 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevis Tuia
Knowledge-aware Text-Image Retrieval for Remote Sensing Images
May 06, 2024
Image-based retrieval in large Earth observation archives is challenging because one needs to navigate across thousands of candidate matches only with the query image as a guide. By using text as information supporting the visual query, the retrieval system gains in usability, but at the same time faces difficulties due to the diversity of visual signals that cannot be summarized by a short caption only. For this reason, as a matching-based task, cross-modal text-image retrieval often suffers from information asymmetry between texts and images. To address this challenge, we propose a Knowledge-aware Text-Image Retrieval (KTIR) method for remote sensing images. By mining relevant information from an external knowledge graph, KTIR enriches the text scope available in the search query and alleviates the information gaps between texts and images for better matching. Moreover, by integrating domain-specific knowledge, KTIR also enhances the adaptation of pre-trained vision-language models to remote sensing applications. Experimental results on three commonly used remote sensing text-image retrieval benchmarks show that the proposed knowledge-aware method leads to varied and consistent retrievals, outperforming state-of-the-art retrieval methods.
ConGeo: Robust Cross-view Geo-localization across Ground View Variations
Mar 20, 2024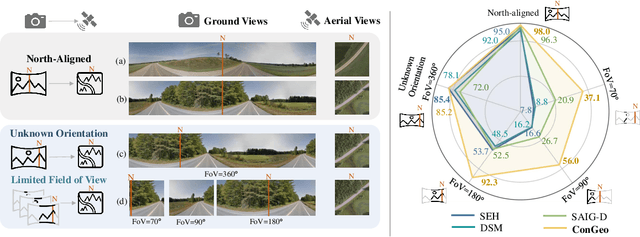
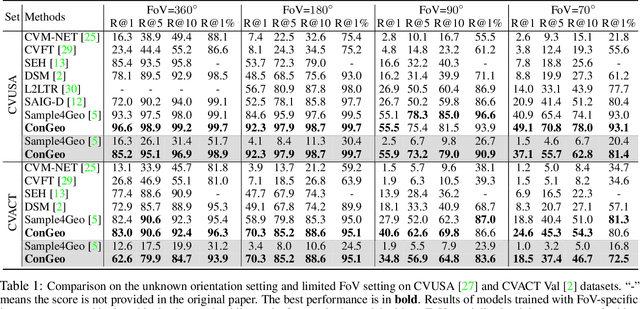
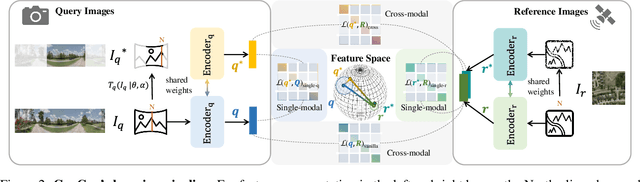
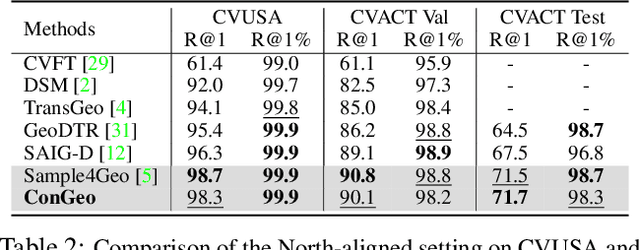
Cross-view geo-localization aims at localizing a ground-level query image by matching it to its corresponding geo-referenced aerial view. In real-world scenarios, the task requires accommodating diverse ground images captured by users with varying orientations and reduced field of views (FoVs). However, existing learning pipelines are orientation-specific or FoV-specific, demanding separate model training for different ground view variations. Such models heavily depend on the North-aligned spatial correspondence and predefined FoVs in the training data, compromising their robustness across different settings. To tackle this challenge, we propose ConGeo, a single- and cross-modal Contrastive method for Geo-localization: it enhances robustness and consistency in feature representations to improve a model's invariance to orientation and its resilience to FoV variations, by enforcing proximity between ground view variations of the same location. As a generic learning objective for cross-view geo-localization, when integrated into state-of-the-art pipelines, ConGeo significantly boosts the performance of three base models on four geo-localization benchmarks for diverse ground view variations and outperforms competing methods that train separate models for each ground view variation.
