 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbhinav Ramesh Kashyap
Automated Clinical Coding for Outpatient Departments
Dec 24, 2023
Computerised clinical coding approaches aim to automate the process of assigning a set of codes to medical records. While there is active research pushing the state of the art on clinical coding for hospitalized patients, the outpatient setting -- where doctors tend to non-hospitalised patients -- is overlooked. Although both settings can be formalised as a multi-label classification task, they present unique and distinct challenges, which raises the question of whether the success of inpatient clinical coding approaches translates to the outpatient setting. This paper is the first to investigate how well state-of-the-art deep learning-based clinical coding approaches work in the outpatient setting at hospital scale. To this end, we collect a large outpatient dataset comprising over 7 million notes documenting over half a million patients. We adapt four state-of-the-art clinical coding approaches to this setting and evaluate their potential to assist coders. We find evidence that clinical coding in outpatient settings can benefit from more innovations in popular inpatient coding benchmarks. A deeper analysis of the factors contributing to the success -- amount and form of data and choice of document representation -- reveals the presence of easy-to-solve examples, the coding of which can be completely automated with a low error rate.
PULSAR at MEDIQA-Sum 2023: Large Language Models Augmented by Synthetic Dialogue Convert Patient Dialogues to Medical Records
Jul 05, 2023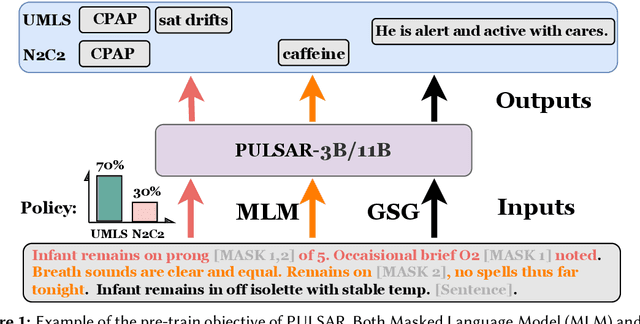
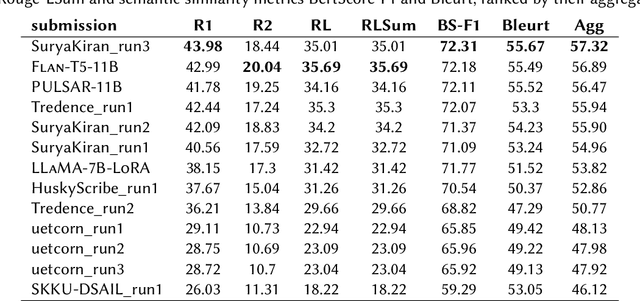
This paper describes PULSAR, our system submission at the ImageClef 2023 MediQA-Sum task on summarising patient-doctor dialogues into clinical records. The proposed framework relies on domain-specific pre-training, to produce a specialised language model which is trained on task-specific natural data augmented by synthetic data generated by a black-box LLM. We find limited evidence towards the efficacy of domain-specific pre-training and data augmentation, while scaling up the language model yields the best performance gains. Our approach was ranked second and third among 13 submissions on task B of the challenge. Our code is available at https://github.com/yuping-wu/PULSAR.
PULSAR: Pre-training with Extracted Healthcare Terms for Summarising Patients' Problems and Data Augmentation with Black-box Large Language Models
Jun 05, 2023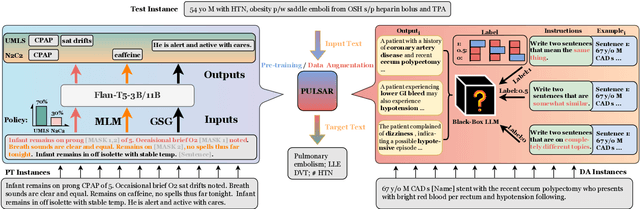


