 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDavid Ifeoluwa Adelani
Which Nigerian-Pidgin does Generative AI speak?: Issues about Representativeness and Bias for Multilingual and Low Resource Languages
Apr 30, 2024
Naija is the Nigerian-Pidgin spoken by approx. 120M speakers in Nigeria and it is a mixed language (e.g., English, Portuguese and Indigenous languages). Although it has mainly been a spoken language until recently, there are currently two written genres (BBC and Wikipedia) in Naija. Through statistical analyses and Machine Translation experiments, we prove that these two genres do not represent each other (i.e., there are linguistic differences in word order and vocabulary) and Generative AI operates only based on Naija written in the BBC genre. In other words, Naija written in Wikipedia genre is not represented in Generative AI.
Comparing LLM prompting with Cross-lingual transfer performance on Indigenous and Low-resource Brazilian Languages
Apr 30, 2024Large Language Models are transforming NLP for a variety of tasks. However, how LLMs perform NLP tasks for low-resource languages (LRLs) is less explored. In line with the goals of the AmericasNLP workshop, we focus on 12 LRLs from Brazil, 2 LRLs from Africa and 2 high-resource languages (HRLs) (e.g., English and Brazilian Portuguese). Our results indicate that the LLMs perform worse for the part of speech (POS) labeling of LRLs in comparison to HRLs. We explain the reasons behind this failure and provide an error analysis through examples observed in our data set.
EkoHate: Abusive Language and Hate Speech Detection for Code-switched Political Discussions on Nigerian Twitter
Apr 28, 2024Nigerians have a notable online presence and actively discuss political and topical matters. This was particularly evident throughout the 2023 general election, where Twitter was used for campaigning, fact-checking and verification, and even positive and negative discourse. However, little or none has been done in the detection of abusive language and hate speech in Nigeria. In this paper, we curated code-switched Twitter data directed at three musketeers of the governorship election on the most populous and economically vibrant state in Nigeria; Lagos state, with the view to detect offensive speech in political discussions. We developed EkoHate -- an abusive language and hate speech dataset for political discussions between the three candidates and their followers using a binary (normal vs offensive) and fine-grained four-label annotation scheme. We analysed our dataset and provided an empirical evaluation of state-of-the-art methods across both supervised and cross-lingual transfer learning settings. In the supervised setting, our evaluation results in both binary and four-label annotation schemes show that we can achieve 95.1 and 70.3 F1 points respectively. Furthermore, we show that our dataset adequately transfers very well to three publicly available offensive datasets (OLID, HateUS2020, and FountaHate), generalizing to political discussions in other regions like the US.
ANGOFA: Leveraging OFA Embedding Initialization and Synthetic Data for Angolan Language Model
Apr 03, 2024In recent years, the development of pre-trained language models (PLMs) has gained momentum, showcasing their capacity to transcend linguistic barriers and facilitate knowledge transfer across diverse languages. However, this progress has predominantly bypassed the inclusion of very-low resource languages, creating a notable void in the multilingual landscape. This paper addresses this gap by introducing four tailored PLMs specifically finetuned for Angolan languages, employing a Multilingual Adaptive Fine-tuning (MAFT) approach. In this paper, we survey the role of informed embedding initialization and synthetic data in enhancing the performance of MAFT models in downstream tasks. We improve baseline over SOTA AfroXLMR-base (developed through MAFT) and OFA (an effective embedding initialization) by 12.3 and 3.8 points respectively.
AfriMTE and AfriCOMET: Empowering COMET to Embrace Under-resourced African Languages
Nov 16, 2023Despite the progress we have recorded in scaling multilingual machine translation (MT) models and evaluation data to several under-resourced African languages, it is difficult to measure accurately the progress we have made on these languages because evaluation is often performed on n-gram matching metrics like BLEU that often have worse correlation with human judgments. Embedding-based metrics such as COMET correlate better; however, lack of evaluation data with human ratings for under-resourced languages, complexity of annotation guidelines like Multidimensional Quality Metrics (MQM), and limited language coverage of multilingual encoders have hampered their applicability to African languages. In this paper, we address these challenges by creating high-quality human evaluation data with a simplified MQM guideline for error-span annotation and direct assessment (DA) scoring for 13 typologically diverse African languages. Furthermore, we develop AfriCOMET, a COMET evaluation metric for African languages by leveraging DA training data from high-resource languages and African-centric multilingual encoder (AfroXLM-Roberta) to create the state-of-the-art evaluation metric for African languages MT with respect to Spearman-rank correlation with human judgments (+0.406).
SIB-200: A Simple, Inclusive, and Big Evaluation Dataset for Topic Classification in 200+ Languages and Dialects
Sep 14, 2023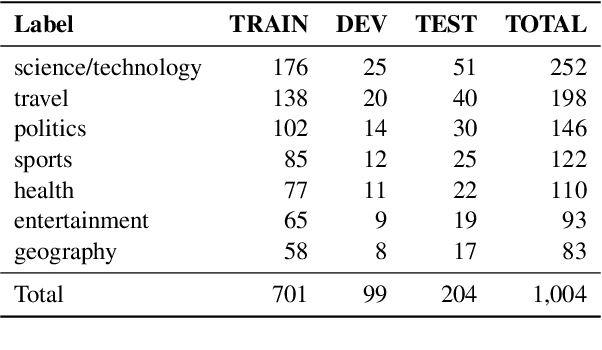

