 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWenbo Hu
VALOR-EVAL: Holistic Coverage and Faithfulness Evaluation of Large Vision-Language Models
Apr 22, 2024
Large Vision-Language Models (LVLMs) suffer from hallucination issues, wherein the models generate plausible-sounding but factually incorrect outputs, undermining their reliability. A comprehensive quantitative evaluation is necessary to identify and understand the extent of hallucinations in these models. However, existing benchmarks are often limited in scope, focusing mainly on object hallucinations. Furthermore, current evaluation methods struggle to effectively address the subtle semantic distinctions between model outputs and reference data, as well as the balance between hallucination and informativeness. To address these issues, we introduce a multi-dimensional benchmark covering objects, attributes, and relations, with challenging images selected based on associative biases. Moreover, we propose an large language model (LLM)-based two-stage evaluation framework that generalizes the popular CHAIR metric and incorporates both faithfulness and coverage into the evaluation. Experiments on 10 established LVLMs demonstrate that our evaluation metric is more comprehensive and better correlated with humans than existing work when evaluating on our challenging human annotated benchmark dataset. Our work also highlights the critical balance between faithfulness and coverage of model outputs, and encourages future works to address hallucinations in LVLMs while keeping their outputs informative.
Inverse Rendering of Glossy Objects via the Neural Plenoptic Function and Radiance Fields
Mar 24, 2024Inverse rendering aims at recovering both geometry and materials of objects. It provides a more compatible reconstruction for conventional rendering engines, compared with the neural radiance fields (NeRFs). On the other hand, existing NeRF-based inverse rendering methods cannot handle glossy objects with local light interactions well, as they typically oversimplify the illumination as a 2D environmental map, which assumes infinite lights only. Observing the superiority of NeRFs in recovering radiance fields, we propose a novel 5D Neural Plenoptic Function (NeP) based on NeRFs and ray tracing, such that more accurate lighting-object interactions can be formulated via the rendering equation. We also design a material-aware cone sampling strategy to efficiently integrate lights inside the BRDF lobes with the help of pre-filtered radiance fields. Our method has two stages: the geometry of the target object and the pre-filtered environmental radiance fields are reconstructed in the first stage, and materials of the target object are estimated in the second stage with the proposed NeP and material-aware cone sampling strategy. Extensive experiments on the proposed real-world and synthetic datasets demonstrate that our method can reconstruct high-fidelity geometry/materials of challenging glossy objects with complex lighting interactions from nearby objects. Project webpage: https://whyy.site/paper/nep
Pixel-GS: Density Control with Pixel-aware Gradient for 3D Gaussian Splatting
Mar 22, 20243D Gaussian Splatting (3DGS) has demonstrated impressive novel view synthesis results while advancing real-time rendering performance. However, it relies heavily on the quality of the initial point cloud, resulting in blurring and needle-like artifacts in areas with insufficient initializing points. This is mainly attributed to the point cloud growth condition in 3DGS that only considers the average gradient magnitude of points from observable views, thereby failing to grow for large Gaussians that are observable for many viewpoints while many of them are only covered in the boundaries. To this end, we propose a novel method, named Pixel-GS, to take into account the number of pixels covered by the Gaussian in each view during the computation of the growth condition. We regard the covered pixel numbers as the weights to dynamically average the gradients from different views, such that the growth of large Gaussians can be prompted. As a result, points within the areas with insufficient initializing points can be grown more effectively, leading to a more accurate and detailed reconstruction. In addition, we propose a simple yet effective strategy to scale the gradient field according to the distance to the camera, to suppress the growth of floaters near the camera. Extensive experiments both qualitatively and quantitatively demonstrate that our method achieves state-of-the-art rendering quality while maintaining real-time rendering speed, on the challenging Mip-NeRF 360 and Tanks & Temples datasets.
