 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRachel Bawden
Making Sentence Embeddings Robust to User-Generated Content
Mar 25, 2024




NLP models have been known to perform poorly on user-generated content (UGC), mainly because it presents a lot of lexical variations and deviates from the standard texts on which most of these models were trained. In this work, we focus on the robustness of LASER, a sentence embedding model, to UGC data. We evaluate this robustness by LASER's ability to represent non-standard sentences and their standard counterparts close to each other in the embedding space. Inspired by previous works extending LASER to other languages and modalities, we propose RoLASER, a robust English encoder trained using a teacher-student approach to reduce the distances between the representations of standard and UGC sentences. We show that with training only on standard and synthetic UGC-like data, RoLASER significantly improves LASER's robustness to both natural and artificial UGC data by achieving up to 2x and 11x better scores. We also perform a fine-grained analysis on artificial UGC data and find that our model greatly outperforms LASER on its most challenging UGC phenomena such as keyboard typos and social media abbreviations. Evaluation on downstream tasks shows that RoLASER performs comparably to or better than LASER on standard data, while consistently outperforming it on UGC data.
A Simple Method for Unsupervised Bilingual Lexicon Induction for Data-Imbalanced, Closely Related Language Pairs
May 23, 2023
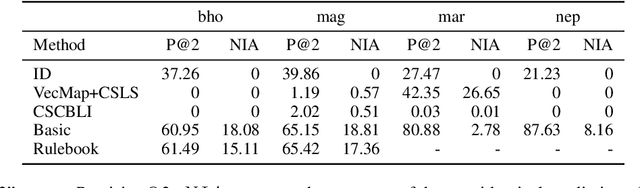
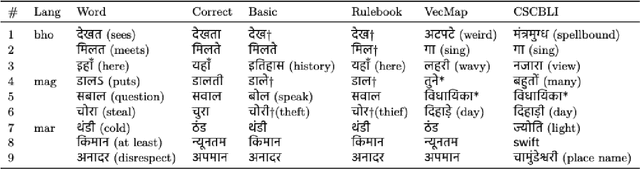

Existing approaches for unsupervised bilingual lexicon induction (BLI) often depend on good quality static or contextual embeddings trained on large monolingual corpora for both languages. In reality, however, unsupervised BLI is most likely to be useful for dialects and languages that do not have abundant amounts of monolingual data. We introduce a simple and fast method for unsupervised BLI for low-resource languages with a related mid-to-high resource language, only requiring inference on the higher-resource language monolingual BERT. We work with two low-resource languages ($<5M$ monolingual tokens), Bhojpuri and Magahi, of the severely under-researched Indic dialect continuum, showing that state-of-the-art methods in the literature show near-zero performance in these settings, and that our simpler method gives much better results. We repeat our experiments on Marathi and Nepali, two higher-resource Indic languages, to compare approach performances by resource range. We release automatically created bilingual lexicons for the first time for five languages of the Indic dialect continuum.
Investigating Lexical Sharing in Multilingual Machine Translation for Indian Languages
May 04, 2023



Multilingual language models have shown impressive cross-lingual transfer ability across a diverse set of languages and tasks. To improve the cross-lingual ability of these models, some strategies include transliteration and finer-grained segmentation into characters as opposed to subwords. In this work, we investigate lexical sharing in multilingual machine translation (MT) from Hindi, Gujarati, Nepali into English. We explore the trade-offs that exist in translation performance between data sampling and vocabulary size, and we explore whether transliteration is useful in encouraging cross-script generalisation. We also verify how the different settings generalise to unseen languages (Marathi and Bengali). We find that transliteration does not give pronounced improvements and our analysis suggests that our multilingual MT models trained on original scripts seem to already be robust to cross-script differences even for relatively low-resource languages
Investigating the Translation Performance of a Large Multilingual Language Model: the Case of BLOOM
Mar 03, 2023



The NLP community recently saw the release of a new large open-access multilingual language model, BLOOM (BigScience et al., 2022) covering 46 languages. We focus on BLOOM's multilingual ability by evaluating its machine translation performance across several datasets (WMT, Flores-101 and DiaBLa) and language pairs (high- and low-resourced). Our results show that 0-shot performance suffers from overgeneration and generating in the wrong language, but this is greatly improved in the few-shot setting, with very good results for a number of language pairs. We study several aspects including prompt design, model sizes, cross-lingual transfer and the use of discursive context.
Tackling Ambiguity with Images: Improved Multimodal Machine Translation and Contrastive Evaluation
Dec 20, 2022

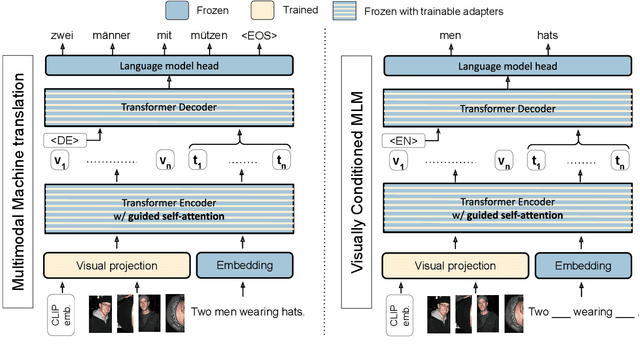

One of the major challenges of machine translation (MT) is ambiguity, which can in some cases be resolved by accompanying context such as an image. However, recent work in multimodal MT (MMT) has shown that obtaining improvements from images is challenging, limited not only by the difficulty of building effective cross-modal representations but also by the lack of specific evaluation and training data. We present a new MMT approach based on a strong text-only MT model, which uses neural adapters and a novel guided self-attention mechanism and which is jointly trained on both visual masking and MMT. We also release CoMMuTE, a Contrastive Multilingual Multimodal Translation Evaluation dataset, composed of ambiguous sentences and their possible translations, accompanied by disambiguating images corresponding to each translation. Our approach obtains competitive results over strong text-only models on standard English-to-French benchmarks and outperforms these baselines and state-of-the-art MMT systems with a large margin on our contrastive test set.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
MaskEval: Weighted MLM-Based Evaluation for Text Summarization and Simplification
May 24, 2022



