 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEleftheria Briakou
Explaining with Contrastive Phrasal Highlighting: A Case Study in Assisting Humans to Detect Translation Differences
Dec 04, 2023
Explainable NLP techniques primarily explain by answering "Which tokens in the input are responsible for this prediction?''. We argue that for NLP models that make predictions by comparing two input texts, it is more useful to explain by answering "What differences between the two inputs explain this prediction?''. We introduce a technique to generate contrastive highlights that explain the predictions of a semantic divergence model via phrase-alignment-guided erasure. We show that the resulting highlights match human rationales of cross-lingual semantic differences better than popular post-hoc saliency techniques and that they successfully help people detect fine-grained meaning differences in human translations and critical machine translation errors.
AfriMTE and AfriCOMET: Empowering COMET to Embrace Under-resourced African Languages
Nov 16, 2023Despite the progress we have recorded in scaling multilingual machine translation (MT) models and evaluation data to several under-resourced African languages, it is difficult to measure accurately the progress we have made on these languages because evaluation is often performed on n-gram matching metrics like BLEU that often have worse correlation with human judgments. Embedding-based metrics such as COMET correlate better; however, lack of evaluation data with human ratings for under-resourced languages, complexity of annotation guidelines like Multidimensional Quality Metrics (MQM), and limited language coverage of multilingual encoders have hampered their applicability to African languages. In this paper, we address these challenges by creating high-quality human evaluation data with a simplified MQM guideline for error-span annotation and direct assessment (DA) scoring for 13 typologically diverse African languages. Furthermore, we develop AfriCOMET, a COMET evaluation metric for African languages by leveraging DA training data from high-resource languages and African-centric multilingual encoder (AfroXLM-Roberta) to create the state-of-the-art evaluation metric for African languages MT with respect to Spearman-rank correlation with human judgments (+0.406).
What Else Do I Need to Know? The Effect of Background Information on Users' Reliance on AI Systems
May 23, 2023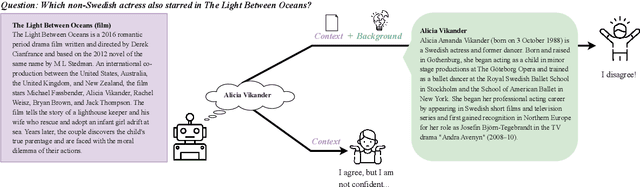
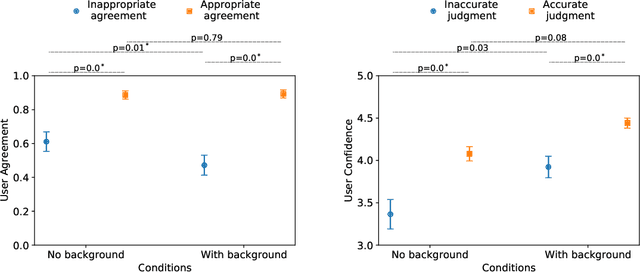
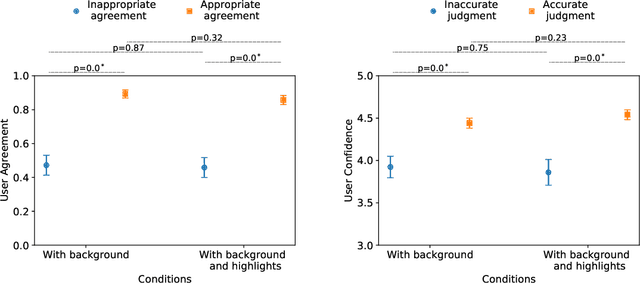
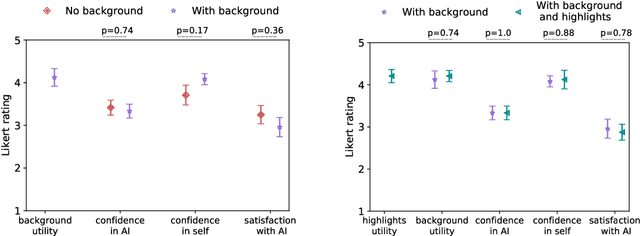
AI systems have shown impressive performance at answering questions by retrieving relevant context. However, with the increasingly large models, it is impossible and often undesirable to constrain models' knowledge or reasoning to only the retrieved context. This leads to a mismatch between the information that these models access to derive the answer and the information available to the user consuming the AI predictions to assess the AI predicted answer. In this work, we study how users interact with AI systems in absence of sufficient information to assess AI predictions. Further, we ask the question of whether adding the requisite background alleviates the concerns around over-reliance in AI predictions. Our study reveals that users rely on AI predictions even in the absence of sufficient information needed to assess its correctness. Providing the relevant background, however, helps users catch AI errors better, reducing over-reliance on incorrect AI predictions. On the flip side, background information also increases users' confidence in their correct as well as incorrect judgments. Contrary to common expectation, aiding a user's perusal of the context and the background through highlights is not helpful in alleviating the issue of over-confidence stemming from availability of more information. Our work aims to highlight the gap between how NLP developers perceive informational need in human-AI interaction and the actual human interaction with the information available to them.
