 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLin Gao
DeferredGS: Decoupled and Editable Gaussian Splatting with Deferred Shading
Apr 15, 2024
Reconstructing and editing 3D objects and scenes both play crucial roles in computer graphics and computer vision. Neural radiance fields (NeRFs) can achieve realistic reconstruction and editing results but suffer from inefficiency in rendering. Gaussian splatting significantly accelerates rendering by rasterizing Gaussian ellipsoids. However, Gaussian splatting utilizes a single Spherical Harmonic (SH) function to model both texture and lighting, limiting independent editing capabilities of these components. Recently, attempts have been made to decouple texture and lighting with the Gaussian splatting representation but may fail to produce plausible geometry and decomposition results on reflective scenes. Additionally, the forward shading technique they employ introduces noticeable blending artifacts during relighting, as the geometry attributes of Gaussians are optimized under the original illumination and may not be suitable for novel lighting conditions. To address these issues, we introduce DeferredGS, a method for decoupling and editing the Gaussian splatting representation using deferred shading. To achieve successful decoupling, we model the illumination with a learnable environment map and define additional attributes such as texture parameters and normal direction on Gaussians, where the normal is distilled from a jointly trained signed distance function. More importantly, we apply deferred shading, resulting in more realistic relighting effects compared to previous methods. Both qualitative and quantitative experiments demonstrate the superior performance of DeferredGS in novel view synthesis and editing tasks.
StylizedGS: Controllable Stylization for 3D Gaussian Splatting
Apr 08, 2024With the rapid development of XR, 3D generation and editing are becoming more and more important, among which, stylization is an important tool of 3D appearance editing. It can achieve consistent 3D artistic stylization given a single reference style image and thus is a user-friendly editing way. However, recent NeRF-based 3D stylization methods face efficiency issues that affect the actual user experience and the implicit nature limits its ability to transfer the geometric pattern styles. Additionally, the ability for artists to exert flexible control over stylized scenes is considered highly desirable, fostering an environment conducive to creative exploration. In this paper, we introduce StylizedGS, a 3D neural style transfer framework with adaptable control over perceptual factors based on 3D Gaussian Splatting (3DGS) representation. The 3DGS brings the benefits of high efficiency. We propose a GS filter to eliminate floaters in the reconstruction which affects the stylization effects before stylization. Then the nearest neighbor-based style loss is introduced to achieve stylization by fine-tuning the geometry and color parameters of 3DGS, while a depth preservation loss with other regularizations is proposed to prevent the tampering of geometry content. Moreover, facilitated by specially designed losses, StylizedGS enables users to control color, stylized scale and regions during the stylization to possess customized capabilities. Our method can attain high-quality stylization results characterized by faithful brushstrokes and geometric consistency with flexible controls. Extensive experiments across various scenes and styles demonstrate the effectiveness and efficiency of our method concerning both stylization quality and inference FPS.
