 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYan Zhou
Weakly Supervised Anomaly Detection via Knowledge-Data Alignment
Feb 06, 2024
Anomaly detection (AD) plays a pivotal role in numerous web-based applications, including malware detection, anti-money laundering, device failure detection, and network fault analysis. Most methods, which rely on unsupervised learning, are hard to reach satisfactory detection accuracy due to the lack of labels. Weakly Supervised Anomaly Detection (WSAD) has been introduced with a limited number of labeled anomaly samples to enhance model performance. Nevertheless, it is still challenging for models, trained on an inadequate amount of labeled data, to generalize to unseen anomalies. In this paper, we introduce a novel framework Knowledge-Data Alignment (KDAlign) to integrate rule knowledge, typically summarized by human experts, to supplement the limited labeled data. Specifically, we transpose these rules into the knowledge space and subsequently recast the incorporation of knowledge as the alignment of knowledge and data. To facilitate this alignment, we employ the Optimal Transport (OT) technique. We then incorporate the OT distance as an additional loss term to the original objective function of WSAD methodologies. Comprehensive experimental results on five real-world datasets demonstrate that our proposed KDAlign framework markedly surpasses its state-of-the-art counterparts, achieving superior performance across various anomaly types.
Temporal-Aware Refinement for Video-based Human Pose and Shape Recovery
Nov 16, 2023

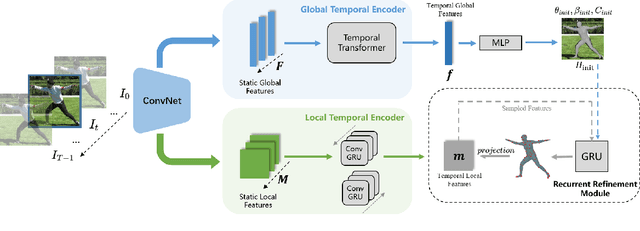
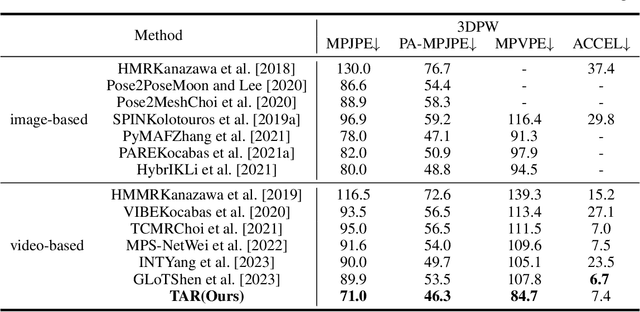
Though significant progress in human pose and shape recovery from monocular RGB images has been made in recent years, obtaining 3D human motion with high accuracy and temporal consistency from videos remains challenging. Existing video-based methods tend to reconstruct human motion from global image features, which lack detailed representation capability and limit the reconstruction accuracy. In this paper, we propose a Temporal-Aware Refining Network (TAR), to synchronously explore temporal-aware global and local image features for accurate pose and shape recovery. First, a global transformer encoder is introduced to obtain temporal global features from static feature sequences. Second, a bidirectional ConvGRU network takes the sequence of high-resolution feature maps as input, and outputs temporal local feature maps that maintain high resolution and capture the local motion of the human body. Finally, a recurrent refinement module iteratively updates estimated SMPL parameters by leveraging both global and local temporal information to achieve accurate and smooth results. Extensive experiments demonstrate that our TAR obtains more accurate results than previous state-of-the-art methods on popular benchmarks, i.e., 3DPW, MPI-INF-3DHP, and Human3.6M.
