 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJianfei Chen
SparseDM: Toward Sparse Efficient Diffusion Models
Apr 16, 2024
Diffusion models have been extensively used in data generation tasks and are recognized as one of the best generative models. However, their time-consuming deployment, long inference time, and requirements on large memory limit their application on mobile devices. In this paper, we propose a method based on the improved Straight-Through Estimator to improve the deployment efficiency of diffusion models. Specifically, we add sparse masks to the Convolution and Linear layers in a pre-trained diffusion model, then use design progressive sparsity for model training in the fine-tuning stage, and switch the inference mask on and off, which supports a flexible choice of sparsity during inference according to the FID and MACs requirements. Experiments on four datasets conducted on a state-of-the-art Transformer-based diffusion model demonstrate that our method reduces MACs by $50\%$ while increasing FID by only 1.5 on average. Under other MACs conditions, the FID is also lower than 1$\sim$137 compared to other methods.
Accelerating Transformer Pre-Training with 2:4 Sparsity
Apr 02, 2024Training large Transformers is slow, but recent innovations on GPU architecture gives us an advantage. NVIDIA Ampere GPUs can execute a fine-grained 2:4 sparse matrix multiplication twice as fast as its dense equivalent. In the light of this property, we comprehensively investigate the feasibility of accelerating feed-forward networks (FFNs) of Transformers in pre-training. First, we define a "flip rate" to monitor the stability of a 2:4 training process. Utilizing this metric, we suggest two techniques to preserve accuracy: to modify the sparse-refined straight-through estimator by applying the mask decay term on gradients, and to enhance the model's quality by a simple yet effective dense fine-tuning procedure near the end of pre-training. Besides, we devise two effective techniques to practically accelerate training: to calculate transposable 2:4 mask by convolution, and to accelerate gated activation functions by reducing GPU L2 cache miss. Experiments show that a combination of our methods reaches the best performance on multiple Transformers among different 2:4 training methods, while actual acceleration can be observed on different shapes of Transformer block.
Jetfire: Efficient and Accurate Transformer Pretraining with INT8 Data Flow and Per-Block Quantization
Mar 19, 2024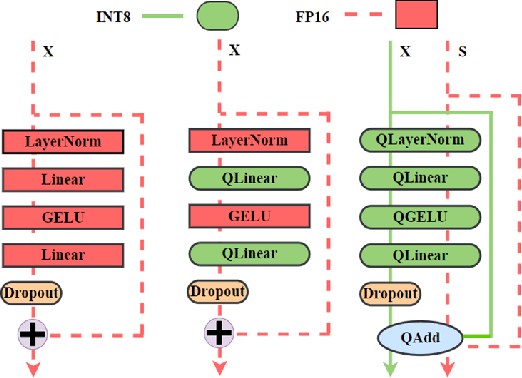

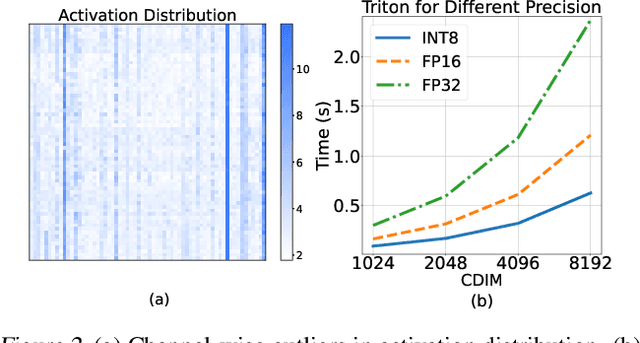
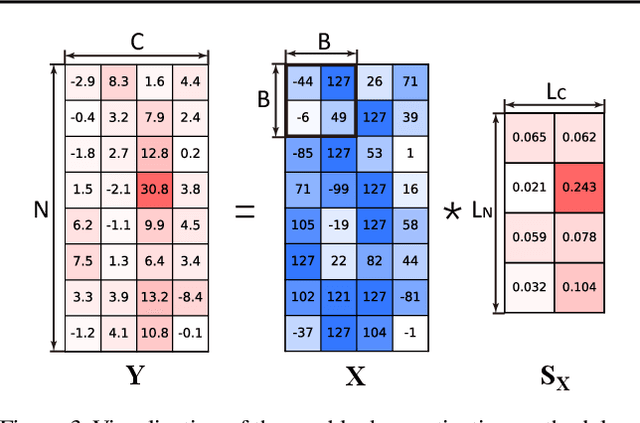
Pretraining transformers are generally time-consuming. Fully quantized training (FQT) is a promising approach to speed up pretraining. However, most FQT methods adopt a quantize-compute-dequantize procedure, which often leads to suboptimal speedup and significant performance degradation when used in transformers due to the high memory access overheads and low-precision computations. In this work, we propose Jetfire, an efficient and accurate INT8 training method specific to transformers. Our method features an INT8 data flow to optimize memory access and a per-block quantization method to maintain the accuracy of pretrained transformers. Extensive experiments demonstrate that our INT8 FQT method achieves comparable accuracy to the FP16 training baseline and outperforms the existing INT8 training works for transformers. Moreover, for a standard transformer block, our method offers an end-to-end training speedup of 1.42x and a 1.49x memory reduction compared to the FP16 baseline.