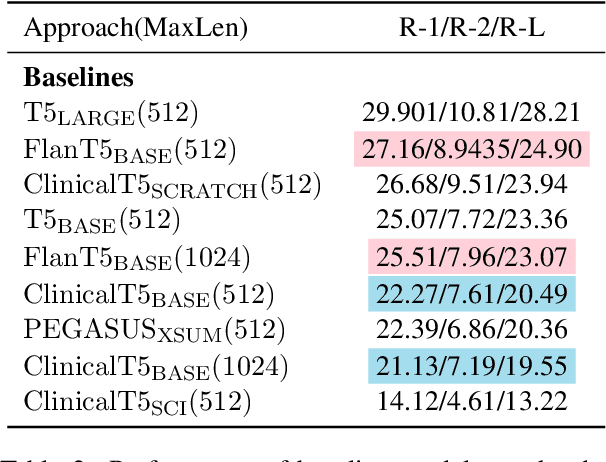
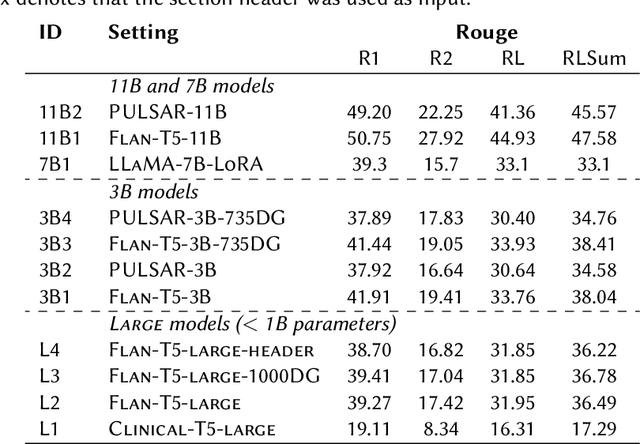
Medical progress notes play a crucial role in documenting a patient's hospital journey, including his or her condition, treatment plan, and any updates for healthcare providers. Automatic summarisation of a patient's problems in the form of a problem list can aid stakeholders in understanding a patient's condition, reducing workload and cognitive bias. BioNLP 2023 Shared Task 1A focuses on generating a list of diagnoses and problems from the provider's progress notes during hospitalisation. In this paper, we introduce our proposed approach to this task, which integrates two complementary components. One component employs large language models (LLMs) for data augmentation; the other is an abstractive summarisation LLM with a novel pre-training objective for generating the patients' problems summarised as a list. Our approach was ranked second among all submissions to the shared task. The performance of our model on the development and test datasets shows that our approach is more robust on unknown data, with an improvement of up to 3.1 points over the same size of the larger model.
ADAPTERMIX: Exploring the Efficacy of Mixture of Adapters for Low-Resource TTS Adaptation
May 29, 2023


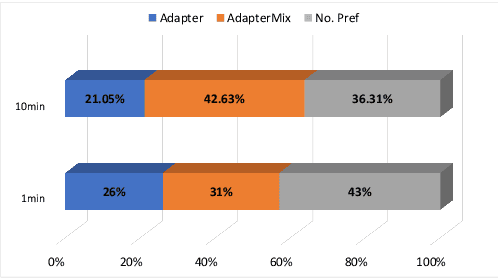
There are significant challenges for speaker adaptation in text-to-speech for languages that are not widely spoken or for speakers with accents or dialects that are not well-represented in the training data. To address this issue, we propose the use of the "mixture of adapters" method. This approach involves adding multiple adapters within a backbone-model layer to learn the unique characteristics of different speakers. Our approach outperforms the baseline, with a noticeable improvement of 5% observed in speaker preference tests when using only one minute of data for each new speaker. Moreover, following the adapter paradigm, we fine-tune only the adapter parameters (11% of the total model parameters). This is a significant achievement in parameter-efficient speaker adaptation, and one of the first models of its kind. Overall, our proposed approach offers a promising solution to the speech synthesis techniques, particularly for adapting to speakers from diverse backgrounds.
Beyond Words: A Comprehensive Survey of Sentence Representations
May 23, 2023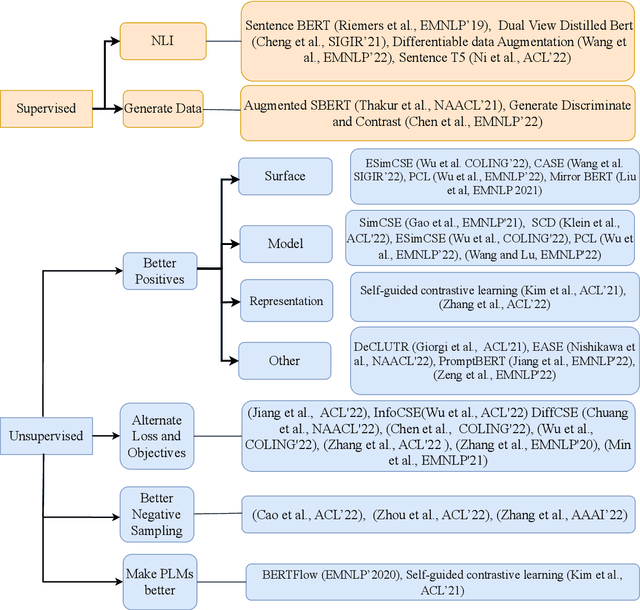
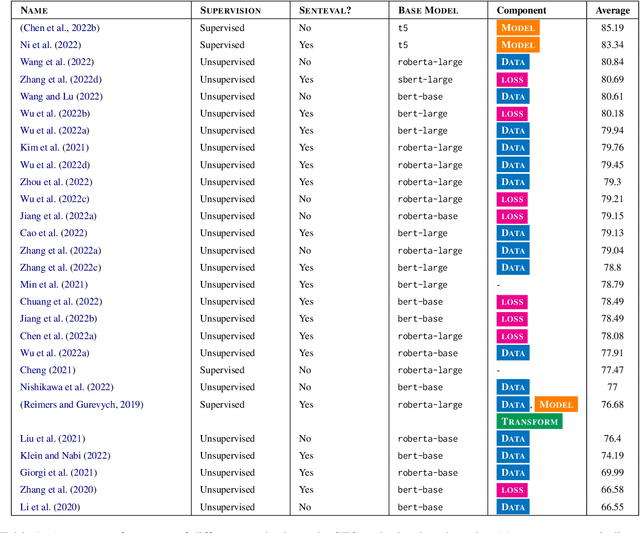
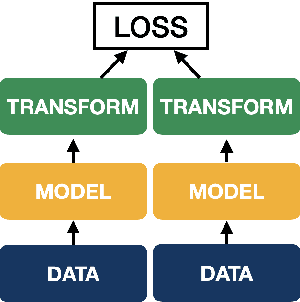
Sentence representations have become a critical component in natural language processing applications, such as retrieval, question answering, and text classification. They capture the semantics and meaning of a sentence, enabling machines to understand and reason over human language. In recent years, significant progress has been made in developing methods for learning sentence representations, including unsupervised, supervised, and transfer learning approaches. In this paper, we provide an overview of the different methods for sentence representation learning, including both traditional and deep learning-based techniques. We provide a systematic organization of the literature on sentence representation learning, highlighting the key contributions and challenges in this area. Overall, our review highlights the progress made in sentence representation learning, the importance of this area in natural language processing, and the challenges that remain. We conclude with directions for future research, suggesting potential avenues for improving the quality and efficiency of sentence representations in NLP applications.
UDApter -- Efficient Domain Adaptation Using Adapters
Feb 16, 2023



