use of functional covariates and to date, there exists no software that allows users to build deep learning models with this generalized input space. To the best of our knowledge, the functional neural network (FuncNN) library is the first such package in any programming language; the library has been developed for R and is built on top of the keras architecture. Throughout this paper, several functions are introduced that provide users an avenue to easily build models, generate predictions, and run cross-validations. A summary of the underlying methodology is also presented. The ultimate contribution is a package that provides a set of general modelling and diagnostic tools for data problems in which there exist both functional and scalar covariates.