 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouwe Kiela
Generative Representational Instruction Tuning
Feb 15, 2024
All text-based language problems can be reduced to either generation or embedding. Current models only perform well at one or the other. We introduce generative representational instruction tuning (GRIT) whereby a large language model is trained to handle both generative and embedding tasks by distinguishing between them through instructions. Compared to other open models, our resulting GritLM 7B sets a new state of the art on the Massive Text Embedding Benchmark (MTEB) and outperforms all models up to its size on a range of generative tasks. By scaling up further, GritLM 8x7B outperforms all open generative language models that we tried while still being among the best embedding models. Notably, we find that GRIT matches training on only generative or embedding data, thus we can unify both at no performance loss. Among other benefits, the unification via GRIT speeds up Retrieval-Augmented Generation (RAG) by > 60% for long documents, by no longer requiring separate retrieval and generation models. Models, code, etc. are freely available at https://github.com/ContextualAI/gritlm.
KTO: Model Alignment as Prospect Theoretic Optimization
Feb 02, 2024Kahneman & Tversky's $\textit{prospect theory}$ tells us that humans perceive random variables in a biased but well-defined manner; for example, humans are famously loss-averse. We show that objectives for aligning LLMs with human feedback implicitly incorporate many of these biases -- the success of these objectives (e.g., DPO) over cross-entropy minimization can partly be ascribed to them being $\textit{human-aware loss functions}$ (HALOs). However, the utility functions these methods attribute to humans still differ from those in the prospect theory literature. Using a Kahneman-Tversky model of human utility, we propose a HALO that directly maximizes the utility of generations instead of maximizing the log-likelihood of preferences, as current methods do. We call this approach Kahneman-Tversky Optimization (KTO), and it matches or exceeds the performance of preference-based methods at scales from 1B to 30B. Crucially, KTO does not need preferences -- only a binary signal of whether an output is desirable or undesirable for a given input. This makes it far easier to use in the real world, where preference data is scarce and expensive.
I am a Strange Dataset: Metalinguistic Tests for Language Models
Jan 10, 2024Statements involving metalinguistic self-reference ("This paper has six sections.") are prevalent in many domains. Can large language models (LLMs) handle such language? In this paper, we present "I am a Strange Dataset", a new dataset for addressing this question. There are two subtasks: generation and verification. In generation, models continue statements like "The penultimate word in this sentence is" (where a correct continuation is "is"). In verification, models judge the truth of statements like "The penultimate word in this sentence is sentence." (false). We also provide minimally different metalinguistic non-self-reference examples to complement the main dataset by probing for whether models can handle metalinguistic language at all. The dataset is hand-crafted by experts and validated by non-expert annotators. We test a variety of open-source LLMs (7B to 70B parameters) as well as closed-source LLMs through APIs. All models perform close to chance across both subtasks and even on the non-self-referential metalinguistic control data, though we find some steady improvement with model scale. GPT 4 is the only model to consistently do significantly better than chance, and it is still only in the 60% range, while our untrained human annotators score well in the 89-93% range. The dataset and evaluation toolkit are available at https://github.com/TristanThrush/i-am-a-strange-dataset.
Leveraging Diffusion Perturbations for Measuring Fairness in Computer Vision
Nov 25, 2023Computer vision models have been known to encode harmful biases, leading to the potentially unfair treatment of historically marginalized groups, such as people of color. However, there remains a lack of datasets balanced along demographic traits that can be used to evaluate the downstream fairness of these models. In this work, we demonstrate that diffusion models can be leveraged to create such a dataset. We first use a diffusion model to generate a large set of images depicting various occupations. Subsequently, each image is edited using inpainting to generate multiple variants, where each variant refers to a different perceived race. Using this dataset, we benchmark several vision-language models on a multi-class occupation classification task. We find that images generated with non-Caucasian labels have a significantly higher occupation misclassification rate than images generated with Caucasian labels, and that several misclassifications are suggestive of racial biases. We measure a model's downstream fairness by computing the standard deviation in the probability of predicting the true occupation label across the different perceived identity groups. Using this fairness metric, we find significant disparities between the evaluated vision-and-language models. We hope that our work demonstrates the potential value of diffusion methods for fairness evaluations.