Searching for Needles in a Haystack: On the Role of Incidental Bilingualism in PaLM's Translation Capability
May 17, 2023
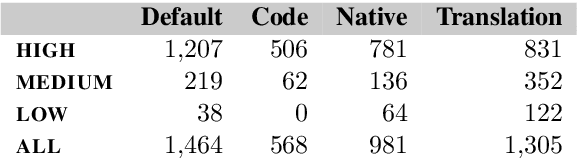
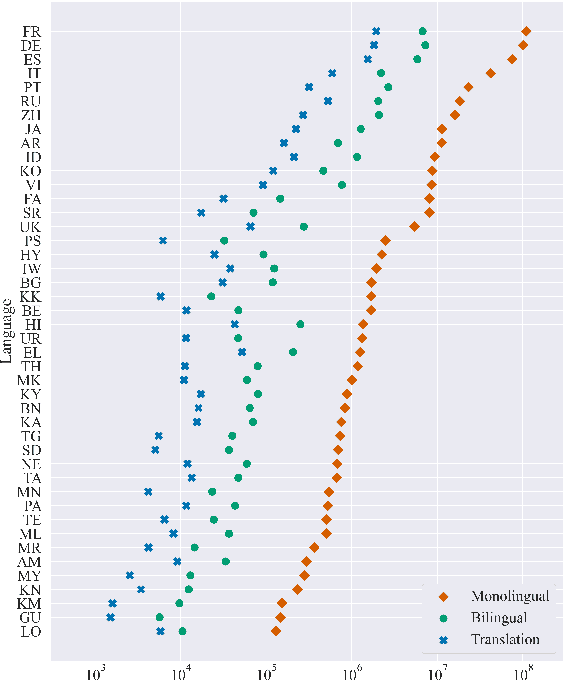
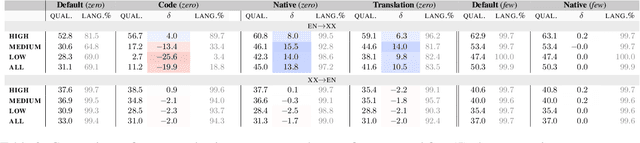
Large, multilingual language models exhibit surprisingly good zero- or few-shot machine translation capabilities, despite having never seen the intentionally-included translation examples provided to typical neural translation systems. We investigate the role of incidental bilingualism -- the unintentional consumption of bilingual signals, including translation examples -- in explaining the translation capabilities of large language models, taking the Pathways Language Model (PaLM) as a case study. We introduce a mixed-method approach to measure and understand incidental bilingualism at scale. We show that PaLM is exposed to over 30 million translation pairs across at least 44 languages. Furthermore, the amount of incidental bilingual content is highly correlated with the amount of monolingual in-language content for non-English languages. We relate incidental bilingual content to zero-shot prompts and show that it can be used to mine new prompts to improve PaLM's out-of-English zero-shot translation quality. Finally, in a series of small-scale ablations, we show that its presence has a substantial impact on translation capabilities, although this impact diminishes with model scale.