DASpeech: Directed Acyclic Transformer for Fast and High-quality Speech-to-Speech Translation
Oct 11, 2023
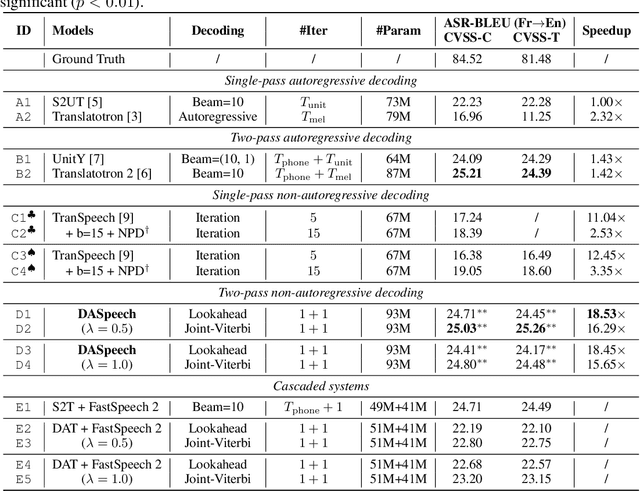


Direct speech-to-speech translation (S2ST) translates speech from one language into another using a single model. However, due to the presence of linguistic and acoustic diversity, the target speech follows a complex multimodal distribution, posing challenges to achieving both high-quality translations and fast decoding speeds for S2ST models. In this paper, we propose DASpeech, a non-autoregressive direct S2ST model which realizes both fast and high-quality S2ST. To better capture the complex distribution of the target speech, DASpeech adopts the two-pass architecture to decompose the generation process into two steps, where a linguistic decoder first generates the target text, and an acoustic decoder then generates the target speech based on the hidden states of the linguistic decoder. Specifically, we use the decoder of DA-Transformer as the linguistic decoder, and use FastSpeech 2 as the acoustic decoder. DA-Transformer models translations with a directed acyclic graph (DAG). To consider all potential paths in the DAG during training, we calculate the expected hidden states for each target token via dynamic programming, and feed them into the acoustic decoder to predict the target mel-spectrogram. During inference, we select the most probable path and take hidden states on that path as input to the acoustic decoder. Experiments on the CVSS Fr-En benchmark demonstrate that DASpeech can achieve comparable or even better performance than the state-of-the-art S2ST model Translatotron 2, while preserving up to 18.53x speedup compared to the autoregressive baseline. Compared with the previous non-autoregressive S2ST model, DASpeech does not rely on knowledge distillation and iterative decoding, achieving significant improvements in both translation quality and decoding speed. Furthermore, DASpeech shows the ability to preserve the speaker's voice of the source speech during translation.
Using AI Uncertainty Quantification to Improve Human Decision-Making
Sep 19, 2023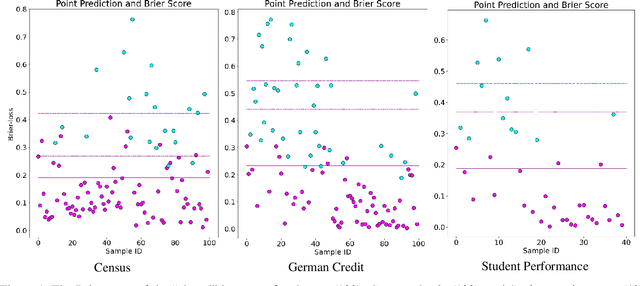
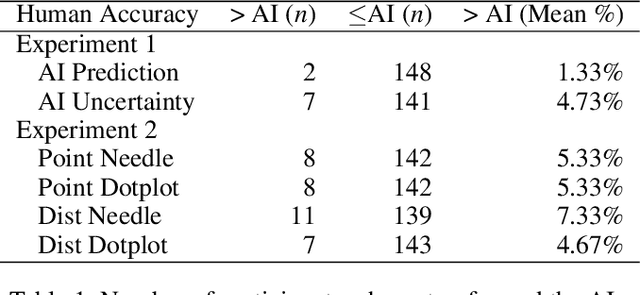
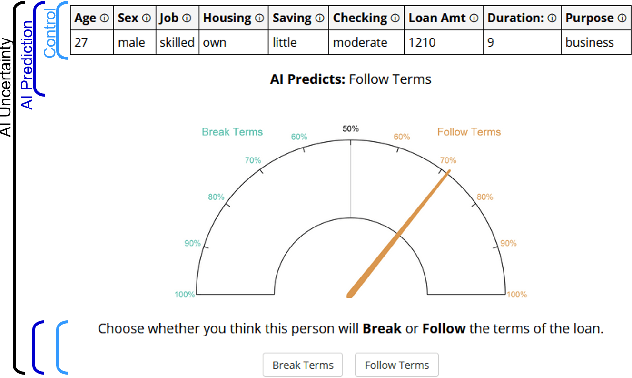
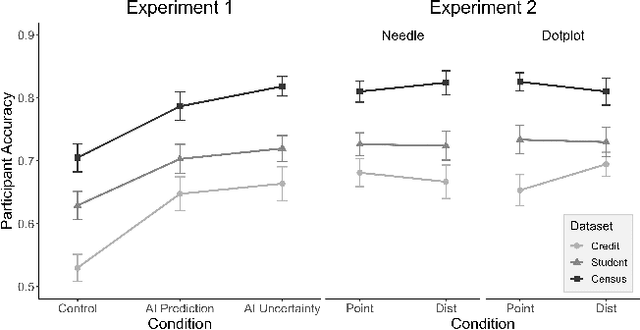
AI Uncertainty Quantification (UQ) has the potential to improve human decision-making beyond AI predictions alone by providing additional useful probabilistic information to users. The majority of past research on AI and human decision-making has concentrated on model explainability and interpretability. We implemented instance-based UQ for three real datasets. To achieve this, we trained different AI models for classification