Cross-Modal Learning of Housing Quality in Amsterdam
Mar 13, 2024



In our research we test data and models for the recognition of housing quality in the city of Amsterdam from ground-level and aerial imagery. For ground-level images we compare Google StreetView (GSV) to Flickr images. Our results show that GSV predicts the most accurate building quality scores, approximately 30% better than using only aerial images. However, we find that through careful filtering and by using the right pre-trained model, Flickr image features combined with aerial image features are able to halve the performance gap to GSV features from 30% to 15%. Our results indicate that there are viable alternatives to GSV for liveability factor prediction, which is encouraging as GSV images are more difficult to acquire and not always available.
Imbalance-aware Presence-only Loss Function for Species Distribution Modeling
Mar 12, 2024



In the face of significant biodiversity decline, species distribution models (SDMs) are essential for understanding the impact of climate change on species habitats by connecting environmental conditions to species occurrences. Traditionally limited by a scarcity of species observations, these models have significantly improved in performance through the integration of larger datasets provided by citizen science initiatives. However, they still suffer from the strong class imbalance between species within these datasets, often resulting in the penalization of rare species--those most critical for conservation efforts. To tackle this issue, this study assesses the effectiveness of training deep learning models using a balanced presence-only loss function on large citizen science-based datasets. We demonstrate that this imbalance-aware loss function outperforms traditional loss functions across various datasets and tasks, particularly in accurately modeling rare species with limited observations.
ConVQG: Contrastive Visual Question Generation with Multimodal Guidance
Feb 20, 2024Asking questions about visual environments is a crucial way for intelligent agents to understand rich multi-faceted scenes, raising the importance of Visual Question Generation (VQG) systems. Apart from being grounded to the image, existing VQG systems can use textual constraints, such as expected answers or knowledge triplets, to generate focused questions. These constraints allow VQG systems to specify the question content or leverage external commonsense knowledge that can not be obtained from the image content only. However, generating focused questions using textual constraints while enforcing a high relevance to the image content remains a challenge, as VQG systems often ignore one or both forms of grounding. In this work, we propose Contrastive Visual Question Generation (ConVQG), a method using a dual contrastive objective to discriminate questions generated using both modalities from those based on a single one. Experiments on both knowledge-aware and standard VQG benchmarks demonstrate that ConVQG outperforms the state-of-the-art methods and generates image-grounded, text-guided, and knowledge-rich questions. Our human evaluation results also show preference for ConVQG questions compared to non-contrastive baselines.
Large Language Models for Captioning and Retrieving Remote Sensing Images
Feb 09, 2024Image captioning and cross-modal retrieval are examples of tasks that involve the joint analysis of visual and linguistic information. In connection to remote sensing imagery, these tasks can help non-expert users in extracting relevant Earth observation information for a variety of applications. Still, despite some previous efforts, the development and application of vision and language models to the remote sensing domain have been hindered by the relatively small size of the available datasets and models used in previous studies. In this work, we propose RS-CapRet, a Vision and Language method for remote sensing tasks, in particular image captioning and text-image retrieval. We specifically propose to use a highly capable large decoder language model together with image encoders adapted to remote sensing imagery through contrastive language-image pre-training. To bridge together the image encoder and language decoder, we propose training simple linear layers with examples from combining different remote sensing image captioning datasets, keeping the other parameters frozen. RS-CapRet can then generate descriptions for remote sensing images and retrieve images from textual descriptions, achieving SOTA or competitive performance with existing methods. Qualitative results illustrate that RS-CapRet can effectively leverage the pre-trained large language model to describe remote sensing images, retrieve them based on different types of queries, and also show the ability to process interleaved sequences of images and text in a dialogue manner.
On the selection and effectiveness of pseudo-absences for species distribution modeling with deep learning
Jan 03, 2024Species distribution modeling is a highly versatile tool for understanding the intricate relationship between environmental conditions and species occurrences. However, the available data often lacks information on confirmed species absence and is limited to opportunistically sampled, presence-only observations. To overcome this limitation, a common approach is to employ pseudo-absences, which are specific geographic locations designated as negative samples. While pseudo-absences are well-established for single-species distribution models, their application in the context of multi-species neural networks remains underexplored. Notably, the significant class imbalance between species presences and pseudo-absences is often left unaddressed. Moreover, the existence of different types of pseudo-absences (e.g., random and target-group background points) adds complexity to the selection process. Determining the optimal combination of pseudo-absences types is difficult and depends on the characteristics of the data, particularly considering that certain types of pseudo-absences can be used to mitigate geographic biases. In this paper, we demonstrate that these challenges can be effectively tackled by integrating pseudo-absences in the training of multi-species neural networks through modifications to the loss function. This adjustment involves assigning different weights to the distinct terms of the loss function, thereby addressing both the class imbalance and the choice of pseudo-absence types. Additionally, we propose a strategy to set these loss weights using spatial block cross-validation with presence-only data. We evaluate our approach using a benchmark dataset containing independent presence-absence data from six different regions and report improved results when compared to competing approaches.