Efficient Backpropagation with Variance-Controlled Adaptive Sampling
Feb 27, 2024Sampling-based algorithms, which eliminate ''unimportant'' computations during forward and/or back propagation (BP), offer potential solutions to accelerate neural network training. However, since sampling introduces approximations to training, such algorithms may not consistently maintain accuracy across various tasks. In this work, we introduce a variance-controlled adaptive sampling (VCAS) method designed to accelerate BP. VCAS computes an unbiased stochastic gradient with fine-grained layerwise importance sampling in data dimension for activation gradient calculation and leverage score sampling in token dimension for weight gradient calculation. To preserve accuracy, we control the additional variance by learning the sample ratio jointly with model parameters during training. We assessed VCAS on multiple fine-tuning and pre-training tasks in both vision and natural language domains. On all the tasks, VCAS can preserve the original training loss trajectory and validation accuracy with an up to 73.87% FLOPs reduction of BP and 49.58% FLOPs reduction of the whole training process. The implementation is available at https://github.com/thu-ml/VCAS .
C-GAIL: Stabilizing Generative Adversarial Imitation Learning with Control Theory
Feb 26, 2024Generative Adversarial Imitation Learning (GAIL) trains a generative policy to mimic a demonstrator. It uses on-policy Reinforcement Learning (RL) to optimize a reward signal derived from a GAN-like discriminator. A major drawback of GAIL is its training instability - it inherits the complex training dynamics of GANs, and the distribution shift introduced by RL. This can cause oscillations during training, harming its sample efficiency and final policy performance. Recent work has shown that control theory can help with the convergence of a GAN's training. This paper extends this line of work, conducting a control-theoretic analysis of GAIL and deriving a novel controller that not only pushes GAIL to the desired equilibrium but also achieves asymptotic stability in a 'one-step' setting. Based on this, we propose a practical algorithm 'Controlled-GAIL' (C-GAIL). On MuJoCo tasks, our controlled variant is able to speed up the rate of convergence, reduce the range of oscillation and match the expert's distribution more closely both for vanilla GAIL and GAIL-DAC.
DPM-Solver-v3: Improved Diffusion ODE Solver with Empirical Model Statistics
Oct 28, 2023Diffusion probabilistic models (DPMs) have exhibited excellent performance for high-fidelity image generation while suffering from inefficient sampling. Recent works accelerate the sampling procedure by proposing fast ODE solvers that leverage the specific ODE form of DPMs. However, they highly rely on specific parameterization during inference (such as noise/data prediction), which might not be the optimal choice. In this work, we propose a novel formulation towards the optimal parameterization during sampling that minimizes the first-order discretization error of the ODE solution. Based on such formulation, we propose DPM-Solver-v3, a new fast ODE solver for DPMs by introducing several coefficients efficiently computed on the pretrained model, which we call empirical model statistics. We further incorporate multistep methods and a predictor-corrector framework, and propose some techniques for improving sample quality at small numbers of function evaluations (NFE) or large guidance scales. Experiments show that DPM-Solver-v3 achieves consistently better or comparable performance in both unconditional and conditional sampling with both pixel-space and latent-space DPMs, especially in 5$\sim$10 NFEs. We achieve FIDs of 12.21 (5 NFE), 2.51 (10 NFE) on unconditional CIFAR10, and MSE of 0.55 (5 NFE, 7.5 guidance scale) on Stable Diffusion, bringing a speed-up of 15%$\sim$30% compared to previous state-of-the-art training-free methods. Code is available at https://github.com/thu-ml/DPM-Solver-v3.
