 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmbuj Mehrish
HyperTTS: Parameter Efficient Adaptation in Text to Speech using Hypernetworks
Apr 06, 2024
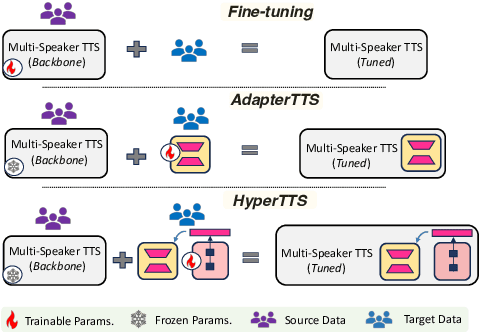

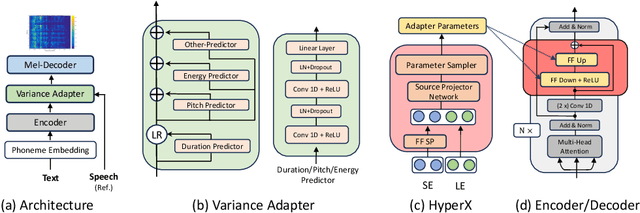
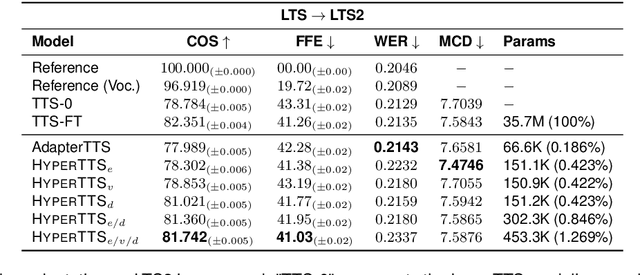
Neural speech synthesis, or text-to-speech (TTS), aims to transform a signal from the text domain to the speech domain. While developing TTS architectures that train and test on the same set of speakers has seen significant improvements, out-of-domain speaker performance still faces enormous limitations. Domain adaptation on a new set of speakers can be achieved by fine-tuning the whole model for each new domain, thus making it parameter-inefficient. This problem can be solved by Adapters that provide a parameter-efficient alternative to domain adaptation. Although famous in NLP, speech synthesis has not seen much improvement from Adapters. In this work, we present HyperTTS, which comprises a small learnable network, "hypernetwork", that generates parameters of the Adapter blocks, allowing us to condition Adapters on speaker representations and making them dynamic. Extensive evaluations of two domain adaptation settings demonstrate its effectiveness in achieving state-of-the-art performance in the parameter-efficient regime. We also compare different variants of HyperTTS, comparing them with baselines in different studies. Promising results on the dynamic adaptation of adapter parameters using hypernetworks open up new avenues for domain-generic multi-speaker TTS systems. The audio samples and code are available at https://github.com/declare-lab/HyperTTS.
CM-TTS: Enhancing Real Time Text-to-Speech Synthesis Efficiency through Weighted Samplers and Consistency Models
Mar 31, 2024Neural Text-to-Speech (TTS) systems find broad applications in voice assistants, e-learning, and audiobook creation. The pursuit of modern models, like Diffusion Models (DMs), holds promise for achieving high-fidelity, real-time speech synthesis. Yet, the efficiency of multi-step sampling in Diffusion Models presents challenges. Efforts have been made to integrate GANs with DMs, speeding up inference by approximating denoising distributions, but this introduces issues with model convergence due to adversarial training. To overcome this, we introduce CM-TTS, a novel architecture grounded in consistency models (CMs). Drawing inspiration from continuous-time diffusion models, CM-TTS achieves top-quality speech synthesis in fewer steps without adversarial training or pre-trained model dependencies. We further design weighted samplers to incorporate different sampling positions into model training with dynamic probabilities, ensuring unbiased learning throughout the entire training process. We present a real-time mel-spectrogram generation consistency model, validated through comprehensive evaluations. Experimental results underscore CM-TTS's superiority over existing single-step speech synthesis systems, representing a significant advancement in the field.