Data-Centric Machine Learning for Geospatial Remote Sensing Data
Dec 08, 2023Recent developments and research in modern machine learning have led to substantial improvements in the geospatial field. Although numerous deep learning models have been proposed, the majority of them have been developed on benchmark datasets that lack strong real-world relevance. Furthermore, the performance of many methods has already saturated on these datasets. We argue that shifting the focus towards a complementary data-centric perspective is necessary to achieve further improvements in accuracy, generalization ability, and real impact in end-user applications. This work presents a definition and precise categorization of automated data-centric learning approaches for geospatial data. It highlights the complementary role of data-centric learning with respect to model-centric in the larger machine learning deployment cycle. We review papers across the entire geospatial field and categorize them into different groups. A set of representative experiments shows concrete implementation examples. These examples provide concrete steps to act on geospatial data with data-centric machine learning approaches.
The curse of language biases in remote sensing VQA: the role of spatial attributes, language diversity, and the need for clear evaluation
Nov 28, 2023



Remote sensing visual question answering (RSVQA) opens new opportunities for the use of overhead imagery by the general public, by enabling human-machine interaction with natural language. Building on the recent advances in natural language processing and computer vision, the goal of RSVQA is to answer a question formulated in natural language about a remote sensing image. Language understanding is essential to the success of the task, but has not yet been thoroughly examined in RSVQA. In particular, the problem of language biases is often overlooked in the remote sensing community, which can impact model robustness and lead to wrong conclusions about the performances of the model. Thus, the present work aims at highlighting the problem of language biases in RSVQA with a threefold analysis strategy: visual blind models, adversarial testing and dataset analysis. This analysis focuses both on model and data. Moreover, we motivate the use of more informative and complementary evaluation metrics sensitive to the issue. The gravity of language biases in RSVQA is then exposed for all of these methods with the training of models discarding the image data and the manipulation of the visual input during inference. Finally, a detailed analysis of question-answer distribution demonstrates the root of the problem in the data itself. Thanks to this analytical study, we observed that biases in remote sensing are more severe than in standard VQA, likely due to the specifics of existing remote sensing datasets for the task, e.g. geographical similarities and sparsity, as well as a simpler vocabulary and question generation strategies. While new, improved and less-biased datasets appear as a necessity for the development of the promising field of RSVQA, we demonstrate that more informed, relative evaluation metrics remain much needed to transparently communicate results of future RSVQA methods.
High-resolution Population Maps Derived from Sentinel-1 and Sentinel-2
Nov 23, 2023Detailed population maps play an important role in diverse fields ranging from humanitarian action to urban planning. Generating such maps in a timely and scalable manner presents a challenge, especially in data-scarce regions. To address it we have developed POPCORN, a population mapping method whose only inputs are free, globally available satellite images from Sentinel-1 and Sentinel-2; and a small number of aggregate population counts over coarse census districts for calibration. Despite the minimal data requirements our approach surpasses the mapping accuracy of existing schemes, including several that rely on building footprints derived from high-resolution imagery. E.g., we were able to produce population maps for Rwanda with 100m GSD based on less than 400 regional census counts. In Kigali, those maps reach an $R^2$ score of 66% w.r.t. a ground truth reference map, with an average error of only $\pm$10 inhabitants/ha. Conveniently, POPCORN retrieves explicit maps of built-up areas and of local building occupancy rates, making the mapping process interpretable and offering additional insights, for instance about the distribution of built-up, but unpopulated areas, e.g., industrial warehouses. Moreover, we find that, once trained, the model can be applied repeatedly to track population changes; and that it can be transferred to geographically similar regions, e.g., from Uganda to Rwanda). With our work we aim to democratize access to up-to-date and high-resolution population maps, recognizing that some regions faced with particularly strong population dynamics may lack the resources for costly micro-census campaigns.