FinanceBench: A New Benchmark for Financial Question Answering
Nov 20, 2023FinanceBench is a first-of-its-kind test suite for evaluating the performance of LLMs on open book financial question answering (QA). It comprises 10,231 questions about publicly traded companies, with corresponding answers and evidence strings. The questions in FinanceBench are ecologically valid and cover a diverse set of scenarios. They are intended to be clear-cut and straightforward to answer to serve as a minimum performance standard. We test 16 state of the art model configurations (including GPT-4-Turbo, Llama2 and Claude2, with vector stores and long context prompts) on a sample of 150 cases from FinanceBench, and manually review their answers (n=2,400). The cases are available open-source. We show that existing LLMs have clear limitations for financial QA. Notably, GPT-4-Turbo used with a retrieval system incorrectly answered or refused to answer 81% of questions. While augmentation techniques such as using longer context window to feed in relevant evidence improve performance, they are unrealistic for enterprise settings due to increased latency and cannot support larger financial documents. We find that all models examined exhibit weaknesses, such as hallucinations, that limit their suitability for use by enterprises.
Anchor Points: Benchmarking Models with Much Fewer Examples
Sep 14, 2023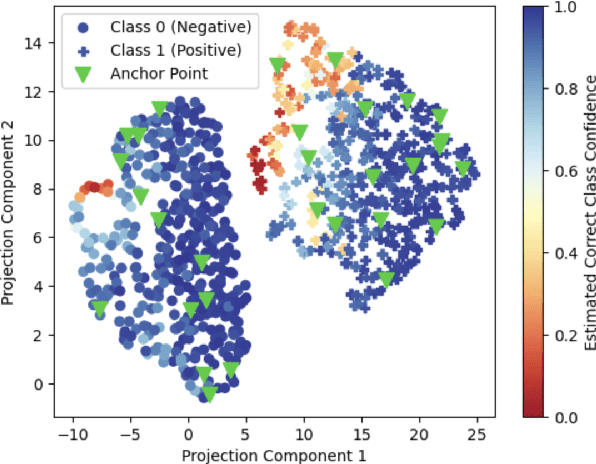
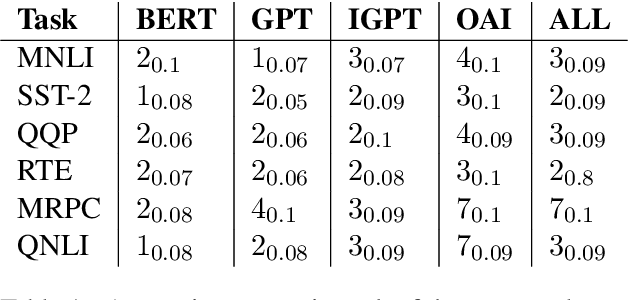
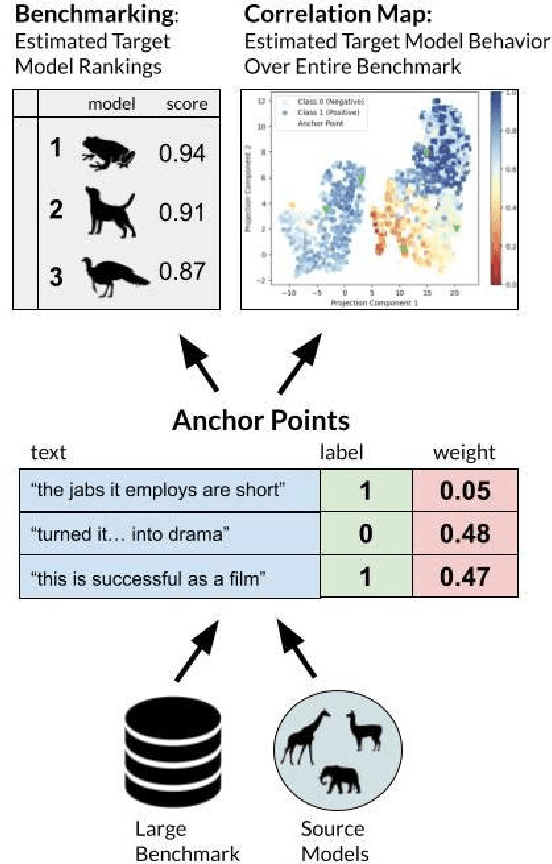
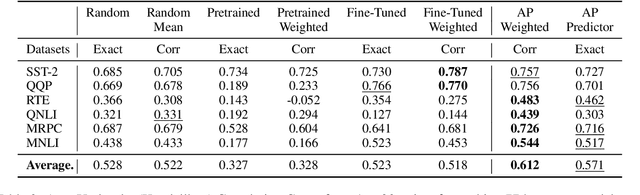
Modern language models often exhibit powerful but brittle behavior, leading to the development of larger and more diverse benchmarks to reliably assess their behavior. Here, we suggest that model performance can be benchmarked and elucidated with much smaller evaluation sets. We first show that in six popular language classification benchmarks, model confidence in the correct class on many pairs of points is strongly correlated across models. We build upon this phenomenon to propose Anchor Point Selection, a technique to select small subsets of datasets that capture model behavior across the entire dataset. Anchor points reliably rank models: across 87 diverse language model-prompt pairs, evaluating models using 1-30 anchor points outperforms uniform sampling and other baselines at accurately ranking models. Moreover, just several anchor points can be used to estimate model per-class predictions on all other points in a dataset with low mean absolute error, sufficient for gauging where the model is likely to fail. Lastly, we present Anchor Point Maps for visualizing these insights and facilitating comparisons of the performance of different models on various regions within the dataset distribution.