ADAPTERMIX: Exploring the Efficacy of Mixture of Adapters for Low-Resource TTS Adaptation
May 29, 2023


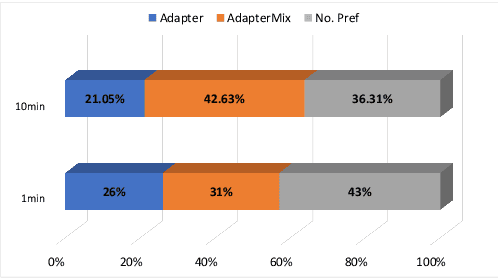
There are significant challenges for speaker adaptation in text-to-speech for languages that are not widely spoken or for speakers with accents or dialects that are not well-represented in the training data. To address this issue, we propose the use of the "mixture of adapters" method. This approach involves adding multiple adapters within a backbone-model layer to learn the unique characteristics of different speakers. Our approach outperforms the baseline, with a noticeable improvement of 5% observed in speaker preference tests when using only one minute of data for each new speaker. Moreover, following the adapter paradigm, we fine-tune only the adapter parameters (11% of the total model parameters). This is a significant achievement in parameter-efficient speaker adaptation, and one of the first models of its kind. Overall, our proposed approach offers a promising solution to the speech synthesis techniques, particularly for adapting to speakers from diverse backgrounds.
A Review of Deep Learning Techniques for Speech Processing
May 02, 2023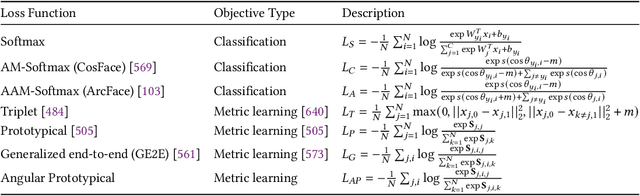
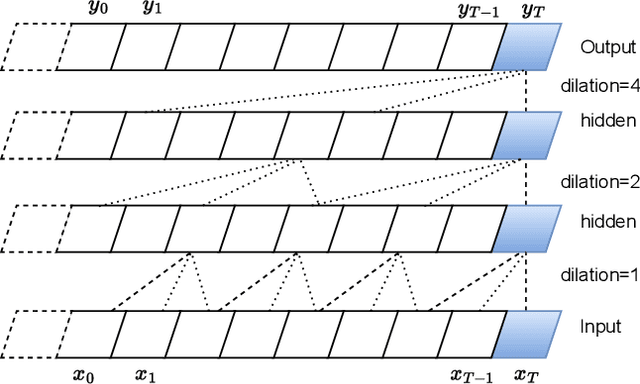
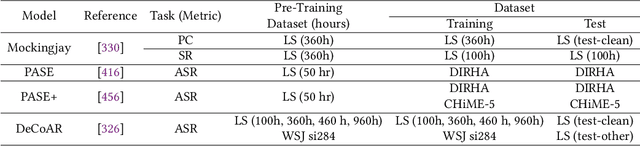
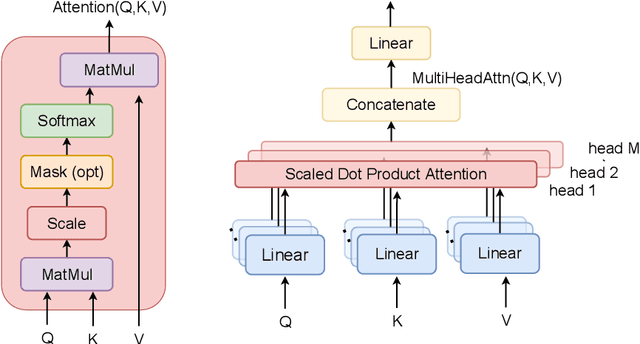
The field of speech processing has undergone a transformative shift with the advent of deep learning. The use of multiple processing layers has enabled the creation of models capable of extracting intricate features from speech data. This development has paved the way for unparalleled advancements in speech recognition, text-to-speech synthesis, automatic speech recognition, and emotion recognition, propelling the performance of these tasks to unprecedented heights. The power of deep learning techniques has opened up new avenues for research and innovation in the field of speech processing, with far-reaching implications for a range of industries and applications. This review paper provides a comprehensive overview of the key deep learning models and their applications in speech-processing tasks. We begin by tracing the evolution of speech processing research, from early approaches, such as MFCC and HMM, to more recent advances in deep learning architectures, such as CNNs, RNNs, transformers, conformers, and diffusion models. We categorize the approaches and compare their strengths and weaknesses for solving speech-processing tasks. Furthermore, we extensively cover various speech-processing tasks, datasets, and benchmarks used in the literature and describe how different deep-learning networks have been utilized to tackle these tasks. Additionally, we discuss the challenges and future directions of deep learning in speech processing, including the need for more parameter-efficient, interpretable models and the potential of deep learning for multimodal speech processing. By examining the field's evolution, comparing and contrasting different approaches, and highlighting future directions and challenges, we hope to inspire further research in this exciting and rapidly advancing field.