for each dataset, and used random samples generated around the neighborhood of the given instance to create confidence intervals for UQ. The computed UQ was calibrated using a strictly proper scoring rule as a form of quality assurance for UQ. We then conducted two preregistered online behavioral experiments that compared objective human decision-making performance under different AI information conditions, including UQ. In Experiment 1, we compared decision-making for no AI (control), AI prediction alone, and AI prediction with a visualization of UQ. We found UQ significantly improved decision-making beyond the other two conditions. In Experiment 2, we focused on comparing different representations of UQ information: Point vs. distribution of uncertainty and visualization type (needle vs. dotplot). We did not find meaningful differences in decision-making performance among these different representations of UQ. Overall, our results indicate that human decision-making can be improved by providing UQ information along with AI predictions, and that this benefit generalizes across a variety of representations of UQ.
LKPNR: LLM and KG for Personalized News Recommendation Framework
Aug 23, 2023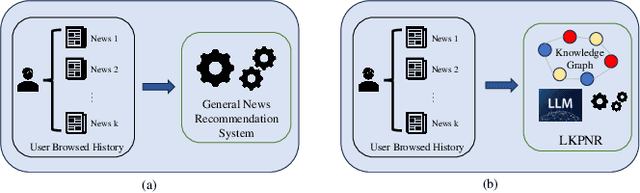
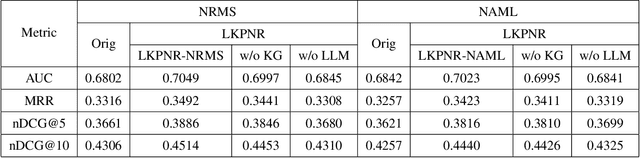
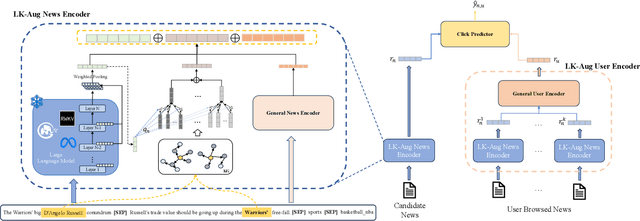

Accurately recommending candidate news articles to users is a basic challenge faced by personalized news recommendation systems. Traditional methods are usually difficult to grasp the complex semantic information in news texts, resulting in unsatisfactory recommendation results. Besides, these traditional methods are more friendly to active users with rich historical behaviors. However, they can not effectively solve the "long tail problem" of inactive users. To address these issues, this research presents a novel general framework that combines Large Language Models (LLM) and Knowledge Graphs (KG) into semantic representations of traditional methods. In order to improve semantic understanding in complex news texts, we use LLMs' powerful text understanding ability to generate news representations containing rich semantic information. In addition, our method combines the information about news entities and mines high-order structural information through multiple hops in KG, thus alleviating the challenge of long tail distribution. Experimental results demonstrate that compared with various traditional models, the framework significantly improves the recommendation effect. The successful integration of LLM and KG in our framework has established a feasible path for achieving more accurate personalized recommendations in the news field. Our code is available at https://github.com/Xuan-ZW/LKPNR.
