 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFang-Lue Zhang
StylizedGS: Controllable Stylization for 3D Gaussian Splatting
Apr 08, 2024
With the rapid development of XR, 3D generation and editing are becoming more and more important, among which, stylization is an important tool of 3D appearance editing. It can achieve consistent 3D artistic stylization given a single reference style image and thus is a user-friendly editing way. However, recent NeRF-based 3D stylization methods face efficiency issues that affect the actual user experience and the implicit nature limits its ability to transfer the geometric pattern styles. Additionally, the ability for artists to exert flexible control over stylized scenes is considered highly desirable, fostering an environment conducive to creative exploration. In this paper, we introduce StylizedGS, a 3D neural style transfer framework with adaptable control over perceptual factors based on 3D Gaussian Splatting (3DGS) representation. The 3DGS brings the benefits of high efficiency. We propose a GS filter to eliminate floaters in the reconstruction which affects the stylization effects before stylization. Then the nearest neighbor-based style loss is introduced to achieve stylization by fine-tuning the geometry and color parameters of 3DGS, while a depth preservation loss with other regularizations is proposed to prevent the tampering of geometry content. Moreover, facilitated by specially designed losses, StylizedGS enables users to control color, stylized scale and regions during the stylization to possess customized capabilities. Our method can attain high-quality stylization results characterized by faithful brushstrokes and geometric consistency with flexible controls. Extensive experiments across various scenes and styles demonstrate the effectiveness and efficiency of our method concerning both stylization quality and inference FPS.
MAL: Motion-Aware Loss with Temporal and Distillation Hints for Self-Supervised Depth Estimation
Feb 18, 2024Depth perception is crucial for a wide range of robotic applications. Multi-frame self-supervised depth estimation methods have gained research interest due to their ability to leverage large-scale, unlabeled real-world data. However, the self-supervised methods often rely on the assumption of a static scene and their performance tends to degrade in dynamic environments. To address this issue, we present Motion-Aware Loss, which leverages the temporal relation among consecutive input frames and a novel distillation scheme between the teacher and student networks in the multi-frame self-supervised depth estimation methods. Specifically, we associate the spatial locations of moving objects with the temporal order of input frames to eliminate errors induced by object motion. Meanwhile, we enhance the original distillation scheme in multi-frame methods to better exploit the knowledge from a teacher network. MAL is a novel, plug-and-play module designed for seamless integration into multi-frame self-supervised monocular depth estimation methods. Adding MAL into previous state-of-the-art methods leads to a reduction in depth estimation errors by up to 4.2% and 10.8% on KITTI and CityScapes benchmarks, respectively.
PPEA-Depth: Progressive Parameter-Efficient Adaptation for Self-Supervised Monocular Depth Estimation
Jan 17, 2024Self-supervised monocular depth estimation is of significant importance with applications spanning across autonomous driving and robotics. However, the reliance on self-supervision introduces a strong static-scene assumption, thereby posing challenges in achieving optimal performance in dynamic scenes, which are prevalent in most real-world situations. To address these issues, we propose PPEA-Depth, a Progressive Parameter-Efficient Adaptation approach to transfer a pre-trained image model for self-supervised depth estimation. The training comprises two sequential stages: an initial phase trained on a dataset primarily composed of static scenes, succeeded by an expansion to more intricate datasets involving dynamic scenes. To facilitate this process, we design compact encoder and decoder adapters to enable parameter-efficient tuning, allowing the network to adapt effectively. They not only uphold generalized patterns from pre-trained image models but also retain knowledge gained from the preceding phase into the subsequent one. Extensive experiments demonstrate that PPEA-Depth achieves state-of-the-art performance on KITTI, CityScapes and DDAD datasets.
