 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJan Dirk Wegner
Point2Building: Reconstructing Buildings from Airborne LiDAR Point Clouds
Mar 04, 2024
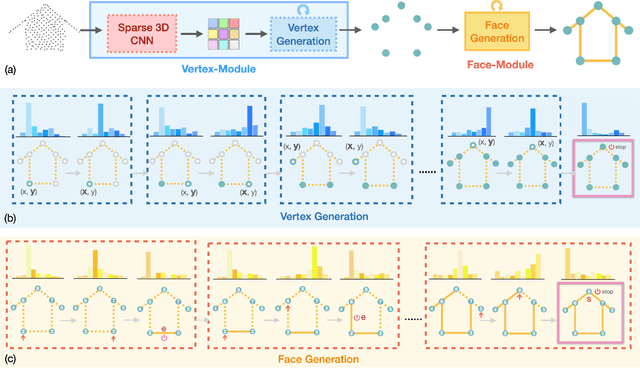
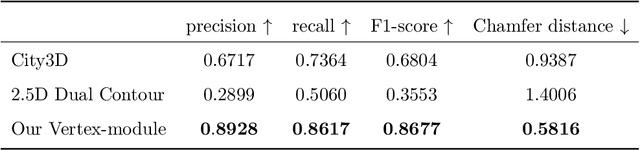
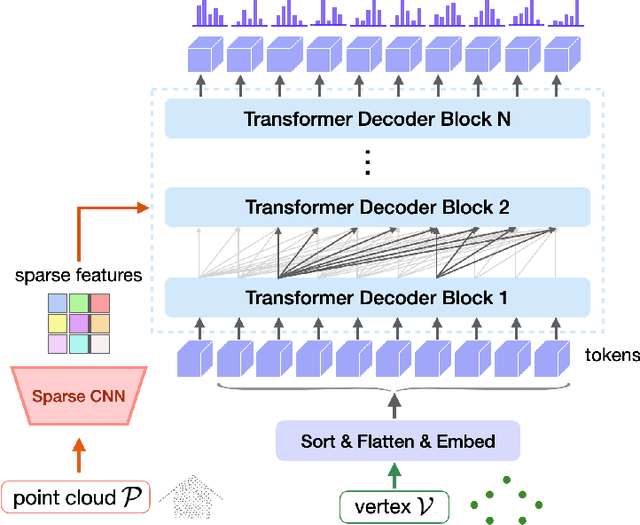

We present a learning-based approach to reconstruct buildings as 3D polygonal meshes from airborne LiDAR point clouds. What makes 3D building reconstruction from airborne LiDAR hard is the large diversity of building designs and especially roof shapes, the low and varying point density across the scene, and the often incomplete coverage of building facades due to occlusions by vegetation or to the viewing angle of the sensor. To cope with the diversity of shapes and inhomogeneous and incomplete object coverage, we introduce a generative model that directly predicts 3D polygonal meshes from input point clouds. Our autoregressive model, called Point2Building, iteratively builds up the mesh by generating sequences of vertices and faces. This approach enables our model to adapt flexibly to diverse geometries and building structures. Unlike many existing methods that rely heavily on pre-processing steps like exhaustive plane detection, our model learns directly from the point cloud data, thereby reducing error propagation and increasing the fidelity of the reconstruction. We experimentally validate our method on a collection of airborne LiDAR data of Zurich, Berlin and Tallinn. Our method shows good generalization to diverse urban styles.
Point2CAD: Reverse Engineering CAD Models from 3D Point Clouds
Dec 07, 2023Computer-Aided Design (CAD) model reconstruction from point clouds is an important problem at the intersection of computer vision, graphics, and machine learning; it saves the designer significant time when iterating on in-the-wild objects. Recent advancements in this direction achieve relatively reliable semantic segmentation but still struggle to produce an adequate topology of the CAD model. In this work, we analyze the current state of the art for that ill-posed task and identify shortcomings of existing methods. We propose a hybrid analytic-neural reconstruction scheme that bridges the gap between segmented point clouds and structured CAD models and can be readily combined with different segmentation backbones. Moreover, to power the surface fitting stage, we propose a novel implicit neural representation of freeform surfaces, driving up the performance of our overall CAD reconstruction scheme. We extensively evaluate our method on the popular ABC benchmark of CAD models and set a new state-of-the-art for that dataset. Project page: https://www.obukhov.ai/point2cad}{https://www.obukhov.ai/point2cad.