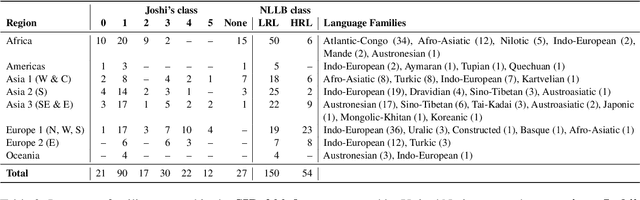
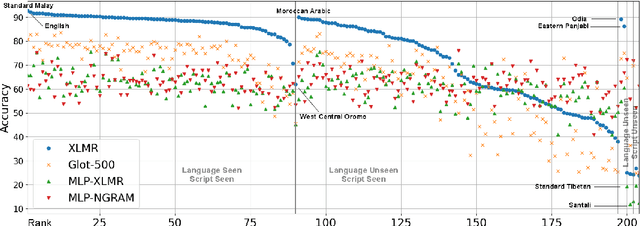
Despite the progress we have recorded in the last few years in multilingual natural language processing, evaluation is typically limited to a small set of languages with available datasets which excludes a large number of low-resource languages. In this paper, we created SIB-200 -- a large-scale open-sourced benchmark dataset for topic classification in 200 languages and dialects to address the lack of evaluation dataset for Natural Language Understanding (NLU). For many of the languages covered in SIB-200, this is the first publicly available evaluation dataset for NLU. The dataset is based on Flores-200 machine translation corpus. We annotated the English portion of the dataset and extended the sentence-level annotation to the remaining 203 languages covered in the corpus. Despite the simplicity of this task, our evaluation in full-supervised setting, cross-lingual transfer setting and prompting of large language model setting show that there is still a large gap between the performance of high-resource and low-resource languages when multilingual evaluation is scaled to numerous world languages. We found that languages unseen during the pre-training of multilingual language models, under-represented language families (like Nilotic and Altantic-Congo), and languages from the regions of Africa, Americas, Oceania and South East Asia, often have the lowest performance on our topic classification dataset. We hope our dataset will encourage a more inclusive evaluation of multilingual language models on a more diverse set of languages. https://github.com/dadelani/sib-200
YORC: Yoruba Reading Comprehension dataset
Aug 18, 2023In this paper, we create YORC: a new multi-choice Yoruba Reading Comprehension dataset that is based on Yoruba high-school reading comprehension examination. We provide baseline results by performing cross-lingual transfer using existing English RACE dataset based on a pre-trained encoder-only model. Additionally, we provide results by prompting large language models (LLMs) like GPT-4.
ÌròyìnSpeech: A multi-purpose Yorùbá Speech Corpus
Jul 29, 2023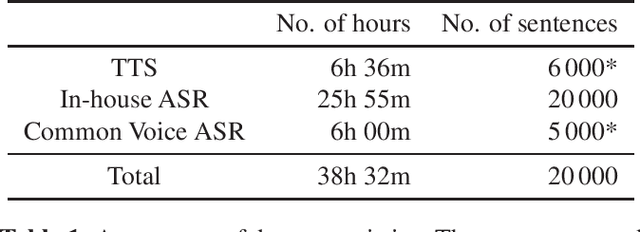

