 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRiza Batista-Navarro
CANTONMT: Investigating Back-Translation and Model-Switch Mechanisms for Cantonese-English Neural Machine Translation
May 13, 2024
This paper investigates the development and evaluation of machine translation models from Cantonese to English, where we propose a novel approach to tackle low-resource language translations. The main objectives of the study are to develop a model that can effectively translate Cantonese to English and evaluate it against state-of-the-art commercial models. To achieve this, a new parallel corpus has been created by combining different available corpora online with preprocessing and cleaning. In addition, a monolingual Cantonese dataset has been created through web scraping to aid the synthetic parallel corpus generation. Following the data collection process, several approaches, including fine-tuning models, back-translation, and model switch, have been used. The translation quality of models has been evaluated with multiple quality metrics, including lexicon-based metrics (SacreBLEU and hLEPOR) and embedding-space metrics (COMET and BERTscore). Based on the automatic metrics, the best model is selected and compared against the 2 best commercial translators using the human evaluation framework HOPES. The best model proposed in this investigation (NLLB-mBART) with model switch mechanisms has reached comparable and even better automatic evaluation scores against State-of-the-art commercial models (Bing and Baidu Translators), with a SacreBLEU score of 16.8 on our test set. Furthermore, an open-source web application has been developed to allow users to translate between Cantonese and English, with the different trained models available for effective comparisons between models from this investigation and users. CANTONMT is available at https://github.com/kenrickkung/CantoneseTranslation
Aspect-based Sentiment Evaluation of Chess Moves (ASSESS): an NLP-based Method for Evaluating Chess Strategies from Textbooks
May 10, 2024The chess domain is well-suited for creating an artificial intelligence (AI) system that mimics real-world challenges, including decision-making. Throughout the years, minimal attention has been paid to investigating insights derived from unstructured chess data sources. In this study, we examine the complicated relationships between multiple referenced moves in a chess-teaching textbook, and propose a novel method designed to encapsulate chess knowledge derived from move-action phrases. This study investigates the feasibility of using a modified sentiment analysis method as a means for evaluating chess moves based on text. Our proposed Aspect-Based Sentiment Analysis (ABSA) method represents an advancement in evaluating the sentiment associated with referenced chess moves. By extracting insights from move-action phrases, our approach aims to provide a more fine-grained and contextually aware `chess move'-based sentiment classification. Through empirical experiments and analysis, we evaluate the performance of our fine-tuned ABSA model, presenting results that confirm the efficiency of our approach in advancing aspect-based sentiment classification within the chess domain. This research contributes to the area of game-playing by machines and shows the practical applicability of leveraging NLP techniques to understand the context of strategic games.
CantonMT: Cantonese to English NMT Platform with Fine-Tuned Models Using Synthetic Back-Translation Data
Mar 17, 2024



Neural Machine Translation (NMT) for low-resource languages is still a challenging task in front of NLP researchers. In this work, we deploy a standard data augmentation methodology by back-translation to a new language translation direction Cantonese-to-English. We present the models we fine-tuned using the limited amount of real data and the synthetic data we generated using back-translation including OpusMT, NLLB, and mBART. We carried out automatic evaluation using a range of different metrics including lexical-based and embedding-based. Furthermore. we create a user-friendly interface for the models we included in this\textsc{ CantonMT} research project and make it available to facilitate Cantonese-to-English MT research. Researchers can add more models into this platform via our open-source\textsc{ CantonMT} toolkit \url{https://github.com/kenrickkung/CantoneseTranslation}.
Learning to Play Chess from Textbooks (LEAP): a Corpus for Evaluating Chess Moves based on Sentiment Analysis
Oct 31, 2023