Recent Advances in 3D Gaussian Splatting
Mar 17, 2024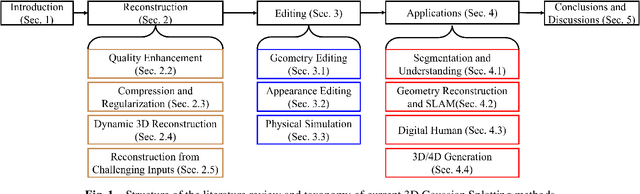
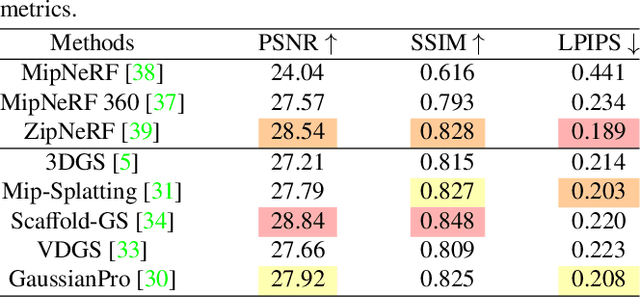
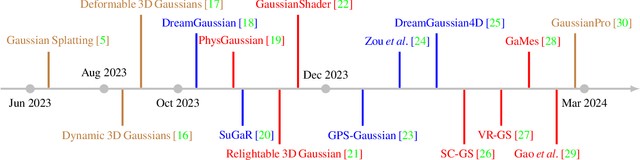
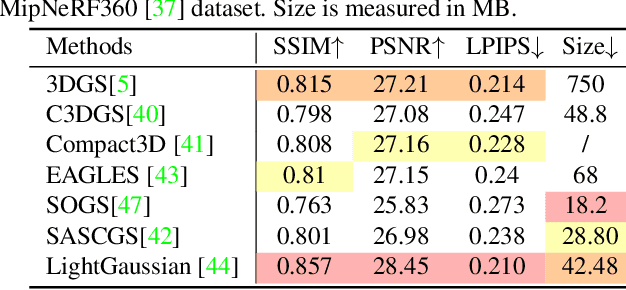
The emergence of 3D Gaussian Splatting (3DGS) has greatly accelerated the rendering speed of novel view synthesis. Unlike neural implicit representations like Neural Radiance Fields (NeRF) that represent a 3D scene with position and viewpoint-conditioned neural networks, 3D Gaussian Splatting utilizes a set of Gaussian ellipsoids to model the scene so that efficient rendering can be accomplished by rasterizing Gaussian ellipsoids into images. Apart from the fast rendering speed, the explicit representation of 3D Gaussian Splatting facilitates editing tasks like dynamic reconstruction, geometry editing, and physical simulation. Considering the rapid change and growing number of works in this field, we present a literature review of recent 3D Gaussian Splatting methods, which can be roughly classified into 3D reconstruction, 3D editing, and other downstream applications by functionality. Traditional point-based rendering methods and the rendering formulation of 3D Gaussian Splatting are also illustrated for a better understanding of this technique. This survey aims to help beginners get into this field quickly and provide experienced researchers with a comprehensive overview, which can stimulate the future development of the 3D Gaussian Splatting representation.
Unsigned Orthogonal Distance Fields: An Accurate Neural Implicit Representation for Diverse 3D Shapes
Mar 03, 2024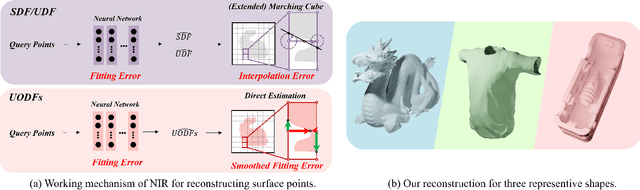
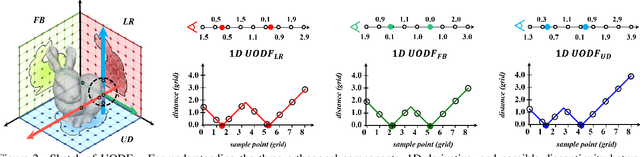
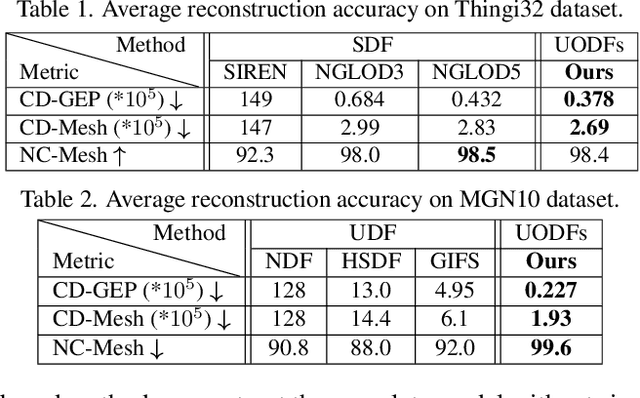
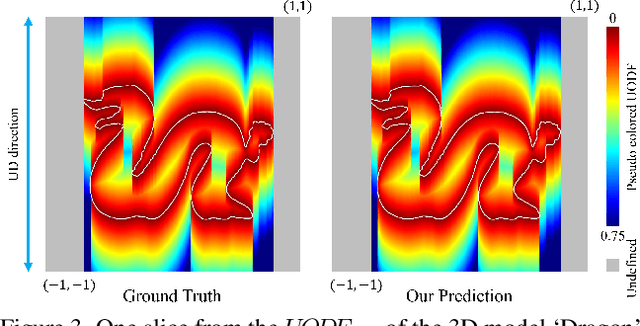
Neural implicit representation of geometric shapes has witnessed considerable advancements in recent years. However, common distance field based implicit representations, specifically signed distance field (SDF) for watertight shapes or unsigned distance field (UDF) for arbitrary shapes, routinely suffer from degradation of reconstruction accuracy when converting to explicit surface points and meshes. In this paper, we introduce a novel neural implicit representation based on unsigned orthogonal distance fields (UODFs). In UODFs, the minimal unsigned distance from any spatial point to the shape surface is defined solely in one orthogonal direction, contrasting with the multi-directional determination made by SDF and UDF. Consequently, every point in the 3D UODFs can directly access its closest surface points along three orthogonal directions. This distinctive feature leverages the accurate reconstruction of surface points without interpolation errors. We verify the effectiveness of UODFs through a range of reconstruction examples, extending from simple watertight or non-watertight shapes to complex shapes that include hollows, internal or assembling structures.