Text-to-Audio Generation using Instruction-Tuned LLM and Latent Diffusion Model
Apr 24, 2023
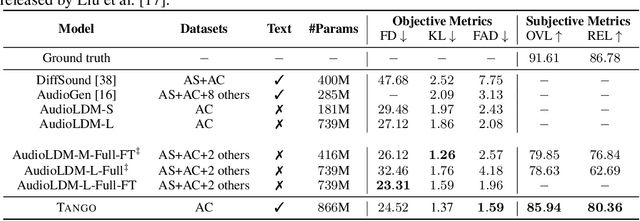


The immense scale of the recent large language models (LLM) allows many interesting properties, such as, instruction- and chain-of-thought-based fine-tuning, that has significantly improved zero- and few-shot performance in many natural language processing (NLP) tasks. Inspired by such successes, we adopt such an instruction-tuned LLM Flan-T5 as the text encoder for text-to-audio (TTA) generation -- a task where the goal is to generate an audio from its textual description. The prior works on TTA either pre-trained a joint text-audio encoder or used a non-instruction-tuned model, such as, T5. Consequently, our latent diffusion model (LDM)-based approach TANGO outperforms the state-of-the-art AudioLDM on most metrics and stays comparable on the rest on AudioCaps test set, despite training the LDM on a 63 times smaller dataset and keeping the text encoder frozen. This improvement might also be attributed to the adoption of audio pressure level-based sound mixing for training set augmentation, whereas the prior methods take a random mix.
Evaluating Parameter-Efficient Transfer Learning Approaches on SURE Benchmark for Speech Understanding
Mar 02, 2023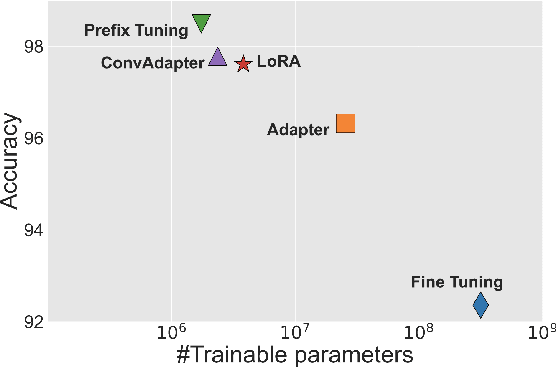

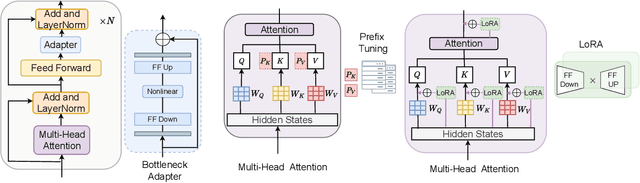

Fine-tuning is widely used as the default algorithm for transfer learning from pre-trained models. Parameter inefficiency can however arise when, during transfer learning, all the parameters of a large pre-trained model need to be updated for individual downstream tasks. As the number of parameters grows, fine-tuning is prone to overfitting and catastrophic forgetting. In addition, full fine-tuning can become prohibitively expensive when the model is used for many tasks. To mitigate this issue, parameter-efficient transfer learning algorithms, such as adapters and prefix tuning, have been proposed as a way to introduce a few trainable parameters that can be plugged into large pre-trained language models such as BERT, and HuBERT. In this paper, we introduce the Speech UndeRstanding Evaluation (SURE) benchmark for parameter-efficient learning for various speech-processing tasks. Additionally, we introduce a new adapter, ConvAdapter, based on 1D convolution. We show that ConvAdapter outperforms the standard adapters while showing comparable performance against prefix tuning and LoRA with only 0.94% of trainable parameters on some of the task in SURE. We further explore the effectiveness of parameter efficient transfer learning for speech synthesis task such as Text-to-Speech (TTS).