BayLing: Bridging Cross-lingual Alignment and Instruction Following through Interactive Translation for Large Language Models
Jun 21, 2023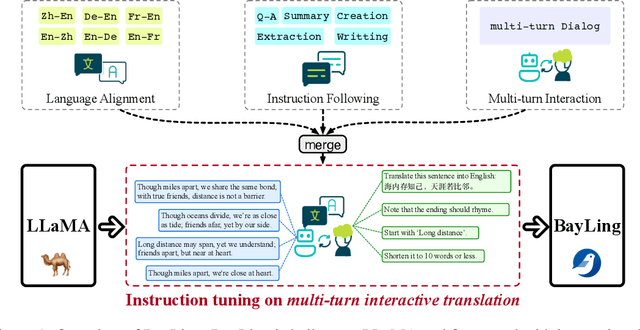
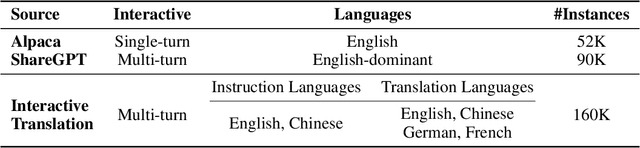

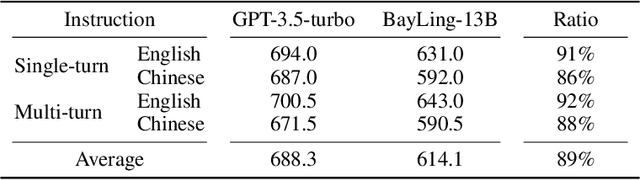
Large language models (LLMs) have demonstrated remarkable prowess in language understanding and generation. Advancing from foundation LLMs to instructionfollowing LLMs, instruction tuning plays a vital role in aligning LLMs to human preferences. However, the existing LLMs are usually focused on English, leading to inferior performance in non-English languages. In order to improve the performance for non-English languages, it is necessary to collect language-specific training data for foundation LLMs and construct language-specific instructions for instruction tuning, both of which are heavy loads. To minimize human workload, we propose to transfer the capabilities of language generation and instruction following from English to other languages through an interactive translation task. We have developed BayLing, an instruction-following LLM by utilizing LLaMA as the foundation LLM and automatically constructing interactive translation instructions for instructing tuning. Extensive assessments demonstrate that BayLing achieves comparable performance to GPT-3.5-turbo, despite utilizing a considerably smaller parameter size of only 13 billion. Experimental results on translation tasks show that BayLing achieves 95% of single-turn translation capability compared to GPT-4 with automatic evaluation and 96% of interactive translation capability compared to GPT-3.5-turbo with human evaluation. To estimate the performance on general tasks, we created a multi-turn instruction test set called BayLing-80. The experimental results on BayLing-80 indicate that BayLing achieves 89% of performance compared to GPT-3.5-turbo. BayLing also demonstrates outstanding performance on knowledge assessment of Chinese GaoKao and English SAT, second only to GPT-3.5-turbo among a multitude of instruction-following LLMs. Demo, homepage, code and models of BayLing are available.