Neural Fields with Thermal Activations for Arbitrary-Scale Super-Resolution
Nov 29, 2023Recent approaches for arbitrary-scale single image super-resolution (ASSR) have used local neural fields to represent continuous signals that can be sampled at different rates. However, in such formulation, the point-wise query of field values does not naturally match the point spread function (PSF) of a given pixel. In this work we present a novel way to design neural fields such that points can be queried with a Gaussian PSF, which serves as anti-aliasing when moving across resolutions for ASSR. We achieve this using a novel activation function derived from Fourier theory and the heat equation. This comes at no additional cost: querying a point with a Gaussian PSF in our framework does not affect computational cost, unlike filtering in the image domain. Coupled with a hypernetwork, our method not only provides theoretically guaranteed anti-aliasing, but also sets a new bar for ASSR while also being more parameter-efficient than previous methods.
Mixture of Experts with Uncertainty Voting for Imbalanced Deep Regression Problems
May 24, 2023

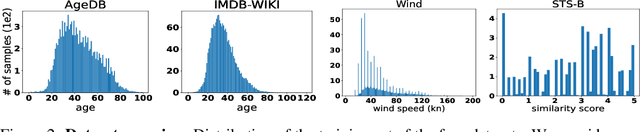

Data imbalance is ubiquitous when applying machine learning to real-world problems, particularly regression problems. If training data are imbalanced, the learning is dominated by the densely covered regions of the target distribution, consequently, the learned regressor tends to exhibit poor performance in sparsely covered regions. Beyond standard measures like over-sampling or re-weighting, there are two main directions to handle learning from imbalanced data. For regression, recent work relies on the continuity of the distribution; whereas for classification there has been a trend to employ mixture-of-expert models and let some ensemble members specialize in predictions for the sparser regions. Here, we adapt the mixture-of-experts approach to the regression setting. A main question when using this approach is how to fuse the predictions from multiple experts into one output. Drawing inspiration from recent work on probabilistic deep learning, we propose to base the fusion on the aleatoric uncertainties of individual experts, thus obviating the need for a separate aggregation module. In our method, dubbed MOUV, each expert predicts not only an output value but also its uncertainty, which in turn serves as a statistically motivated criterion to rely on the right experts. We compare our method with existing alternatives on multiple public benchmarks and show that MOUV consistently outperforms the prior art, while at the same time producing better calibrated uncertainty estimates. Our code is available at link-upon-publication.
UnCRtainTS: Uncertainty Quantification for Cloud Removal in Optical Satellite Time Series
Apr 11, 2023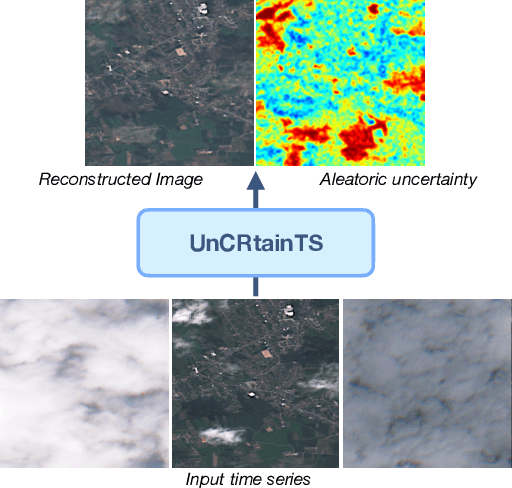