Accented Text-to-Speech Synthesis with a Conditional Variational Autoencoder
Nov 07, 2022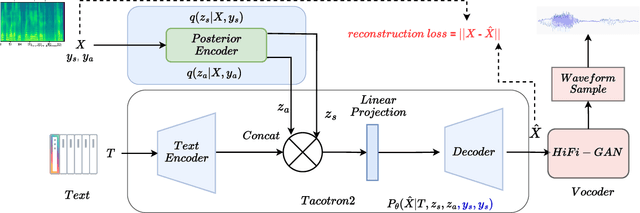
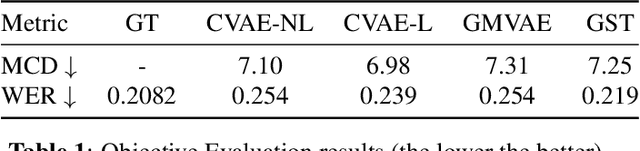

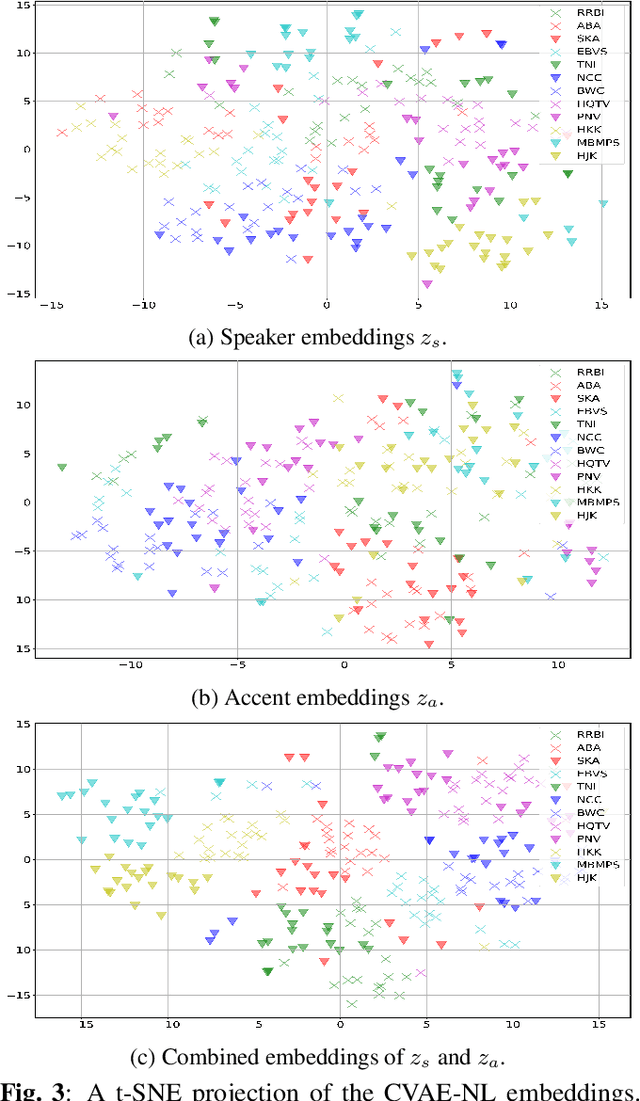
Accent plays a significant role in speech communication, influencing understanding capabilities and also conveying a person's identity. This paper introduces a novel and efficient framework for accented Text-to-Speech (TTS) synthesis based on a Conditional Variational Autoencoder. It has the ability to synthesize a selected speaker's speech that is converted to any desired target accent. Our thorough experiments validate the effectiveness of our proposed framework using both objective and subjective evaluations. The results also show remarkable performance in terms of the ability to manipulate accents in the synthesized speech and provide a promising avenue for future accented TTS research.