Mesh-based Gaussian Splatting for Real-time Large-scale Deformation
Feb 07, 2024Neural implicit representations, including Neural Distance Fields and Neural Radiance Fields, have demonstrated significant capabilities for reconstructing surfaces with complicated geometry and topology, and generating novel views of a scene. Nevertheless, it is challenging for users to directly deform or manipulate these implicit representations with large deformations in the real-time fashion. Gaussian Splatting(GS) has recently become a promising method with explicit geometry for representing static scenes and facilitating high-quality and real-time synthesis of novel views. However,it cannot be easily deformed due to the use of discrete Gaussians and lack of explicit topology. To address this, we develop a novel GS-based method that enables interactive deformation. Our key idea is to design an innovative mesh-based GS representation, which is integrated into Gaussian learning and manipulation. 3D Gaussians are defined over an explicit mesh, and they are bound with each other: the rendering of 3D Gaussians guides the mesh face split for adaptive refinement, and the mesh face split directs the splitting of 3D Gaussians. Moreover, the explicit mesh constraints help regularize the Gaussian distribution, suppressing poor-quality Gaussians(e.g. misaligned Gaussians,long-narrow shaped Gaussians), thus enhancing visual quality and avoiding artifacts during deformation. Based on this representation, we further introduce a large-scale Gaussian deformation technique to enable deformable GS, which alters the parameters of 3D Gaussians according to the manipulation of the associated mesh. Our method benefits from existing mesh deformation datasets for more realistic data-driven Gaussian deformation. Extensive experiments show that our approach achieves high-quality reconstruction and effective deformation, while maintaining the promising rendering results at a high frame rate(65 FPS on average).
Retargeting Visual Data with Deformation Fields
Nov 22, 2023Seam carving is an image editing method that enable content-aware resizing, including operations like removing objects. However, the seam-finding strategy based on dynamic programming or graph-cut limits its applications to broader visual data formats and degrees of freedom for editing. Our observation is that describing the editing and retargeting of images more generally by a displacement field yields a generalisation of content-aware deformations. We propose to learn a deformation with a neural network that keeps the output plausible while trying to deform it only in places with low information content. This technique applies to different kinds of visual data, including images, 3D scenes given as neural radiance fields, or even polygon meshes. Experiments conducted on different visual data show that our method achieves better content-aware retargeting compared to previous methods.