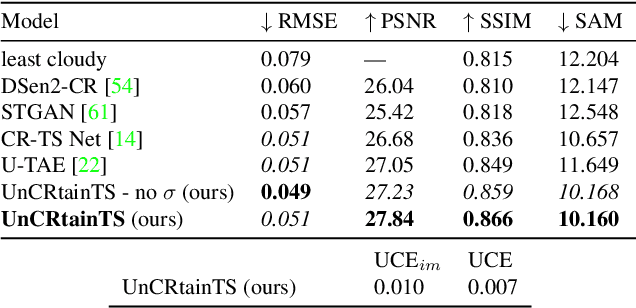
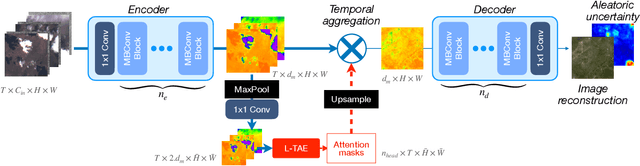
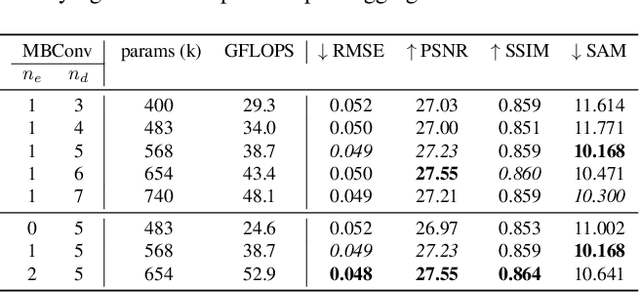
Clouds and haze often occlude optical satellite images, hindering continuous, dense monitoring of the Earth's surface. Although modern deep learning methods can implicitly learn to ignore such occlusions, explicit cloud removal as pre-processing enables manual interpretation and allows training models when only few annotations are available. Cloud removal is challenging due to the wide range of occlusion scenarios -- from scenes partially visible through haze, to completely opaque cloud coverage. Furthermore, integrating reconstructed images in downstream applications would greatly benefit from trustworthy quality assessment. In this paper, we introduce UnCRtainTS, a method for multi-temporal cloud removal combining a novel attention-based architecture, and a formulation for multivariate uncertainty prediction. These two components combined set a new state-of-the-art performance in terms of image reconstruction on two public cloud removal datasets. Additionally, we show how the well-calibrated predicted uncertainties enable a precise control of the reconstruction quality.
An evaluation of deep learning models for predicting water depth evolution in urban floods
Feb 20, 2023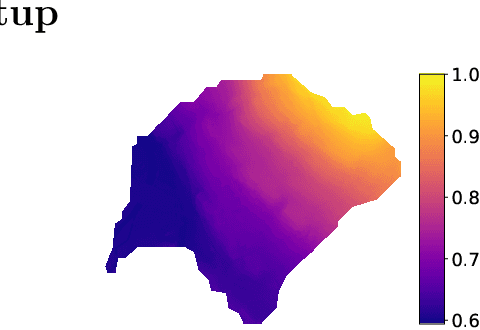



In this technical report we compare different deep learning models for prediction of water depth rasters at high spatial resolution. Efficient, accurate, and fast methods for water depth prediction are nowadays important as urban floods are increasing due to higher rainfall intensity caused by climate change, expansion of cities and changes in land use. While hydrodynamic models models can provide reliable forecasts by simulating water depth at every location of a catchment, they also have a high computational burden which jeopardizes their application to real-time prediction in large urban areas at high spatial resolution. Here, we propose to address this issue by using data-driven techniques. Specifically, we evaluate deep learning models which are trained to reproduce the data simulated by the CADDIES cellular-automata flood model, providing flood forecasts that can occur at different future time horizons. The advantage of using such models is that they can learn the underlying physical phenomena a priori, preventing manual parameter setting and computational burden. We perform experiments on a dataset consisting of two catchments areas within Switzerland with 18 simpler, short rainfall patterns and 4 long, more complex ones. Our results show that the deep learning models present in general lower errors compared to the other methods, especially for water depths $>0.5m$. However, when testing on more complex rainfall events or unseen catchment areas, the deep models do not show benefits over the simpler ones.