We introduce the \`{I}r\`{o}y\`{i}nSpeech corpus -- a new dataset influenced by a desire to increase the amount of high quality, freely available, contemporary Yor\`{u}b\'{a} speech. We release a multi-purpose dataset that can be used for both TTS and ASR tasks. We curated text sentences from the news and creative writing domains under an open license i.e., CC-BY-4.0 and had multiple speakers record each sentence. We provide 5000 of our utterances to the Common Voice platform to crowdsource transcriptions online. The dataset has 38.5 hours of data in total, recorded by 80 volunteers.
Improving Language Plasticity via Pretraining with Active Forgetting
Jul 04, 2023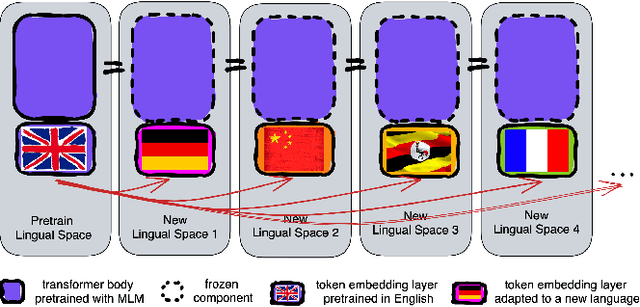

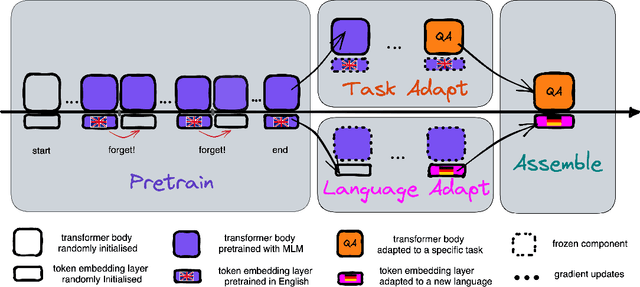

Pretrained language models (PLMs) are today the primary model for natural language processing. Despite their impressive downstream performance, it can be difficult to apply PLMs to new languages, a barrier to making their capabilities universally accessible. While prior work has shown it possible to address this issue by learning a new embedding layer for the new language, doing so is both data and compute inefficient. We propose to use an active forgetting mechanism during pretraining, as a simple way of creating PLMs that can quickly adapt to new languages. Concretely, by resetting the embedding layer every K updates during pretraining, we encourage the PLM to improve its ability of learning new embeddings within a limited number of updates, similar to a meta-learning effect. Experiments with RoBERTa show that models pretrained with our forgetting mechanism not only demonstrate faster convergence during language adaptation but also outperform standard ones in a low-data regime, particularly for languages that are distant from English.
NollySenti: Leveraging Transfer Learning and Machine Translation for Nigerian Movie Sentiment Classification
May 18, 2023
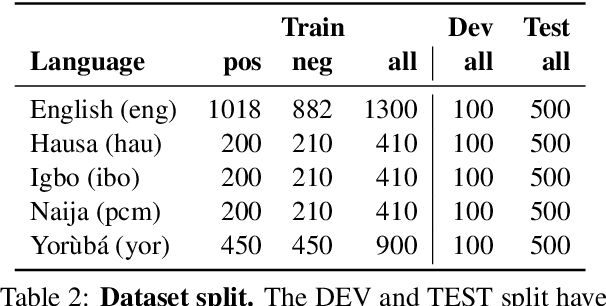
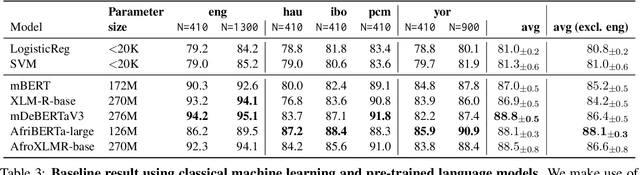

Africa has over 2000 indigenous languages but they are under-represented in NLP research due to lack of datasets. In recent years, there have been progress in developing labeled corpora for African languages. However, they are often available in a single domain and may not generalize to other domains. In this paper, we focus on the task of sentiment classification for cross domain adaptation. We create a new dataset, NollySenti - based on the Nollywood movie reviews for five languages widely spoken in Nigeria (English, Hausa, Igbo, Nigerian-Pidgin, and Yoruba. We provide an extensive empirical evaluation using classical machine learning methods and pre-trained language models. Leveraging transfer learning, we compare the performance of cross-domain adaptation from Twitter domain, and cross-lingual adaptation from English language. Our evaluation shows that transfer from English in the same target domain leads to more than 5% improvement in accuracy compared to transfer from Twitter in the same language. To further mitigate the domain difference, we leverage machine translation (MT) from English to other Nigerian languages, which leads to a further improvement of 7% over cross-lingual evaluation. While MT to low-resource languages are often of low quality, through human evaluation, we show that most of the translated sentences preserve the sentiment of the original English reviews.