Tri-MipRF: Tri-Mip Representation for Efficient Anti-Aliasing Neural Radiance Fields
Jul 21, 2023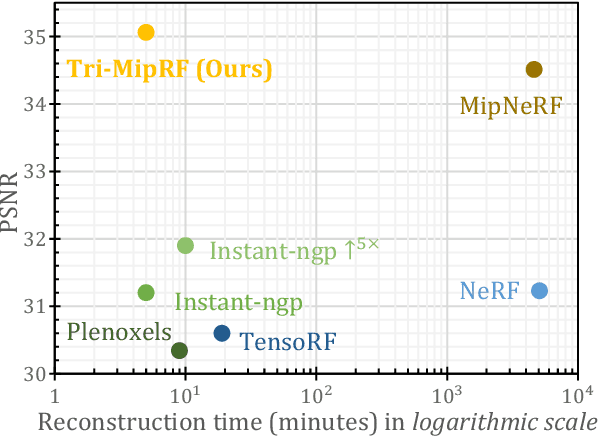
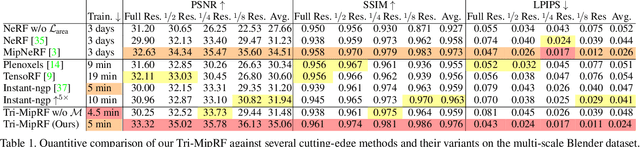
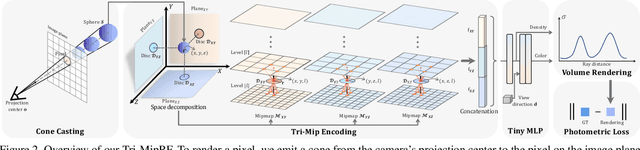

Despite the tremendous progress in neural radiance fields (NeRF), we still face a dilemma of the trade-off between quality and efficiency, e.g., MipNeRF presents fine-detailed and anti-aliased renderings but takes days for training, while Instant-ngp can accomplish the reconstruction in a few minutes but suffers from blurring or aliasing when rendering at various distances or resolutions due to ignoring the sampling area. To this end, we propose a novel Tri-Mip encoding that enables both instant reconstruction and anti-aliased high-fidelity rendering for neural radiance fields. The key is to factorize the pre-filtered 3D feature spaces in three orthogonal mipmaps. In this way, we can efficiently perform 3D area sampling by taking advantage of 2D pre-filtered feature maps, which significantly elevates the rendering quality without sacrificing efficiency. To cope with the novel Tri-Mip representation, we propose a cone-casting rendering technique to efficiently sample anti-aliased 3D features with the Tri-Mip encoding considering both pixel imaging and observing distance. Extensive experiments on both synthetic and real-world datasets demonstrate our method achieves state-of-the-art rendering quality and reconstruction speed while maintaining a compact representation that reduces 25% model size compared against Instant-ngp.