Understanding and Detecting Hallucinations in Neural Machine Translation via Model Introspection
Jan 18, 2023
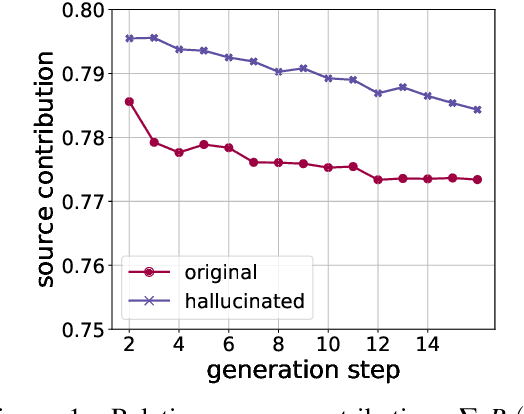

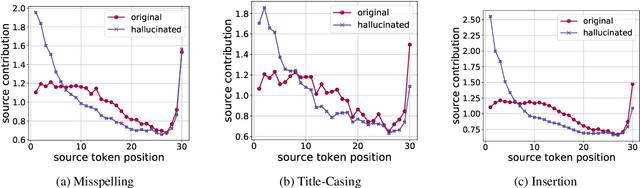
Neural sequence generation models are known to "hallucinate", by producing outputs that are unrelated to the source text. These hallucinations are potentially harmful, yet it remains unclear in what conditions they arise and how to mitigate their impact. In this work, we first identify internal model symptoms of hallucinations by analyzing the relative token contributions to the generation in contrastive hallucinated vs. non-hallucinated outputs generated via source perturbations. We then show that these symptoms are reliable indicators of natural hallucinations, by using them to design a lightweight hallucination detector which outperforms both model-free baselines and strong classifiers based on quality estimation or large pre-trained models on manually annotated English-Chinese and German-English translation test beds.
Can Synthetic Translations Improve Bitext Quality?
Mar 15, 2022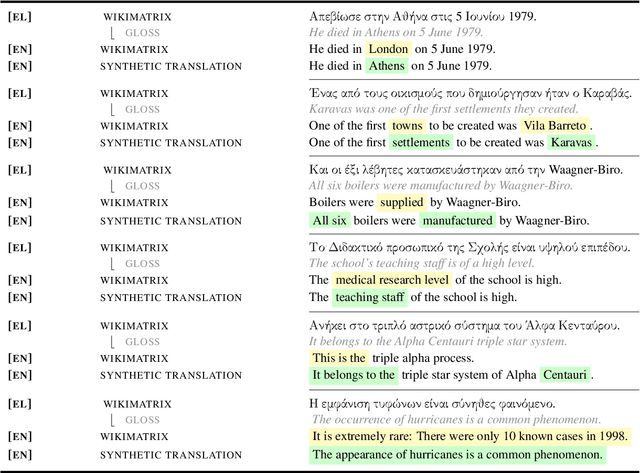
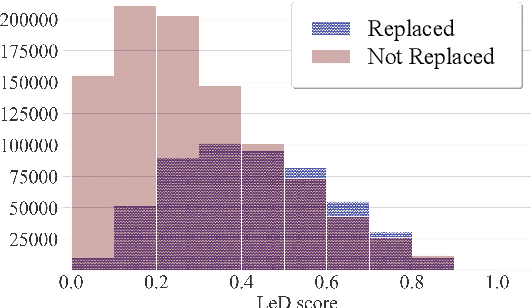
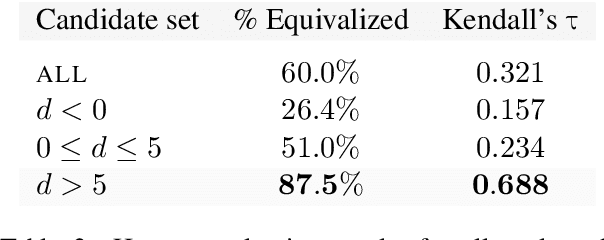
Synthetic translations have been used for a wide range of NLP tasks primarily as a means of data augmentation. This work explores, instead, how synthetic translations can be used to revise potentially imperfect reference translations in mined bitext. We find that synthetic samples can improve bitext quality without any additional bilingual supervision when they replace the originals based on a semantic equivalence classifier that helps mitigate NMT noise. The improved quality of the revised bitext is confirmed intrinsically via human evaluation and extrinsically through bilingual induction and MT tasks.