Investigating Uncertainty Calibration of Aligned Language Models under the Multiple-Choice Setting
Oct 18, 2023Despite the significant progress made in practical applications of aligned language models (LMs), they tend to be overconfident in output answers compared to the corresponding pre-trained LMs. In this work, we systematically evaluate the impact of the alignment process on logit-based uncertainty calibration of LMs under the multiple-choice setting. We first conduct a thoughtful empirical study on how aligned LMs differ in calibration from their pre-trained counterparts. Experimental results reveal that there are two distinct uncertainties in LMs under the multiple-choice setting, which are responsible for the answer decision and the format preference of the LMs, respectively. Then, we investigate the role of these two uncertainties on aligned LM's calibration through fine-tuning in simple synthetic alignment schemes and conclude that one reason for aligned LMs' overconfidence is the conflation of these two types of uncertainty. Furthermore, we examine the utility of common post-hoc calibration methods for aligned LMs and propose an easy-to-implement and sample-efficient method to calibrate aligned LMs. We hope our findings could provide insights into the design of more reliable alignment processes for LMs.
Memory Efficient Optimizers with 4-bit States
Sep 06, 2023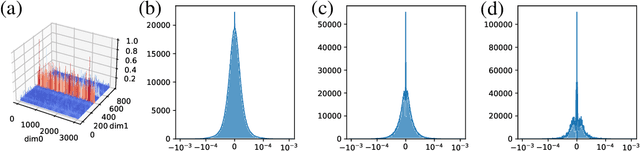
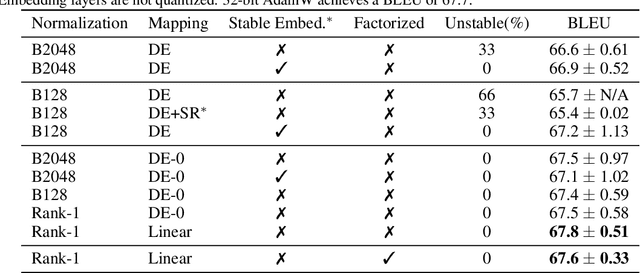
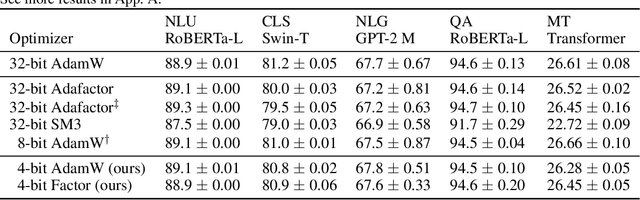
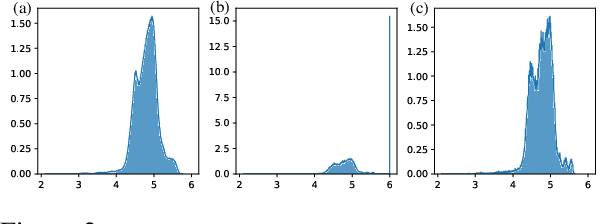
Optimizer states are a major source of memory consumption for training neural networks, limiting the maximum trainable model within given memory budget. Compressing the optimizer states from 32-bit floating points to lower bitwidth is promising to reduce the training memory footprint, while the current lowest achievable bitwidth is 8-bit. In this work, we push optimizer states bitwidth down to 4-bit through a detailed empirical analysis of first and second moments. Specifically, we find that moments have complicated outlier patterns, that current block-wise quantization cannot accurately approximate. We use a smaller block size and propose to utilize both row-wise and column-wise information for better quantization. We further identify a zero point problem of quantizing the second moment, and solve this problem with a linear quantizer that excludes the zero point. Our 4-bit optimizer is evaluated on a wide variety of benchmarks including natural language understanding, machine translation, image classification, and instruction tuning. On all the tasks our optimizers can achieve comparable accuracy with their full-precision counterparts, while enjoying better memory efficiency.