FiLM-Ensemble: Probabilistic Deep Learning via Feature-wise Linear Modulation
May 31, 2022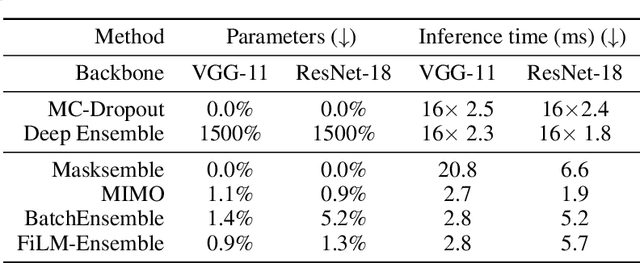
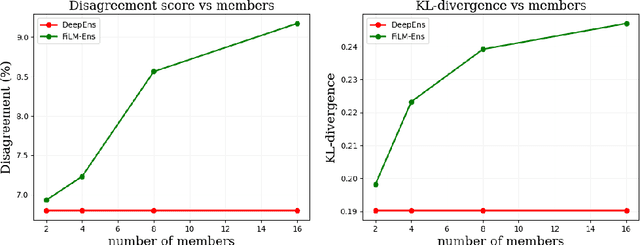
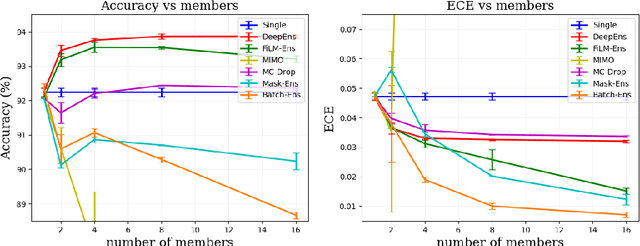
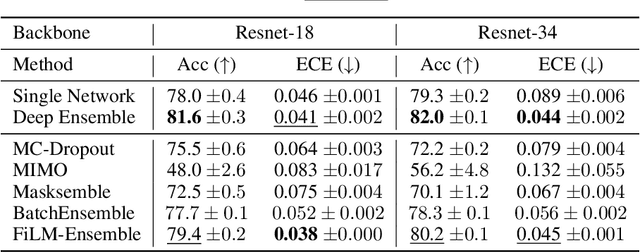
The ability to estimate epistemic uncertainty is often crucial when deploying machine learning in the real world, but modern methods often produce overconfident, uncalibrated uncertainty predictions. A common approach to quantify epistemic uncertainty, usable across a wide class of prediction models, is to train a model ensemble. In a naive implementation, the ensemble approach has high computational cost and high memory demand. This challenges in particular modern deep learning, where even a single deep network is already demanding in terms of compute and memory, and has given rise to a number of attempts to emulate the model ensemble without actually instantiating separate ensemble members. We introduce FiLM-Ensemble, a deep, implicit ensemble method based on the concept of Feature-wise Linear Modulation (FiLM). That technique was originally developed for multi-task learning, with the aim of decoupling different tasks. We show that the idea can be extended to uncertainty quantification: by modulating the network activations of a single deep network with FiLM, one obtains a model ensemble with high diversity, and consequently well-calibrated estimates of epistemic uncertainty, with low computational overhead in comparison. Empirically, FiLM-Ensemble outperforms other implicit ensemble methods, and it and comes very close to the upper bound of an explicit ensemble of networks (sometimes even beating it), at a fraction of the memory cost.