We propose two methods to make unsupervised domain adaptation (UDA) more parameter efficient using adapters, small bottleneck layers interspersed with every layer of the large-scale pre-trained language model (PLM). The first method deconstructs UDA into a two-step process: first by adding a domain adapter to learn domain-invariant information and then by adding a task adapter that uses domain-invariant information to learn task representations in the source domain. The second method jointly learns a supervised classifier while reducing the divergence measure. Compared to strong baselines, our simple methods perform well in natural language inference (MNLI) and the cross-domain sentiment classification task. We even outperform unsupervised domain adaptation methods such as DANN and DSN in sentiment classification, and we are within 0.85% F1 for natural language inference task, by fine-tuning only a fraction of the full model parameters. We release our code at https://github.com/declare-lab/domadapter
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
So Different Yet So Alike! Constrained Unsupervised Text Style Transfer
May 09, 2022



Automatic transfer of text between domains has become popular in recent times. One of its aims is to preserve the semantic content of text being translated from source to target domain. However, it does not explicitly maintain other attributes between the source and translated text, for e.g., text length and descriptiveness. Maintaining constraints in transfer has several downstream applications, including data augmentation and de-biasing. We introduce a method for such constrained unsupervised text style transfer by introducing two complementary losses to the generative adversarial network (GAN) family of models. Unlike the competing losses used in GANs, we introduce cooperative losses where the discriminator and the generator cooperate and reduce the same loss. The first is a contrastive loss and the second is a classification loss, aiming to regularize the latent space further and bring similar sentences across domains closer together. We demonstrate that such training retains lexical, syntactic, and domain-specific constraints between domains for multiple benchmark datasets, including ones where more than one attribute change. We show that the complementary cooperative losses improve text quality, according to both automated and human evaluation measures.
Domain Divergences: a Survey and Empirical Analysis
Oct 23, 2020



Domain divergence plays a significant role in estimating the performance of a model when applied to new domains. While there is significant literature on divergence measures, choosing an appropriate divergence measures remains difficult for researchers. We address this shortcoming by both surveying the literature and through an empirical study. We contribute a taxonomy of divergence measures consisting of three groups -- Information-theoretic, Geometric, and Higher-order measures -- and identify the relationships between them. We then ground the use of divergence measures in three different application groups -- 1) Data Selection, 2) Learning Representation, and 3) Decisions in the Wild. From this, we identify that Information-theoretic measures are prevalent for 1) and 3), and higher-order measures are common for 2). To further help researchers, we validate these uses empirically through a correlation analysis of performance drops. We consider the current contextual word representations (CWR) to contrast with the older word distribution based representations for this analysis. We find that traditional measures over word distributions still serve as strong baselines, while higher-order measures with CWR are effective.
SciWING -- A Software Toolkit for Scientific Document Processing
Apr 08, 2020


We introduce SciWING, an open-source software toolkit which provides access to pre-trained models for scientific document processing tasks, inclusive of citation string parsing and logical structure recovery. SciWING enables researchers to rapidly experiment with different models by swapping and stacking different modules. It also enables them declare and run models from a configuration file. It enables researchers to perform production-ready transfer learning from general, pre-trained transformers (i.e., BERT, SciBERT etc), and aids development of end-user applications. It includes ready-to-use web and terminal-based applications and demonstrations (Available from http://sciwing.io).