Analytic-Splatting: Anti-Aliased 3D Gaussian Splatting via Analytic Integration
Mar 17, 2024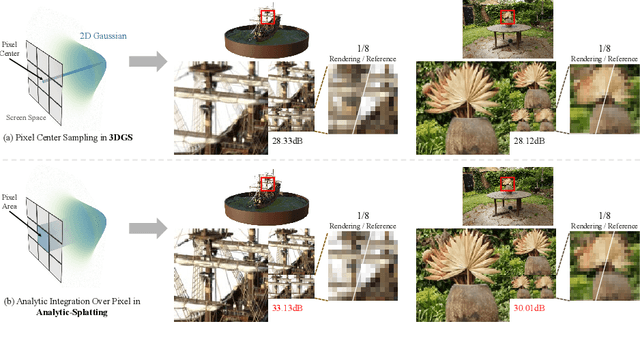
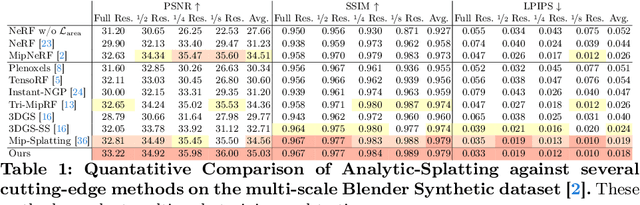
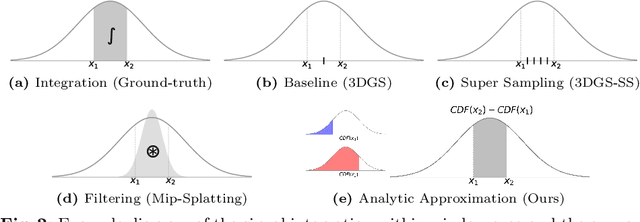
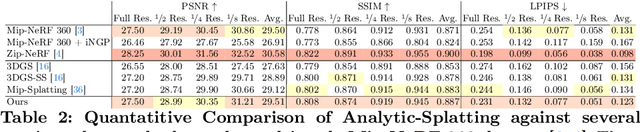
The 3D Gaussian Splatting (3DGS) gained its popularity recently by combining the advantages of both primitive-based and volumetric 3D representations, resulting in improved quality and efficiency for 3D scene rendering. However, 3DGS is not alias-free, and its rendering at varying resolutions could produce severe blurring or jaggies. This is because 3DGS treats each pixel as an isolated, single point rather than as an area, causing insensitivity to changes in the footprints of pixels. Consequently, this discrete sampling scheme inevitably results in aliasing, owing to the restricted sampling bandwidth. In this paper, we derive an analytical solution to address this issue. More specifically, we use a conditioned logistic function as the analytic approximation of the cumulative distribution function (CDF) in a one-dimensional Gaussian signal and calculate the Gaussian integral by subtracting the CDFs. We then introduce this approximation in the two-dimensional pixel shading, and present Analytic-Splatting, which analytically approximates the Gaussian integral within the 2D-pixel window area to better capture the intensity response of each pixel. Moreover, we use the approximated response of the pixel window integral area to participate in the transmittance calculation of volume rendering, making Analytic-Splatting sensitive to the changes in pixel footprint at different resolutions. Experiments on various datasets validate that our approach has better anti-aliasing capability that gives more details and better fidelity.