BitextEdit: Automatic Bitext Editing for Improved Low-Resource Machine Translation
Nov 12, 2021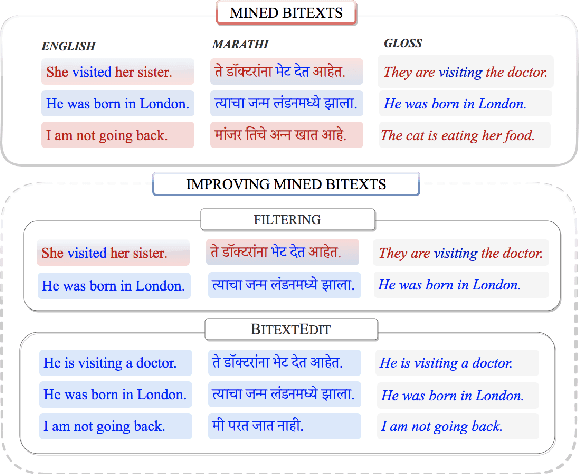
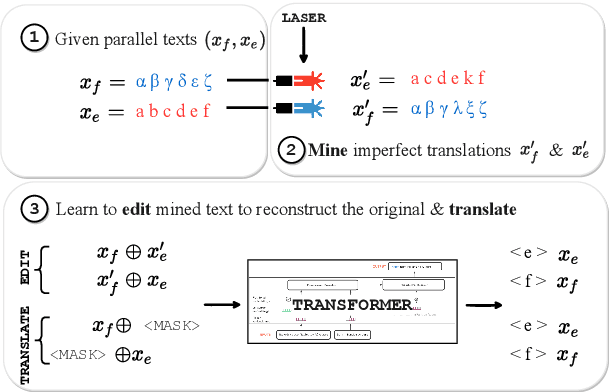
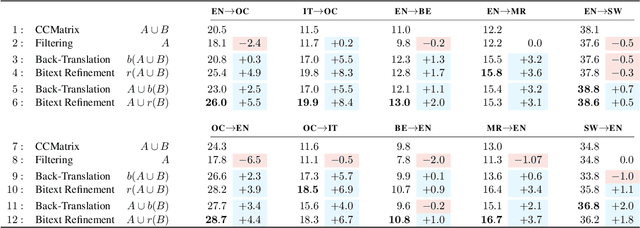
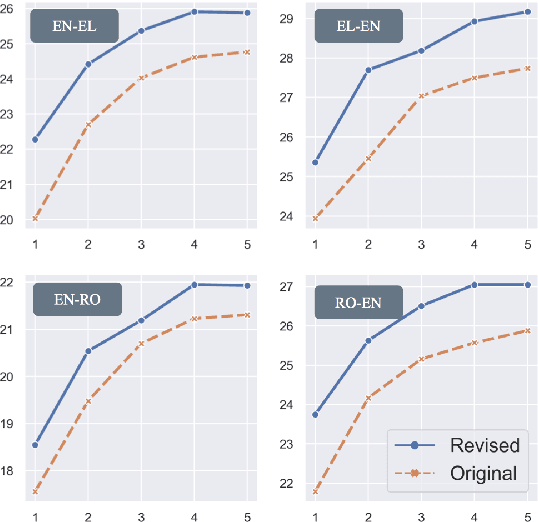
Mined bitexts can contain imperfect translations that yield unreliable training signals for Neural Machine Translation (NMT). While filtering such pairs out is known to improve final model quality, we argue that it is suboptimal in low-resource conditions where even mined data can be limited. In our work, we propose instead, to refine the mined bitexts via automatic editing: given a sentence in a language xf, and a possibly imperfect translation of it xe, our model generates a revised version xf' or xe' that yields a more equivalent translation pair (i.e., <xf, xe'> or <xf', xe>). We use a simple editing strategy by (1) mining potentially imperfect translations for each sentence in a given bitext, (2) learning a model to reconstruct the original translations and translate, in a multi-task fashion. Experiments demonstrate that our approach successfully improves the quality of CCMatrix mined bitext for 5 low-resource language-pairs and 10 translation directions by up to ~ 8 BLEU points, in most cases improving upon a competitive back-translation baseline.