In text summarization and simplification, system outputs must be evaluated along multiple dimensions such as relevance, factual consistency, fluency, and grammaticality, and a wide range of possible outputs could be of high quality. These properties make the development of an adaptable, reference-less evaluation metric both necessary and challenging. We introduce MaskEval, a reference-less metric for text summarization and simplification that operates by performing masked language modeling (MLM) on the concatenation of the candidate and the source texts. It features an attention-like weighting mechanism to modulate the relative importance of each MLM step, which crucially allows MaskEval to be adapted to evaluate different quality dimensions. We demonstrate its effectiveness on English summarization and on multilingual text simplification in terms of correlations with human judgments.
From FreEM to D'AlemBERT: a Large Corpus and a Language Model for Early Modern French
Feb 18, 2022



Language models for historical states of language are becoming increasingly important to allow the optimal digitisation and analysis of old textual sources. Because these historical states are at the same time more complex to process and more scarce in the corpora available, specific efforts are necessary to train natural language processing (NLP) tools adapted to the data. In this paper, we present our efforts to develop NLP tools for Early Modern French (historical French from the 16$^\text{th}$ to the 18$^\text{th}$ centuries). We present the $\text{FreEM}_{\text{max}}$ corpus of Early Modern French and D'AlemBERT, a RoBERTa-based language model trained on $\text{FreEM}_{\text{max}}$. We evaluate the usefulness of D'AlemBERT by fine-tuning it on a part-of-speech tagging task, outperforming previous work on the test set. Importantly, we find evidence for the transfer learning capacity of the language model, since its performance on lesser-resourced time periods appears to have been boosted by the more resourced ones. We release D'AlemBERT and the open-sourced subpart of the $\text{FreEM}_{\text{max}}$ corpus.
Multitask Prompted Training Enables Zero-Shot Task Generalization
Oct 15, 2021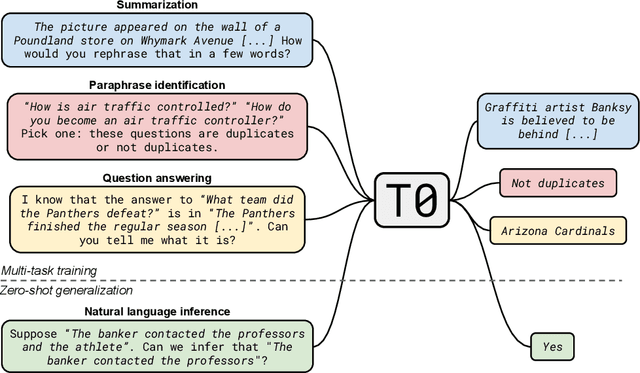

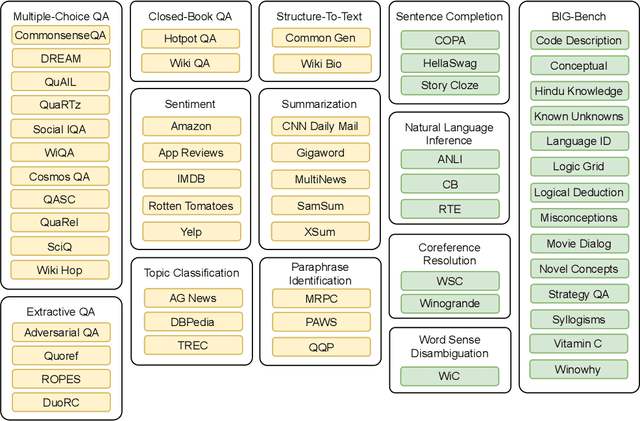

Large language models have recently been shown to attain reasonable zero-shot generalization on a diverse set of tasks. It has been hypothesized that this is a consequence of implicit multitask learning in language model training. Can zero-shot generalization instead be directly induced by explicit multitask learning? To test this question at scale, we develop a system for easily mapping general natural language tasks into a human-readable prompted form. We convert a large set of supervised datasets, each with multiple prompts using varying natural language. These prompted datasets allow for benchmarking the ability of a model to perform completely unseen tasks specified in natural language. We fine-tune a pretrained encoder-decoder model on this multitask mixture covering a wide variety of tasks. The model attains strong zero-shot performance on several standard datasets, often outperforming models 16x its size. Further, our approach attains strong performance on a subset of tasks from the BIG-Bench benchmark, outperforming models 6x its size. All prompts and trained models are available at github.com/bigscience-workshop/promptsource/.
Survey of Low-Resource Machine Translation
Sep 01, 2021



We present a survey covering the state of the art in low-resource machine translation. There are currently around 7000 languages spoken in the world and almost all language pairs lack significant resources for training machine translation models. There has been increasing interest in research addressing the challenge of producing useful translation models when very little translated training data is available. We present a high level summary of this topical field and provide an overview of best practices.