A high-resolution canopy height model of the Earth
Apr 13, 2022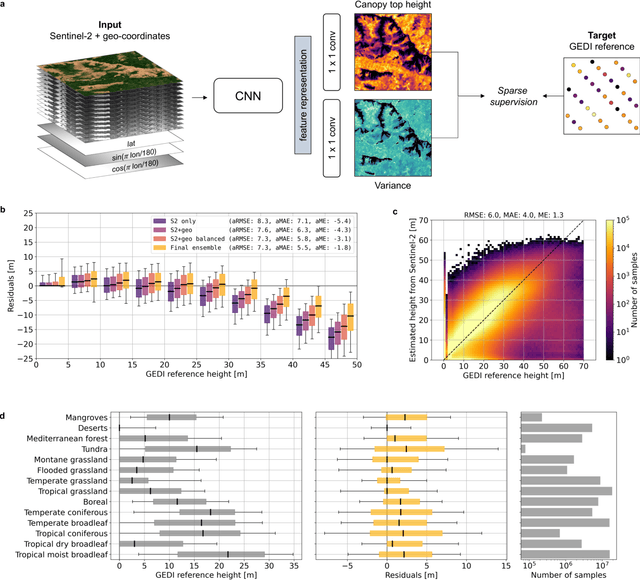
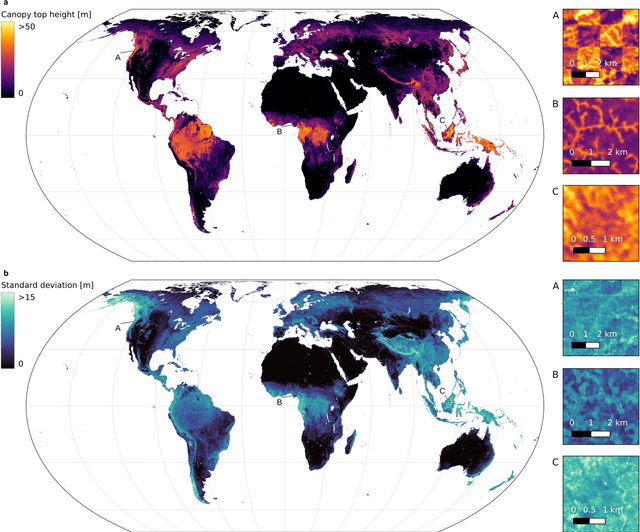

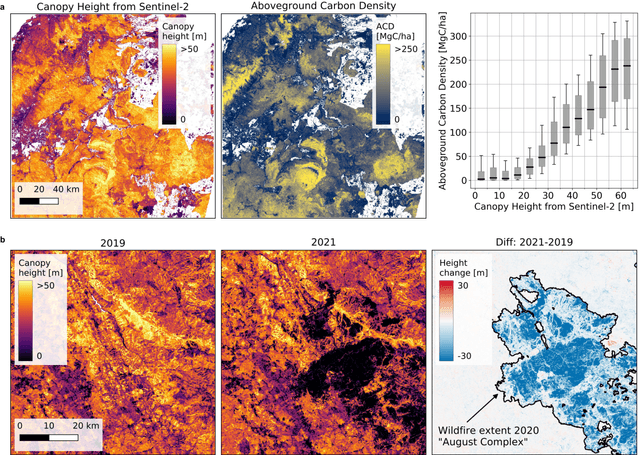
The worldwide variation in vegetation height is fundamental to the global carbon cycle and central to the functioning of ecosystems and their biodiversity. Geospatially explicit and, ideally, highly resolved information is required to manage terrestrial ecosystems, mitigate climate change, and prevent biodiversity loss. Here, we present the first global, wall-to-wall canopy height map at 10 m ground sampling distance for the year 2020. No single data source meets these requirements: dedicated space missions like GEDI deliver sparse height data, with unprecedented coverage, whereas optical satellite images like Sentinel-2 offer dense observations globally, but cannot directly measure vertical structures. By fusing GEDI with Sentinel-2, we have developed a probabilistic deep learning model to retrieve canopy height from Sentinel-2 images anywhere on Earth, and to quantify the uncertainty in these estimates. The presented approach reduces the saturation effect commonly encountered when estimating canopy height from satellite images, allowing to resolve tall canopies with likely high carbon stocks. According to our map, only 5% of the global landmass is covered by trees taller than 30 m. Such data play an important role for conservation, e.g., we find that only 34% of these tall canopies are located within protected areas. Our model enables consistent, uncertainty-informed worldwide mapping and supports an ongoing monitoring to detect change and inform decision making. The approach can serve ongoing efforts in forest conservation, and has the potential to foster advances in climate, carbon, and biodiversity modelling.