Towards Language Models That Can See: Computer Vision Through the LENS of Natural Language
Jun 28, 2023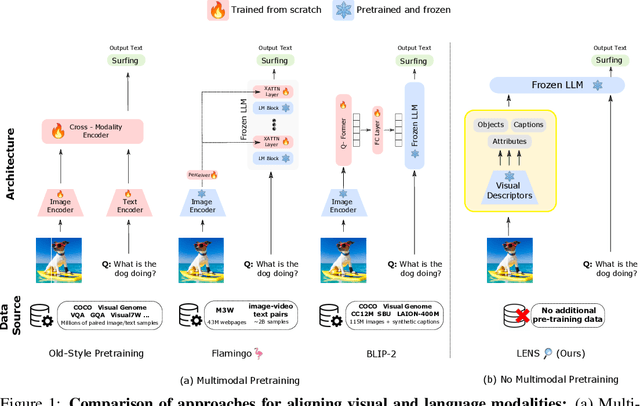
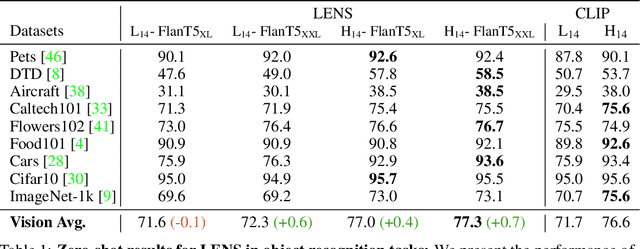
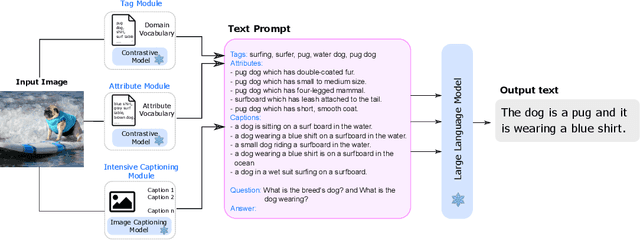
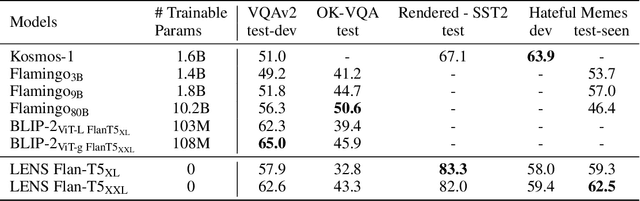
We propose LENS, a modular approach for tackling computer vision problems by leveraging the power of large language models (LLMs). Our system uses a language model to reason over outputs from a set of independent and highly descriptive vision modules that provide exhaustive information about an image. We evaluate the approach on pure computer vision settings such as zero- and few-shot object recognition, as well as on vision and language problems. LENS can be applied to any off-the-shelf LLM and we find that the LLMs with LENS perform highly competitively with much bigger and much more sophisticated systems, without any multimodal training whatsoever. We open-source our code at https://github.com/ContextualAI/lens and provide an interactive demo.