CMOT: Cross-modal Mixup via Optimal Transport for Speech Translation
May 25, 2023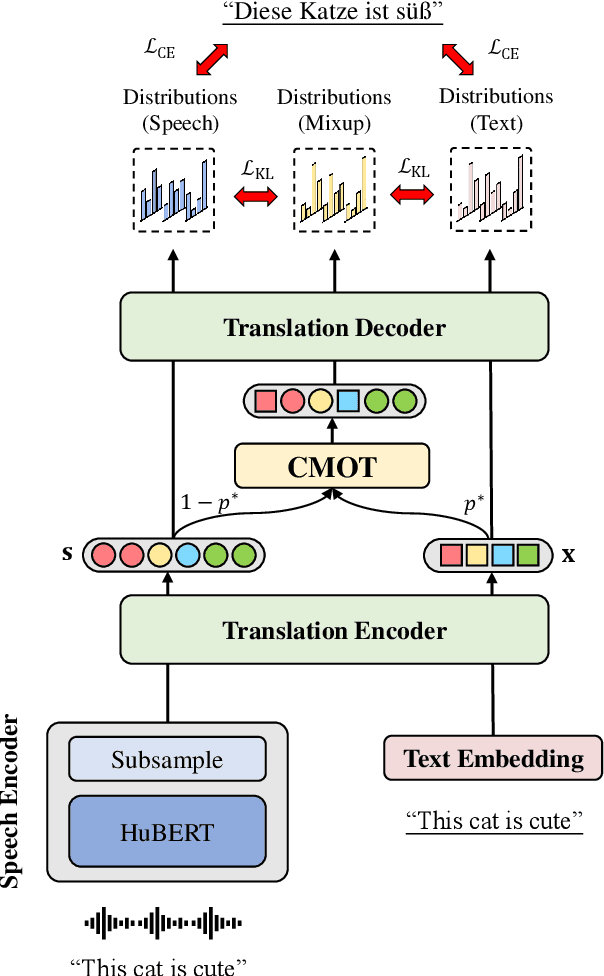
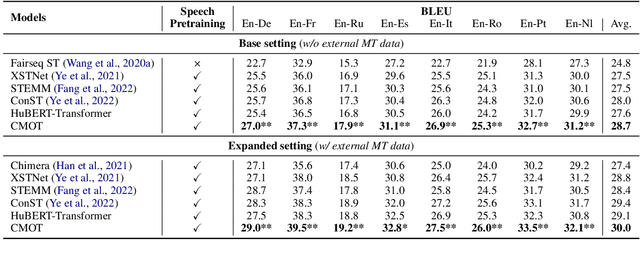
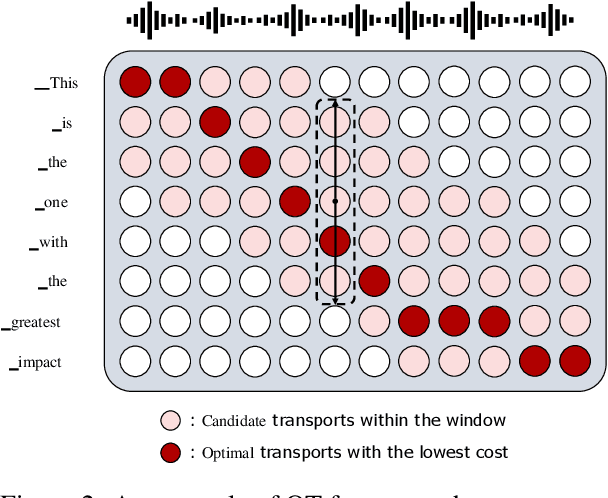
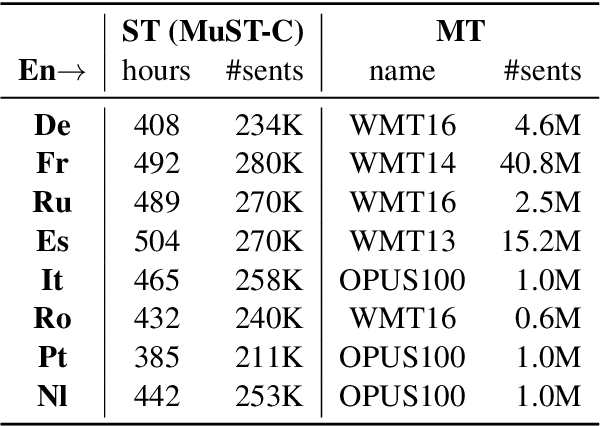
End-to-end speech translation (ST) is the task of translating speech signals in the source language into text in the target language. As a cross-modal task, end-to-end ST is difficult to train with limited data. Existing methods often try to transfer knowledge from machine translation (MT), but their performances are restricted by the modality gap between speech and text. In this paper, we propose Cross-modal Mixup via Optimal Transport CMOT to overcome the modality gap. We find the alignment between speech and text sequences via optimal transport and then mix up the sequences from different modalities at a token level using the alignment. Experiments on the MuST-C ST benchmark demonstrate that CMOT achieves an average BLEU of 30.0 in 8 translation directions, outperforming previous methods. Further analysis shows CMOT can adaptively find the alignment between modalities, which helps alleviate the modality gap between speech and text. Code is publicly available at https://github.com/ictnlp/CMOT.