Texture-GS: Disentangling the Geometry and Texture for 3D Gaussian Splatting Editing
Mar 15, 2024
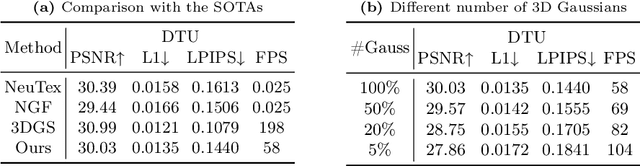
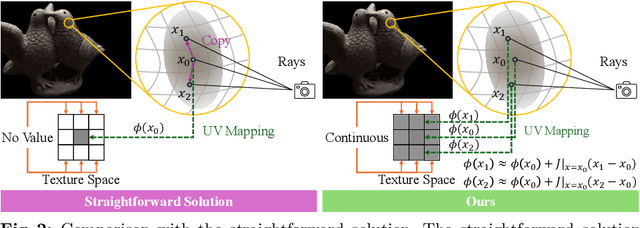
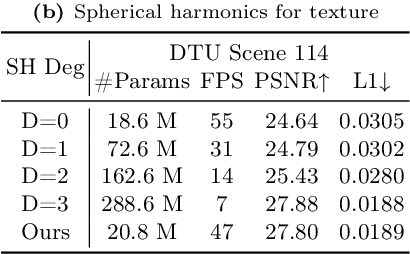
3D Gaussian splatting, emerging as a groundbreaking approach, has drawn increasing attention for its capabilities of high-fidelity reconstruction and real-time rendering. However, it couples the appearance and geometry of the scene within the Gaussian attributes, which hinders the flexibility of editing operations, such as texture swapping. To address this issue, we propose a novel approach, namely Texture-GS, to disentangle the appearance from the geometry by representing it as a 2D texture mapped onto the 3D surface, thereby facilitating appearance editing. Technically, the disentanglement is achieved by our proposed texture mapping module, which consists of a UV mapping MLP to learn the UV coordinates for the 3D Gaussian centers, a local Taylor expansion of the MLP to efficiently approximate the UV coordinates for the ray-Gaussian intersections, and a learnable texture to capture the fine-grained appearance. Extensive experiments on the DTU dataset demonstrate that our method not only facilitates high-fidelity appearance editing but also achieves real-time rendering on consumer-level devices, e.g. a single RTX 2080 Ti GPU.
Deep Ensembles Meets Quantile Regression: Uncertainty-aware Imputation for Time Series
Dec 03, 2023Multivariate time series are everywhere. Nevertheless, real-world time series data often exhibit numerous missing values, which is the time series imputation task. Although previous deep learning methods have been shown to be effective for time series imputation, they are shown to produce overconfident imputations, which might be a potentially overlooked threat to the reliability of the intelligence system. Score-based diffusion method(i.e., CSDI) is effective for the time series imputation task but computationally expensive due to the nature of the generative diffusion model framework. In this paper, we propose a non-generative time series imputation method that produces accurate imputations with inherent uncertainty and meanwhile is computationally efficient. Specifically, we incorporate deep ensembles into quantile regression with a shared model backbone and a series of quantile discrimination functions.This framework combines the merits of accurate uncertainty estimation of deep ensembles and quantile regression and above all, the shared model backbone tremendously reduces most of the computation overhead of the multiple ensembles. We examine the performance of the proposed method on two real-world datasets: air quality and health-care datasets and conduct extensive experiments to show that our method excels at making deterministic and probabilistic predictions. Compared with the score-based diffusion method: CSDI, we can obtain comparable forecasting results and is better when more data is missing. Furthermore, as a non-generative model compared with CSDI, the proposed method consumes a much smaller computation overhead, yielding much faster training speed and fewer model parameters.