OBELISC: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents
Jun 21, 2023
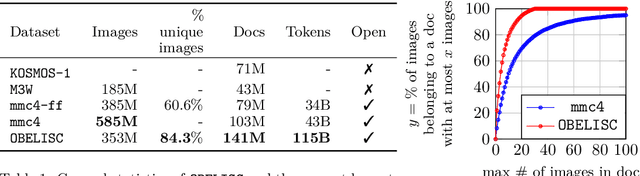
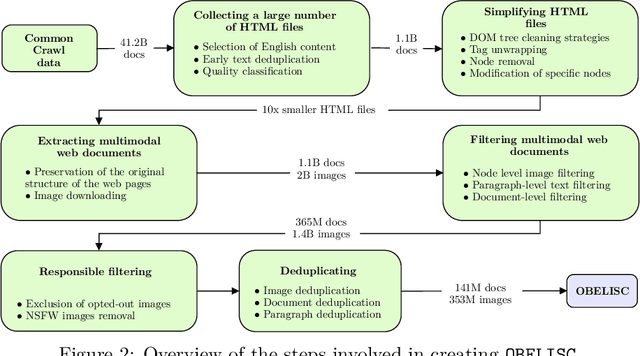
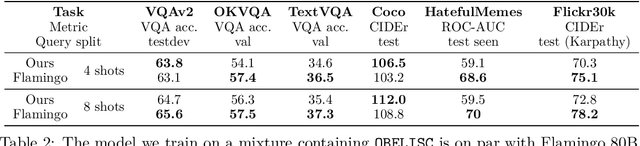
Large multimodal models trained on natural documents, which interleave images and text, outperform models trained on image-text pairs on various multimodal benchmarks that require reasoning over one or multiple images to generate a text. However, the datasets used to train these models have not been released, and the collection process has not been fully specified. We introduce the OBELISC dataset, an open web-scale filtered dataset of interleaved image-text documents comprising 141 million web pages extracted from Common Crawl, 353 million associated images, and 115 billion text tokens. We describe the dataset creation process, present comprehensive filtering rules, and provide an analysis of the dataset's content. To show the viability of OBELISC, we train an 80 billion parameters vision and language model on the dataset and obtain competitive performance on various multimodal benchmarks. We release the code to reproduce the dataset along with the dataset itself.
AfroDigits: A Community-Driven Spoken Digit Dataset for African Languages
Apr 04, 2023
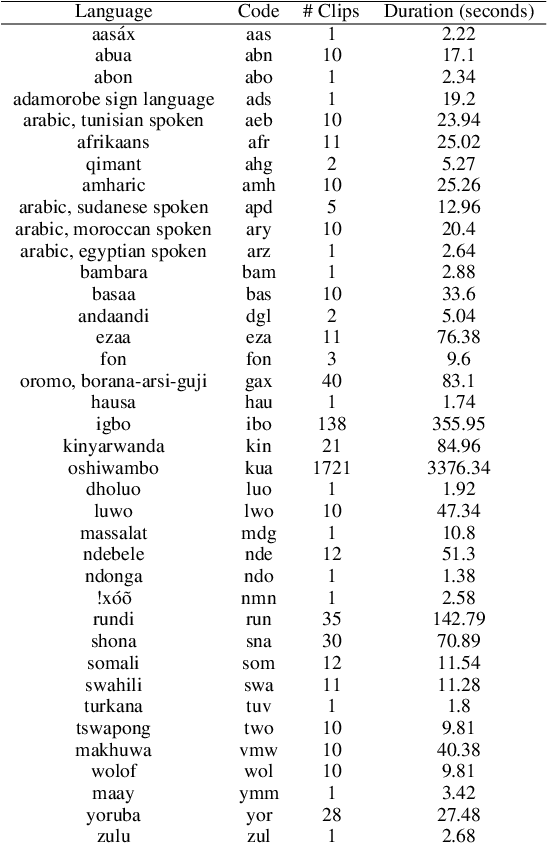
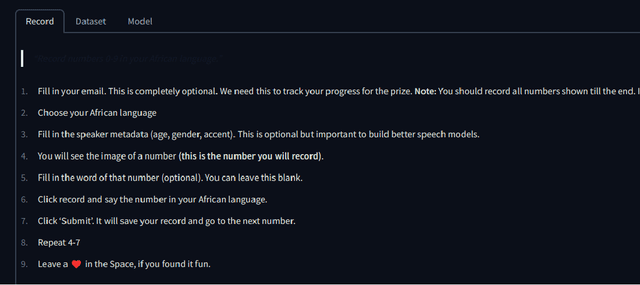
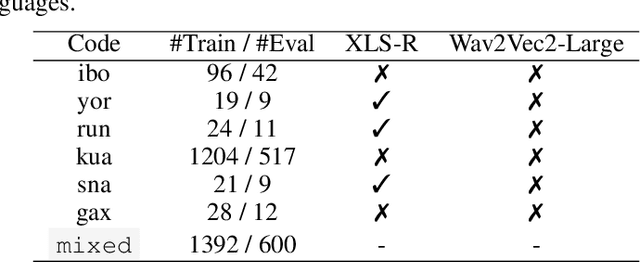
The advancement of speech technologies has been remarkable, yet its integration with African languages remains limited due to the scarcity of African speech corpora. To address this issue, we present AfroDigits, a minimalist, community-driven dataset of spoken digits for African languages, currently covering 38 African languages. As a demonstration of the practical applications of AfroDigits, we conduct audio digit classification experiments on six African languages [Igbo (ibo), Yoruba (yor), Rundi (run), Oshiwambo (kua), Shona (sna), and Oromo (gax)] using the Wav2Vec2.0-Large and XLS-R models. Our experiments reveal a useful insight on the effect of mixing African speech corpora during finetuning. AfroDigits is the first published audio digit dataset for African languages and we believe it will, among other things, pave the way for Afro-centric speech applications such as the recognition of telephone numbers, and street numbers. We release the dataset and platform publicly at https://huggingface.co/datasets/chrisjay/crowd-speech-africa and https://huggingface.co/spaces/chrisjay/afro-speech respectively.