Training Transformers with 4-bit Integers
Jun 22, 2023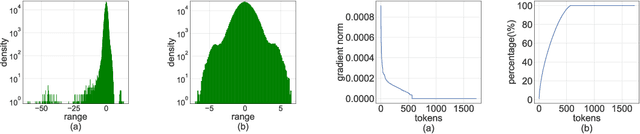
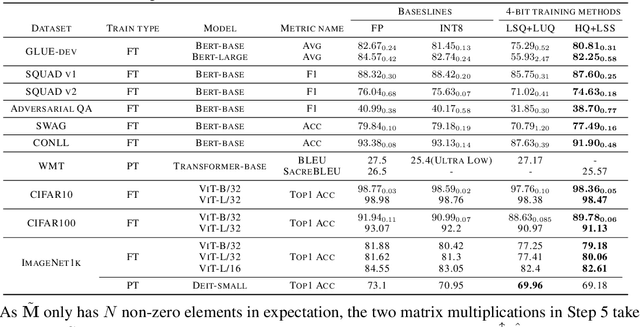
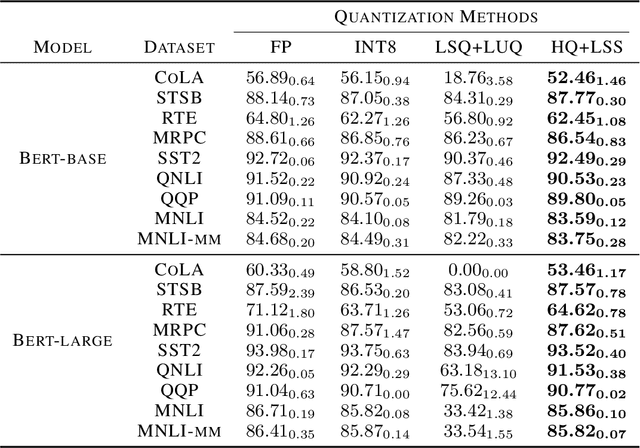
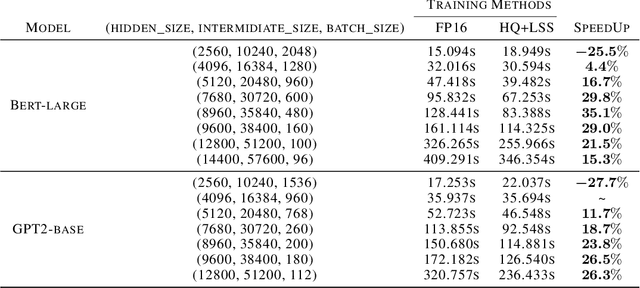
Quantizing the activation, weight, and gradient to 4-bit is promising to accelerate neural network training. However, existing 4-bit training methods require custom numerical formats which are not supported by contemporary hardware. In this work, we propose a training method for transformers with all matrix multiplications implemented with the INT4 arithmetic. Training with an ultra-low INT4 precision is challenging. To achieve this, we carefully analyze the specific structures of activation and gradients in transformers to propose dedicated quantizers for them. For forward propagation, we identify the challenge of outliers and propose a Hadamard quantizer to suppress the outliers. For backpropagation, we leverage the structural sparsity of gradients by proposing bit splitting and leverage score sampling techniques to quantize gradients accurately. Our algorithm achieves competitive accuracy on a wide range of tasks including natural language understanding, machine translation, and image classification. Unlike previous 4-bit training methods, our algorithm can be implemented on the current generation of GPUs. Our prototypical linear operator implementation is up to 2.2 times faster than the FP16 counterparts and speeds up the training by up to 35.1%.
Stabilizing GANs' Training with Brownian Motion Controller
Jun 18, 2023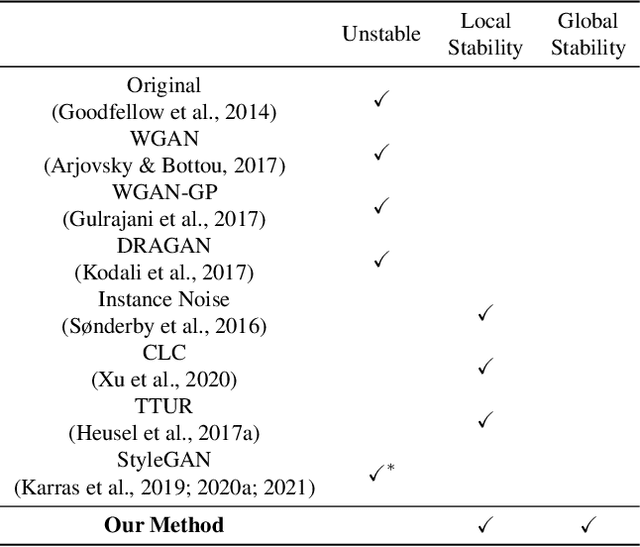

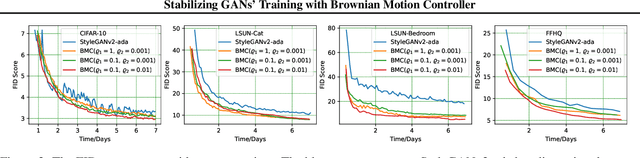

The training process of generative adversarial networks (GANs) is unstable and does not converge globally. In this paper, we examine the stability of GANs from the perspective of control theory and propose a universal higher-order noise-based controller called Brownian Motion Controller (BMC). Starting with the prototypical case of Dirac-GANs, we design a BMC to retrieve precisely the same but reachable optimal equilibrium. We theoretically prove that the training process of DiracGANs-BMC is globally exponential stable and derive bounds on the rate of convergence. Then we extend our BMC to normal GANs and provide implementation instructions on GANs-BMC. Our experiments show that our GANs-BMC effectively stabilizes GANs' training under StyleGANv2-ada frameworks with a faster rate of convergence, a smaller range of oscillation, and better performance in terms of FID score.