DreamSpace: Dreaming Your Room Space with Text-Driven Panoramic Texture Propagation
Oct 19, 2023Diffusion-based methods have achieved prominent success in generating 2D media. However, accomplishing similar proficiencies for scene-level mesh texturing in 3D spatial applications, e.g., XR/VR, remains constrained, primarily due to the intricate nature of 3D geometry and the necessity for immersive free-viewpoint rendering. In this paper, we propose a novel indoor scene texturing framework, which delivers text-driven texture generation with enchanting details and authentic spatial coherence. The key insight is to first imagine a stylized 360{\deg} panoramic texture from the central viewpoint of the scene, and then propagate it to the rest areas with inpainting and imitating techniques. To ensure meaningful and aligned textures to the scene, we develop a novel coarse-to-fine panoramic texture generation approach with dual texture alignment, which both considers the geometry and texture cues of the captured scenes. To survive from cluttered geometries during texture propagation, we design a separated strategy, which conducts texture inpainting in confidential regions and then learns an implicit imitating network to synthesize textures in occluded and tiny structural areas. Extensive experiments and the immersive VR application on real-world indoor scenes demonstrate the high quality of the generated textures and the engaging experience on VR headsets. Project webpage: https://ybbbbt.com/publication/dreamspace
Investigating Uncertainty Calibration of Aligned Language Models under the Multiple-Choice Setting
Oct 18, 2023Despite the significant progress made in practical applications of aligned language models (LMs), they tend to be overconfident in output answers compared to the corresponding pre-trained LMs. In this work, we systematically evaluate the impact of the alignment process on logit-based uncertainty calibration of LMs under the multiple-choice setting. We first conduct a thoughtful empirical study on how aligned LMs differ in calibration from their pre-trained counterparts. Experimental results reveal that there are two distinct uncertainties in LMs under the multiple-choice setting, which are responsible for the answer decision and the format preference of the LMs, respectively. Then, we investigate the role of these two uncertainties on aligned LM's calibration through fine-tuning in simple synthetic alignment schemes and conclude that one reason for aligned LMs' overconfidence is the conflation of these two types of uncertainty. Furthermore, we examine the utility of common post-hoc calibration methods for aligned LMs and propose an easy-to-implement and sample-efficient method to calibrate aligned LMs. We hope our findings could provide insights into the design of more reliable alignment processes for LMs.
BLIVA: A Simple Multimodal LLM for Better Handling of Text-Rich Visual Questions
Aug 19, 2023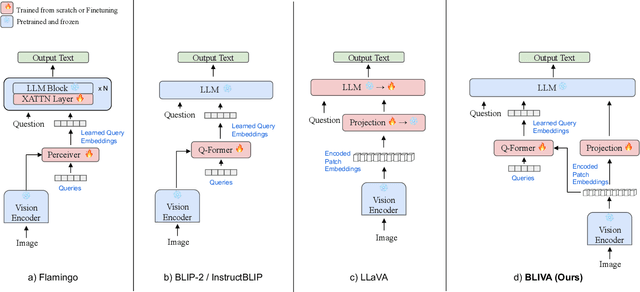
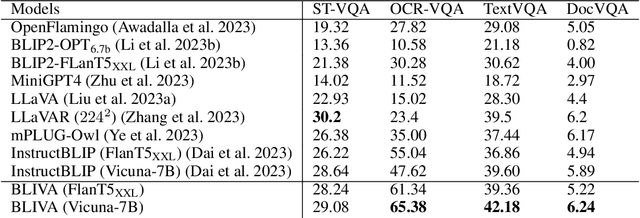

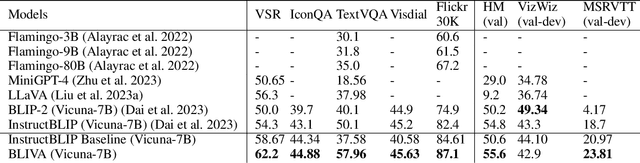