Investigating Multi-source Active Learning for Natural Language Inference
Feb 14, 2023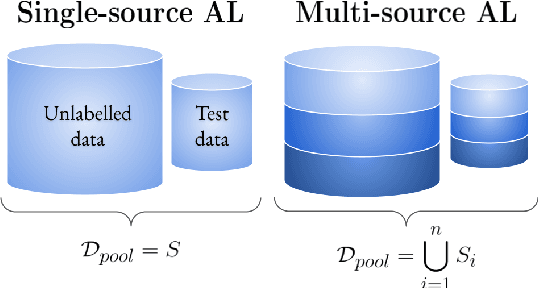
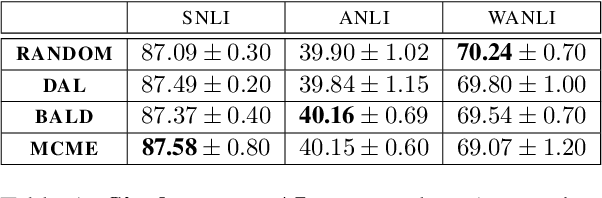
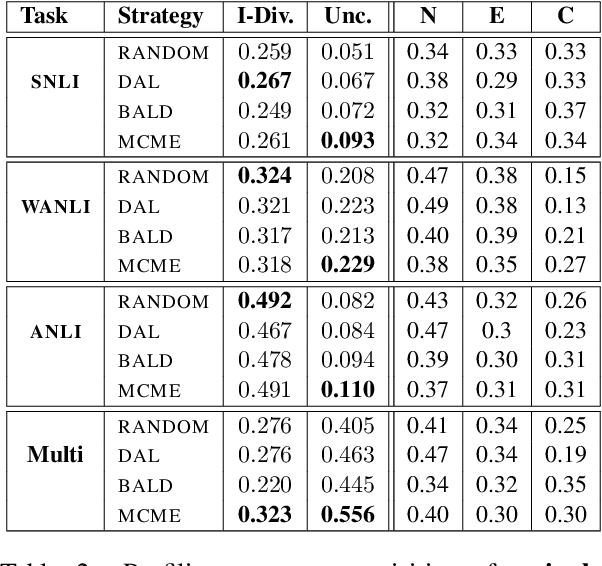
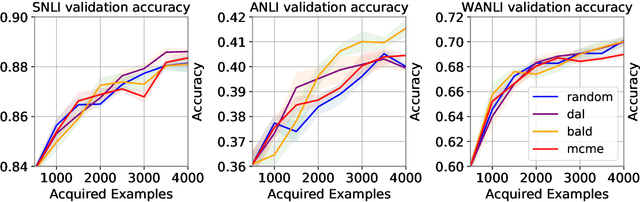
In recent years, active learning has been successfully applied to an array of NLP tasks. However, prior work often assumes that training and test data are drawn from the same distribution. This is problematic, as in real-life settings data may stem from several sources of varying relevance and quality. We show that four popular active learning schemes fail to outperform random selection when applied to unlabelled pools comprised of multiple data sources on the task of natural language inference. We reveal that uncertainty-based strategies perform poorly due to the acquisition of collective outliers, i.e., hard-to-learn instances that hamper learning and generalization. When outliers are removed, strategies are found to recover and outperform random baselines. In further analysis, we find that collective outliers vary in form between sources, and show that hard-to-learn data is not always categorically harmful. Lastly, we leverage dataset cartography to introduce difficulty-stratified testing and find that different strategies are affected differently by example learnability and difficulty.