Attention-guided Multi-step Fusion: A Hierarchical Fusion Network for Multimodal Recommendation
Apr 24, 2023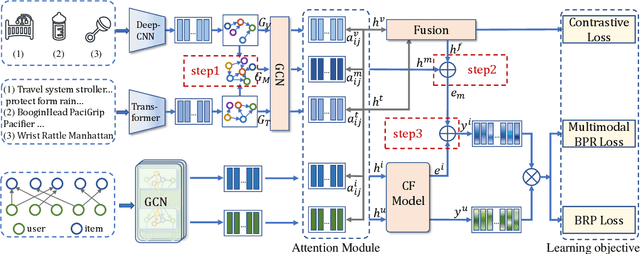
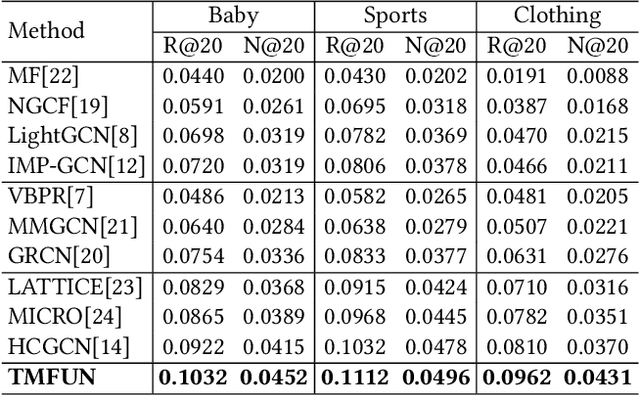
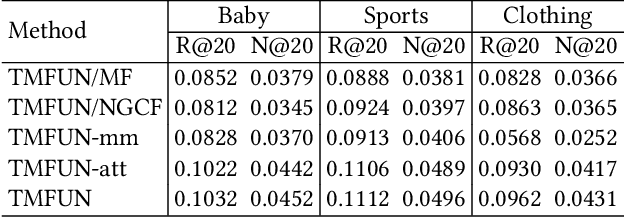
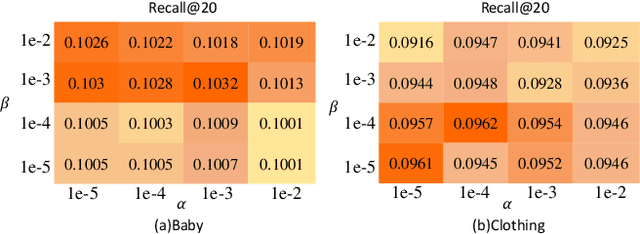
The main idea of multimodal recommendation is the rational utilization of the item's multimodal information to improve the recommendation performance. Previous works directly integrate item multimodal features with item ID embeddings, ignoring the inherent semantic relations contained in the multimodal features. In this paper, we propose a novel and effective aTtention-guided Multi-step FUsion Network for multimodal recommendation, named TMFUN. Specifically, our model first constructs modality feature graph and item feature graph to model the latent item-item semantic structures. Then, we use the attention module to identify inherent connections between user-item interaction data and multimodal data, evaluate the impact of multimodal data on different interactions, and achieve early-step fusion of item features. Furthermore, our model optimizes item representation through the attention-guided multi-step fusion strategy and contrastive learning to improve recommendation performance. The extensive experiments on three real-world datasets show that our model has superior performance compared to the state-of-the-art models.