Vision Language Models (VLMs), which extend Large Language Models (LLM) by incorporating visual understanding capability, have demonstrated significant advancements in addressing open-ended visual question-answering (VQA) tasks. However, these models cannot accurately interpret images infused with text, a common occurrence in real-world scenarios. Standard procedures for extracting information from images often involve learning a fixed set of query embeddings. These embeddings are designed to encapsulate image contexts and are later used as soft prompt inputs in LLMs. Yet, this process is limited to the token count, potentially curtailing the recognition of scenes with text-rich context. To improve upon them, the present study introduces BLIVA: an augmented version of InstructBLIP with Visual Assistant. BLIVA incorporates the query embeddings from InstructBLIP and also directly projects encoded patch embeddings into the LLM, a technique inspired by LLaVA. This approach assists the model to capture intricate details potentially missed during the query decoding process. Empirical evidence demonstrates that our model, BLIVA, significantly enhances performance in processing text-rich VQA benchmarks (up to 17.76\% in OCR-VQA benchmark) and in undertaking typical VQA benchmarks (up to 7.9\% in Visual Spatial Reasoning benchmark), comparing to our baseline InstructBLIP. BLIVA demonstrates significant capability in decoding real-world images, irrespective of text presence. To demonstrate the broad industry applications enabled by BLIVA, we evaluate the model using a new dataset comprising YouTube thumbnails paired with question-answer sets across 13 diverse categories. For researchers interested in further exploration, our code and models are freely accessible at https://github.com/mlpc-ucsd/BLIVA.git
Tri-MipRF: Tri-Mip Representation for Efficient Anti-Aliasing Neural Radiance Fields
Jul 21, 2023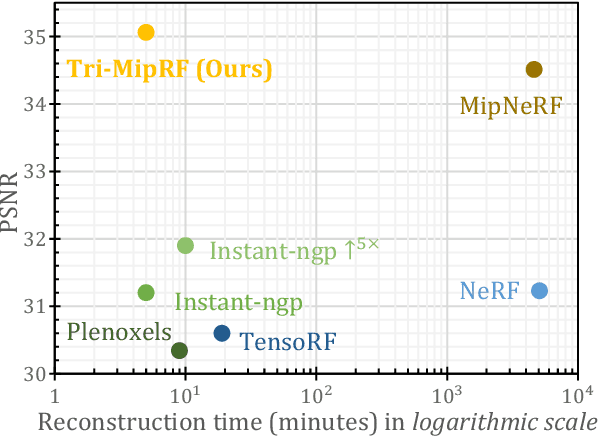
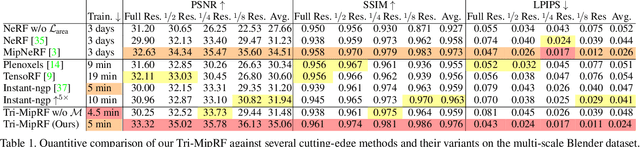
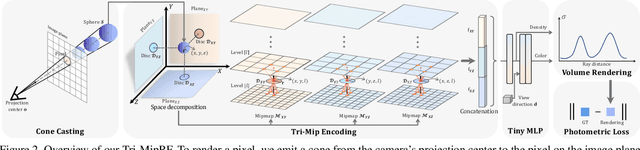

Despite the tremendous progress in neural radiance fields (NeRF), we still face a dilemma of the trade-off between quality and efficiency, e.g., MipNeRF presents fine-detailed and anti-aliased renderings but takes days for training, while Instant-ngp can accomplish the reconstruction in a few minutes but suffers from blurring or aliasing when rendering at various distances or resolutions due to ignoring the sampling area. To this end, we propose a novel Tri-Mip encoding that enables both instant reconstruction and anti-aliased high-fidelity rendering for neural radiance fields. The key is to factorize the pre-filtered 3D feature spaces in three orthogonal mipmaps. In this way, we can efficiently perform 3D area sampling by taking advantage of 2D pre-filtered feature maps, which significantly elevates the rendering quality without sacrificing efficiency. To cope with the novel Tri-Mip representation, we propose a cone-casting rendering technique to efficiently sample anti-aliased 3D features with the Tri-Mip encoding considering both pixel imaging and observing distance. Extensive experiments on both synthetic and real-world datasets demonstrate our method achieves state-of-the-art rendering quality and reconstruction speed while maintaining a compact representation that reduces 25% model size compared against Instant-ngp.
* Accepted to ICCV 2023 Project page: https://wbhu.github.io/projects/Tri-MipRF