* Accepted to ICCV 2023 Project page: https://wbhu.github.io/projects/Tri-MipRF
Sketch Beautification: Learning Part Beautification and Structure Refinement for Sketches of Man-made Objects
Jun 09, 2023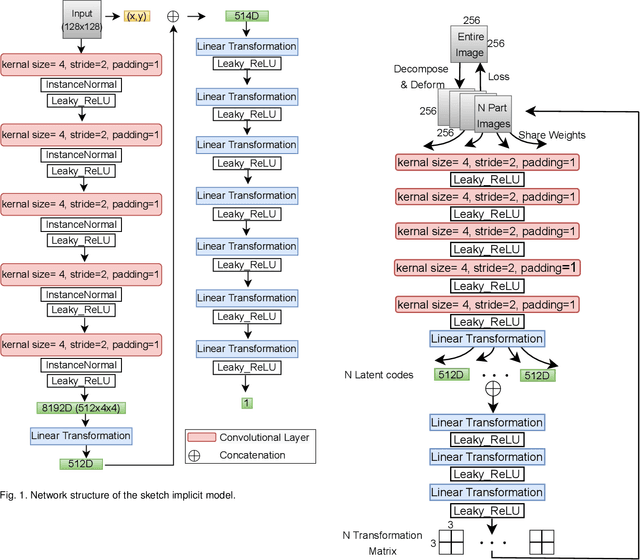
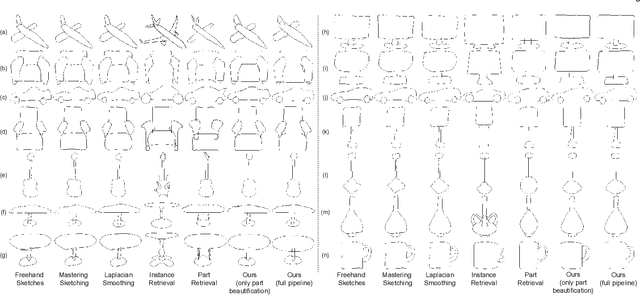
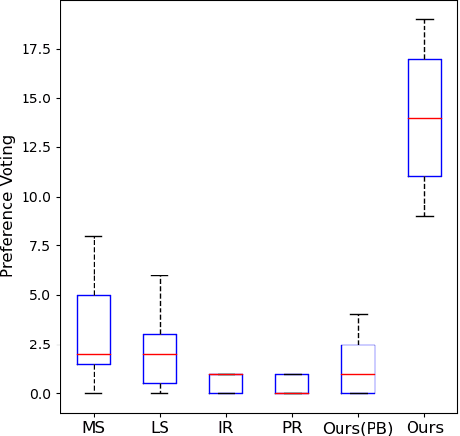
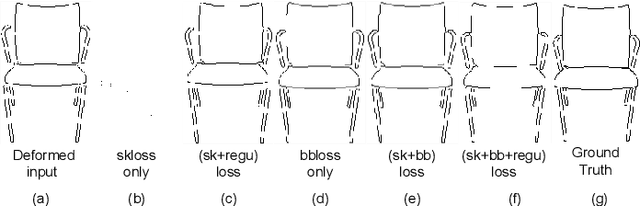
We present a novel freehand sketch beautification method, which takes as input a freely drawn sketch of a man-made object and automatically beautifies it both geometrically and structurally. Beautifying a sketch is challenging because of its highly abstract and heavily diverse drawing manner. Existing methods are usually confined to the distribution of their limited training samples and thus cannot beautify freely drawn sketches with rich variations. To address this challenge, we adopt a divide-and-combine strategy. Specifically, we first parse an input sketch into semantic components, beautify individual components by a learned part beautification module based on part-level implicit manifolds, and then reassemble the beautified components through a structure beautification module. With this strategy, our method can go beyond the training samples and handle novel freehand sketches. We demonstrate the effectiveness of our system with extensive experiments and a perceptive study.