Learning chess strategies has been investigated widely, with most studies focussing on learning from previous games using search algorithms. Chess textbooks encapsulate grandmaster knowledge, explain playing strategies and require a smaller search space compared to traditional chess agents. This paper examines chess textbooks as a new knowledge source for enabling machines to learn how to play chess -- a resource that has not been explored previously. We developed the LEAP corpus, a first and new heterogeneous dataset with structured (chess move notations and board states) and unstructured data (textual descriptions) collected from a chess textbook containing 1164 sentences discussing strategic moves from 91 games. We firstly labelled the sentences based on their relevance, i.e., whether they are discussing a move. Each relevant sentence was then labelled according to its sentiment towards the described move. We performed empirical experiments that assess the performance of various transformer-based baseline models for sentiment analysis. Our results demonstrate the feasibility of employing transformer-based sentiment analysis models for evaluating chess moves, with the best performing model obtaining a weighted micro F_1 score of 68%. Finally, we synthesised the LEAP corpus to create a larger dataset, which can be used as a solution to the limited textual resource in the chess domain.
TIMELINE: Exhaustive Annotation of Temporal Relations Supporting the Automatic Ordering of Events in News Articles
Oct 26, 2023Temporal relation extraction models have thus far been hindered by a number of issues in existing temporal relation-annotated news datasets, including: (1) low inter-annotator agreement due to the lack of specificity of their annotation guidelines in terms of what counts as a temporal relation; (2) the exclusion of long-distance relations within a given document (those spanning across different paragraphs); and (3) the exclusion of events that are not centred on verbs. This paper aims to alleviate these issues by presenting a new annotation scheme that clearly defines the criteria based on which temporal relations should be annotated. Additionally, the scheme includes events even if they are not expressed as verbs (e.g., nominalised events). Furthermore, we propose a method for annotating all temporal relations -- including long-distance ones -- which automates the process, hence reducing time and manual effort on the part of annotators. The result is a new dataset, the TIMELINE corpus, in which improved inter-annotator agreement was obtained, in comparison with previously reported temporal relation datasets. We report the results of training and evaluating baseline temporal relation extraction models on the new corpus, and compare them with results obtained on the widely used MATRES corpus.
Towards End-User Development for IoT: A Case Study on Semantic Parsing of Cooking Recipes for Programming Kitchen Devices
Sep 25, 2023Semantic parsing of user-generated instructional text, in the way of enabling end-users to program the Internet of Things (IoT), is an underexplored area. In this study, we provide a unique annotated corpus which aims to support the transformation of cooking recipe instructions to machine-understandable commands for IoT devices in the kitchen. Each of these commands is a tuple capturing the semantics of an instruction involving a kitchen device in terms of "What", "Where", "Why" and "How". Based on this corpus, we developed machine learning-based sequence labelling methods, namely conditional random fields (CRF) and a neural network model, in order to parse recipe instructions and extract our tuples of interest from them. Our results show that while it is feasible to train semantic parsers based on our annotations, most natural-language instructions are incomplete, and thus transforming them into formal meaning representation, is not straightforward.
PULSAR: Pre-training with Extracted Healthcare Terms for Summarising Patients' Problems and Data Augmentation with Black-box Large Language Models
Jun 05, 2023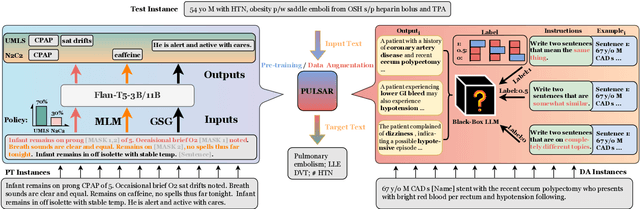