Deep 360$^\circ$ Optical Flow Estimation Based on Multi-Projection Fusion
Jul 27, 2022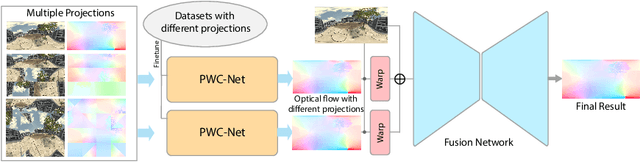


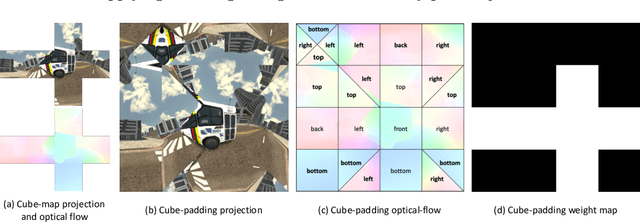
Optical flow computation is essential in the early stages of the video processing pipeline. This paper focuses on a less explored problem in this area, the 360$^\circ$ optical flow estimation using deep neural networks to support increasingly popular VR applications. To address the distortions of panoramic representations when applying convolutional neural networks, we propose a novel multi-projection fusion framework that fuses the optical flow predicted by the models trained using different projection methods. It learns to combine the complementary information in the optical flow results under different projections. We also build the first large-scale panoramic optical flow dataset to support the training of neural networks and the evaluation of panoramic optical flow estimation methods. The experimental results on our dataset demonstrate that our method outperforms the existing methods and other alternative deep networks that were developed for processing 360{\deg} content.
Casual 6-DoF: free-viewpoint panorama using a handheld 360 camera
Mar 31, 2022

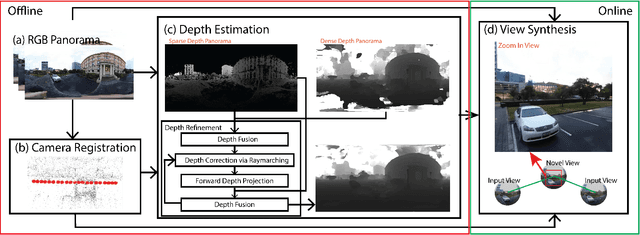
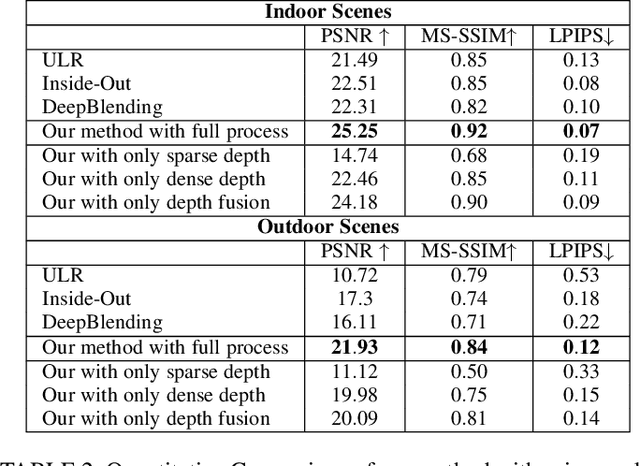
Six degrees-of-freedom (6-DoF) video provides telepresence by enabling users to move around in the captured scene with a wide field of regard. Compared to methods requiring sophisticated camera setups, the image-based rendering method based on photogrammetry can work with images captured with any poses, which is more suitable for casual users. However, existing image-based rendering methods are based on perspective images. When used to reconstruct 6-DoF views, it often requires capturing hundreds of images, making data capture a tedious and time-consuming process. In contrast to traditional perspective images, 360{\deg} images capture the entire surrounding view in a single shot, thus, providing a faster capturing process for 6-DoF view reconstruction. This paper presents a novel method to provide 6-DoF experiences over a wide area using an unstructured collection of 360{\deg} panoramas captured by a conventional 360{\deg} camera. Our method consists of 360{\deg} data capturing, novel depth estimation to produce a high-quality spherical depth panorama, and high-fidelity free-viewpoint generation. We compared our method against state-of-the-art methods, using data captured in various environments. Our method shows better visual quality and robustness in the tested scenes.