NeUDF: Leaning Neural Unsigned Distance Fields with Volume Rendering
Apr 20, 2023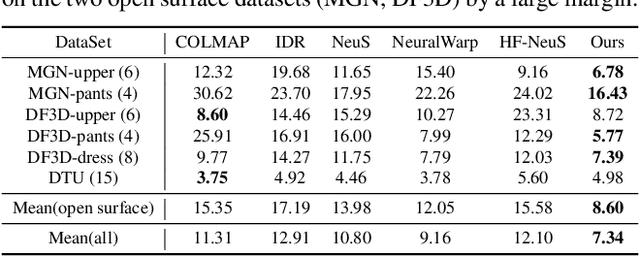
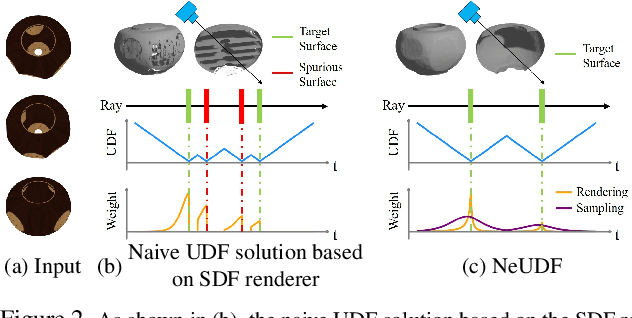
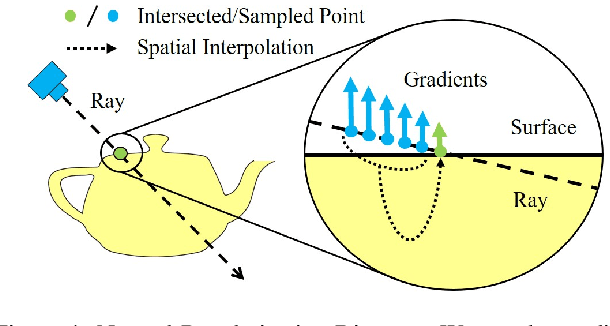

Multi-view shape reconstruction has achieved impressive progresses thanks to the latest advances in neural implicit surface rendering. However, existing methods based on signed distance function (SDF) are limited to closed surfaces, failing to reconstruct a wide range of real-world objects that contain open-surface structures. In this work, we introduce a new neural rendering framework, coded NeUDF, that can reconstruct surfaces with arbitrary topologies solely from multi-view supervision. To gain the flexibility of representing arbitrary surfaces, NeUDF leverages the unsigned distance function (UDF) as surface representation. While a naive extension of an SDF-based neural renderer cannot scale to UDF, we propose two new formulations of weight function specially tailored for UDF-based volume rendering. Furthermore, to cope with open surface rendering, where the in/out test is no longer valid, we present a dedicated normal regularization strategy to resolve the surface orientation ambiguity. We extensively evaluate our method over a number of challenging datasets, including DTU}, MGN, and Deep Fashion 3D. Experimental results demonstrate that nEudf can significantly outperform the state-of-the-art method in the task of multi-view surface reconstruction, especially for complex shapes with open boundaries.
LC-NeRF: Local Controllable Face Generation in Neural Randiance Field
Feb 19, 2023
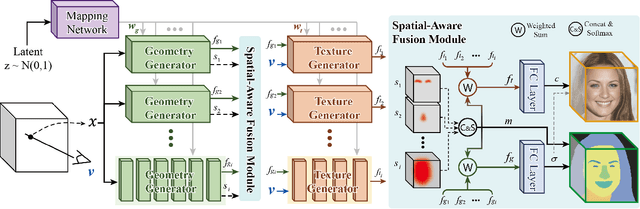
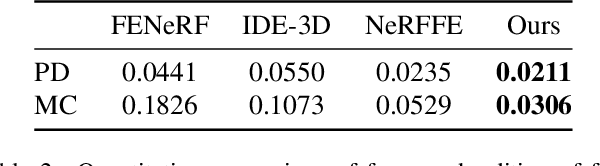

3D face generation has achieved high visual quality and 3D consistency thanks to the development of neural radiance fields (NeRF). Recently, to generate and edit 3D faces with NeRF representation, some methods are proposed and achieve good results in decoupling geometry and texture. The latent codes of these generative models affect the whole face, and hence modifications to these codes cause the entire face to change. However, users usually edit a local region when editing faces and do not want other regions to be affected. Since changes to the latent code affect global generation results, these methods do not allow for fine-grained control of local facial regions. To improve local controllability in NeRF-based face editing, we propose LC-NeRF, which is composed of a Local Region Generators Module and a Spatial-Aware Fusion Module, allowing for local geometry and texture control of local facial regions. Qualitative and quantitative evaluations show that our method provides better local editing than state-of-the-art face editing methods. Our method also performs well in downstream tasks, such as text-driven facial image editing.