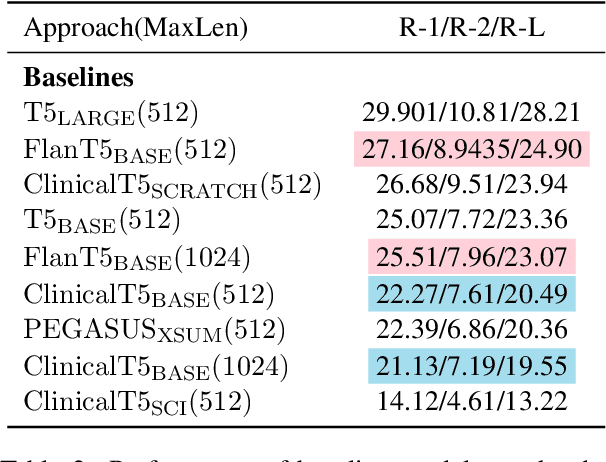
Medical progress notes play a crucial role in documenting a patient's hospital journey, including his or her condition, treatment plan, and any updates for healthcare providers. Automatic summarisation of a patient's problems in the form of a problem list can aid stakeholders in understanding a patient's condition, reducing workload and cognitive bias. BioNLP 2023 Shared Task 1A focuses on generating a list of diagnoses and problems from the provider's progress notes during hospitalisation. In this paper, we introduce our proposed approach to this task, which integrates two complementary components. One component employs large language models (LLMs) for data augmentation; the other is an abstractive summarisation LLM with a novel pre-training objective for generating the patients' problems summarised as a list. Our approach was ranked second among all submissions to the shared task. The performance of our model on the development and test datasets shows that our approach is more robust on unknown data, with an improvement of up to 3.1 points over the same size of the larger model.
Do You Hear The People Sing? Key Point Analysis via Iterative Clustering and Abstractive Summarisation
May 25, 2023



Argument summarisation is a promising but currently under-explored field. Recent work has aimed to provide textual summaries in the form of concise and salient short texts, i.e., key points (KPs), in a task known as Key Point Analysis (KPA). One of the main challenges in KPA is finding high-quality key point candidates from dozens of arguments even in a small corpus. Furthermore, evaluating key points is crucial in ensuring that the automatically generated summaries are useful. Although automatic methods for evaluating summarisation have considerably advanced over the years, they mainly focus on sentence-level comparison, making it difficult to measure the quality of a summary (a set of KPs) as a whole. Aggravating this problem is the fact that human evaluation is costly and unreproducible. To address the above issues, we propose a two-step abstractive summarisation framework based on neural topic modelling with an iterative clustering procedure, to generate key points which are aligned with how humans identify key points. Our experiments show that our framework advances the state of the art in KPA, with performance improvement of up to 14 (absolute) percentage points, in terms of both ROUGE and our own proposed evaluation metrics. Furthermore, we evaluate the generated summaries using a novel set-based evaluation toolkit. Our quantitative analysis demonstrates the effectiveness of our proposed evaluation metrics in assessing the quality of generated KPs. Human evaluation further demonstrates the advantages of our approach and validates that our proposed evaluation metric is more consistent with human judgment than ROUGE scores.
Natural Language Robot Programming: NLP integrated with autonomous robotic grasping
Apr 06, 2023



In this paper, we present a grammar-based natural language framework for robot programming, specifically for pick-and-place tasks. Our approach uses a custom dictionary of action words, designed to store together words that share meaning, allowing for easy expansion of the vocabulary by adding more action words from a lexical database. We validate our Natural Language Robot Programming (NLRP) framework through simulation and real-world experimentation, using a Franka Panda robotic arm equipped with a calibrated camera-in-hand and a microphone. Participants were asked to complete a pick-and-place task using verbal commands, which were converted into text using Google's Speech-to-Text API and processed through the NLRP framework to obtain joint space trajectories for the robot. Our results indicate that our approach has a high system usability score. The framework's dictionary can be easily extended without relying on transfer learning or large data sets. In the future, we plan to compare the presented framework with different approaches of human-assisted pick-and-place tasks via a comprehensive user study.
Towards Human-Centred Explainability Benchmarks For Text Classification
Nov 10, 2022Progress on many Natural Language Processing (NLP) tasks, such as text classification, is driven by objective, reproducible and scalable evaluation via publicly available benchmarks. However, these are not always representative of real-world scenarios where text classifiers are employed, such as sentiment analysis or misinformation detection. In this position paper, we put forward two points that aim to alleviate this problem. First, we propose to extend text classification benchmarks to evaluate the explainability of text classifiers. We review challenges associated with objectively evaluating the capabilities to produce valid explanations which leads us to the second main point: We propose to ground these benchmarks in human-centred applications, for example by using social media, gamification or to learn explainability metrics from human judgements.