A Deep Learning Approach for Digital ColorReconstruction of Lenticular Films
Feb 10, 2022
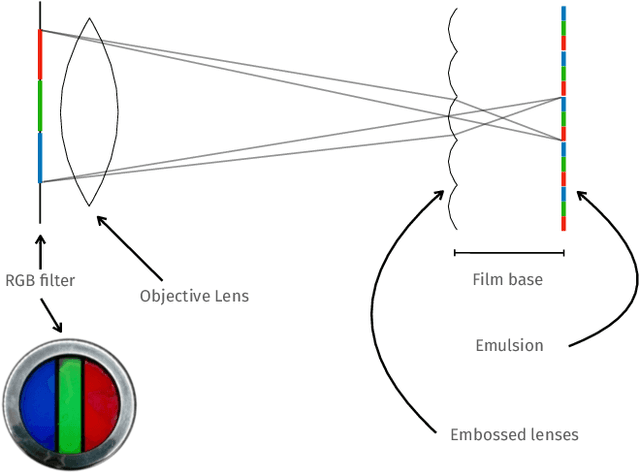

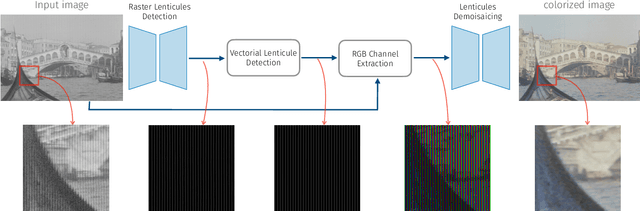
We propose the first accurate digitization and color reconstruction process for historical lenticular film that is robust to artifacts. Lenticular films emerged in the 1920s and were one of the first technologies that permitted to capture full color information in motion. The technology leverages an RGB filter and cylindrical lenticules embossed on the film surface to encode the color in the horizontal spatial dimension of the image. To project the pictures the encoding process was reversed using an appropriate analog device. In this work, we introduce an automated, fully digital pipeline to process the scan of lenticular films and colorize the image. Our method merges deep learning with a model-based approach in order to maximize the performance while making sure that the reconstructed colored images truthfully match the encoded color information. Our model employs different strategies to achieve an effective color reconstruction, in particular (i) we use data augmentation to create a robust lenticule segmentation network, (ii) we fit the lenticules raster prediction to obtain a precise vectorial lenticule localization, and (iii) we train a colorization network that predicts interpolation coefficients in order to obtain a truthful colorization. We validate the proposed method on a lenticular film dataset and compare it to other approaches. Since no colored groundtruth is available as reference, we conduct a user study to validate our method in a subjective manner. The results of the study show that the proposed method is largely preferred with respect to other existing and baseline methods.
Deep Learning and Earth Observation to Support the Sustainable Development Goals
Dec 21, 2021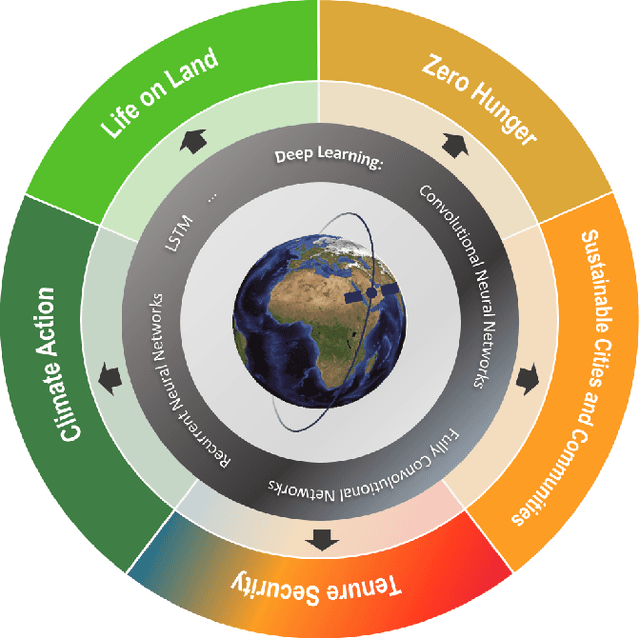

The synergistic combination of deep learning models and Earth observation promises significant advances to support the sustainable development goals (SDGs). New developments and a plethora of applications are already changing the way humanity will face the living planet challenges. This paper reviews current deep learning approaches for Earth observation data, along with their application towards monitoring and achieving the SDGs most impacted by the rapid development of deep learning in Earth observation. We systematically review case studies to 1) achieve zero hunger, 2) sustainable cities, 3) deliver tenure security, 4) mitigate and adapt to climate change, and 5) preserve biodiversity. Important societal, economic and environmental implications are concerned. Exciting times ahead are coming where algorithms and Earth data can help in our endeavor to address the climate crisis and support more sustainable development.