Deep learning reveals the common spectrum underlying multiple brain disorders in youth and elders from brain functional networks
Feb 23, 2023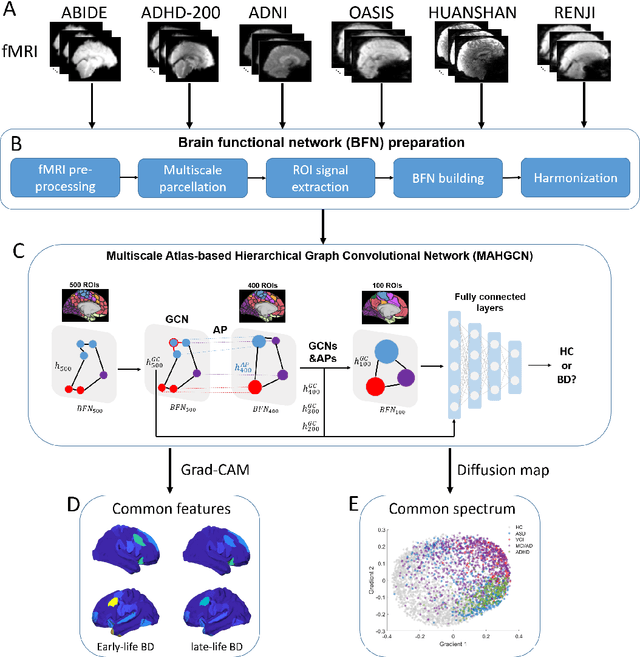
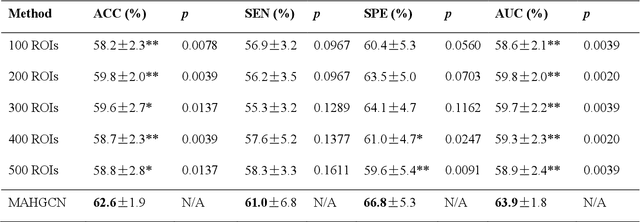
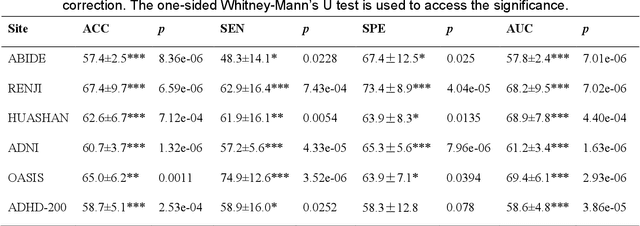
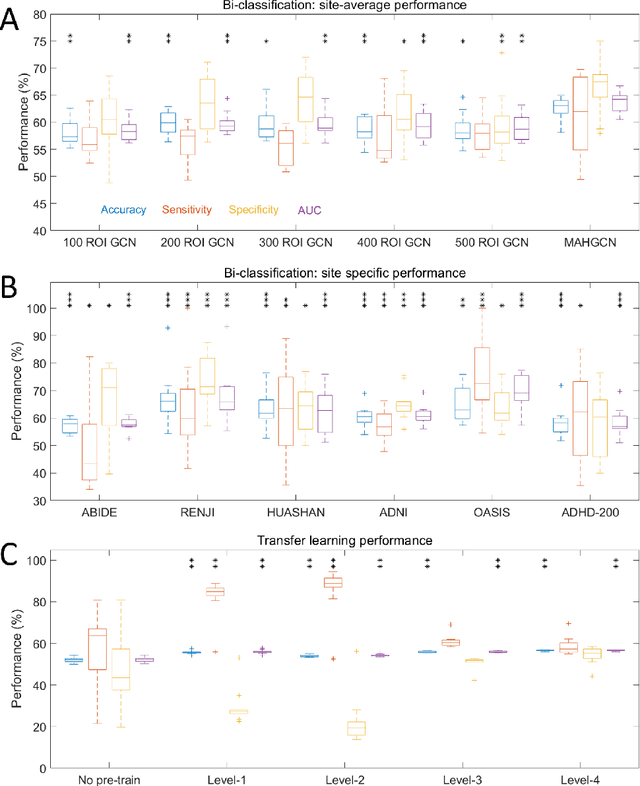
Brain disorders in the early and late life of humans potentially share pathological alterations in brain functions. However, the key evidence from neuroimaging data for pathological commonness remains unrevealed. To explore this hypothesis, we build a deep learning model, using multi-site functional magnetic resonance imaging data (N=4,410, 6 sites), for classifying 5 different brain disorders from healthy controls, with a set of common features. Our model achieves 62.6(1.9)% overall classification accuracy on data from the 6 investigated sites and detects a set of commonly affected functional subnetworks at different spatial scales, including default mode, executive control, visual, and limbic networks. In the deep-layer feature representation for individual data, we observe young and aging patients with disorders are continuously distributed, which is in line with the clinical concept of the "spectrum of disorders". The revealed spectrum underlying early- and late-life brain disorders promotes the understanding of disorder comorbidities in the lifespan.
HGAN: Hierarchical Graph Alignment Network for Image-Text Retrieval
Dec 16, 2022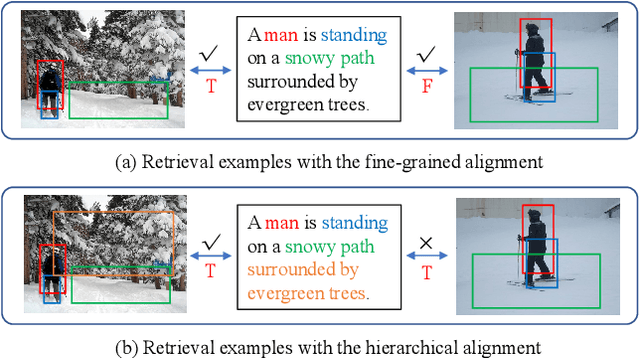
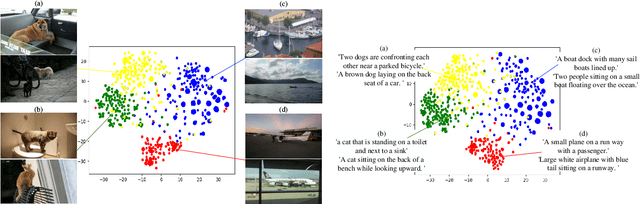


Image-text retrieval (ITR) is a challenging task in the field of multimodal information processing due to the semantic gap between different modalities. In recent years, researchers have made great progress in exploring the accurate alignment between image and text. However, existing works mainly focus on the fine-grained alignment between image regions and sentence fragments, which ignores the guiding significance of context background information. Actually, integrating the local fine-grained information and global context background information can provide more semantic clues for retrieval. In this paper, we propose a novel Hierarchical Graph Alignment Network (HGAN) for image-text retrieval. First, to capture the comprehensive multimodal features, we construct the feature graphs for the image and text modality respectively. Then, a multi-granularity shared space is established with a designed Multi-granularity Feature Aggregation and Rearrangement (MFAR) module, which enhances the semantic corresponding relations between the local and global information, and obtains more accurate feature representations for the image and text modalities. Finally, the ultimate image and text features are further refined through three-level similarity functions to achieve the hierarchical alignment. To justify the proposed model, we perform extensive experiments on MS-COCO and Flickr30K datasets. Experimental results show that the proposed HGAN outperforms the state-of-the-art methods on both datasets, which demonstrates the effectiveness and superiority of our model.