RISA-Net: Rotation-Invariant Structure-Aware Network for Fine-Grained 3D Shape Retrieval
Oct 02, 2020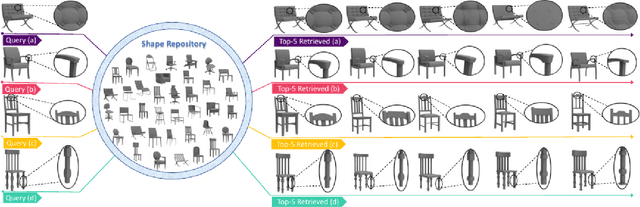

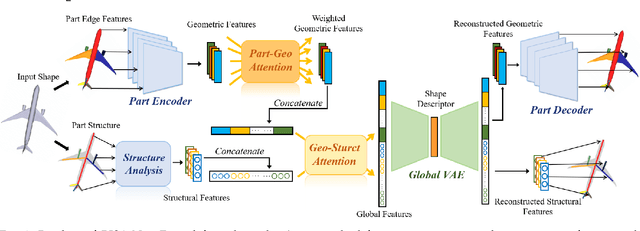

Fine-grained 3D shape retrieval aims to retrieve 3D shapes similar to a query shape in a repository with models belonging to the same class, which requires shape descriptors to be capable of representing detailed geometric information to discriminate shapes with globally similar structures. Moreover, 3D objects can be placed with arbitrary position and orientation in real-world applications, which further requires shape descriptors to be robust to rigid transformations. The shape descriptions used in existing 3D shape retrieval systems fail to meet the above two criteria. In this paper, we introduce a novel deep architecture, RISA-Net, which learns rotation invariant 3D shape descriptors that are capable of encoding fine-grained geometric information and structural information, and thus achieve accurate results on the task of fine-grained 3D object retrieval. RISA-Net extracts a set of compact and detailed geometric features part-wisely and discriminatively estimates the contribution of each semantic part to shape representation. Furthermore, our method is able to learn the importance of geometric and structural information of all the parts when generating the final compact latent feature of a 3D shape for fine-grained retrieval. We also build and publish a new 3D shape dataset with sub-class labels for validating the performance of fine-grained 3D shape retrieval methods. Qualitative and quantitative experiments show that our RISA-Net outperforms state-of-the-art methods on the fine-grained object retrieval task, demonstrating its capability in geometric detail extraction. The code and dataset are available at: https://github.com/IGLICT/RisaNET.
Deep Line Art Video Colorization with a Few References
Mar 30, 2020
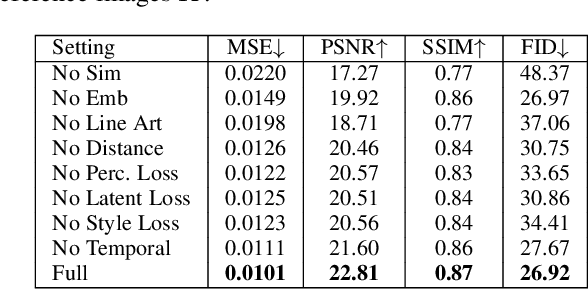
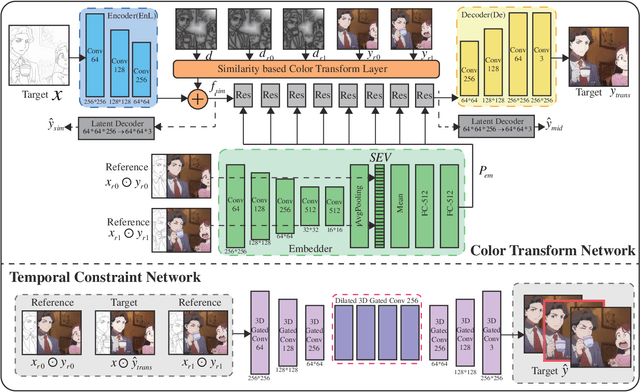
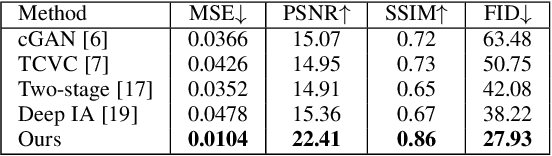
Coloring line art images based on the colors of reference images is an important stage in animation production, which is time-consuming and tedious. In this paper, we propose a deep architecture to automatically color line art videos with the same color style as the given reference images. Our framework consists of a color transform network and a temporal constraint network. The color transform network takes the target line art images as well as the line art and color images of one or more reference images as input, and generates corresponding target color images. To cope with larger differences between the target line art image and reference color images, our architecture utilizes non-local similarity matching to determine the region correspondences between the target image and the reference images, which are used to transform the local color information from the references to the target. To ensure global color style consistency, we further incorporate Adaptive Instance Normalization (AdaIN) with the transformation parameters obtained from a style embedding vector that describes the global color style of the references, extracted by an embedder. The temporal constraint network takes the reference images and the target image together in chronological order, and learns the spatiotemporal features through 3D convolution to ensure the temporal consistency of the target image and the reference image. Our model can achieve even better coloring results by fine-tuning the parameters with only a small amount of samples when dealing with an animation of a new style. To evaluate our method, we build a line art coloring dataset. Experiments show that our method achieves the best performance on line art video coloring compared to the state-of-the-art methods and other baselines.