Evaluating the Evaluation Metrics for Style Transfer: A Case Study in Multilingual Formality Transfer
Oct 20, 2021
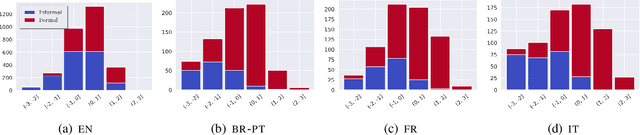
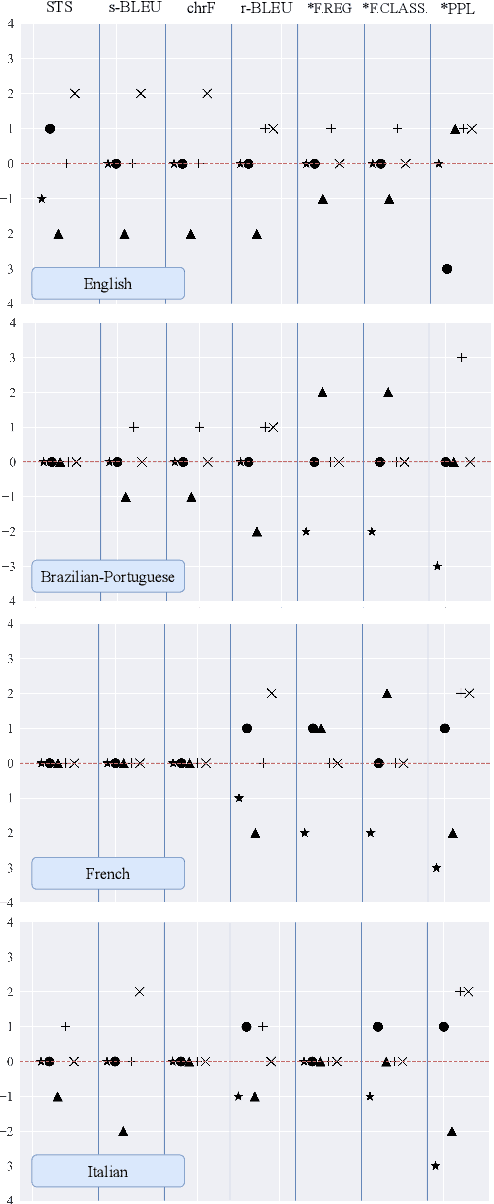
While the field of style transfer (ST) has been growing rapidly, it has been hampered by a lack of standardized practices for automatic evaluation. In this paper, we evaluate leading ST automatic metrics on the oft-researched task of formality style transfer. Unlike previous evaluations, which focus solely on English, we expand our focus to Brazilian-Portuguese, French, and Italian, making this work the first multilingual evaluation of metrics in ST. We outline best practices for automatic evaluation in (formality) style transfer and identify several models that correlate well with human judgments and are robust across languages. We hope that this work will help accelerate development in ST, where human evaluation is often challenging to collect.
A Review of Human Evaluation for Style Transfer
Jun 09, 2021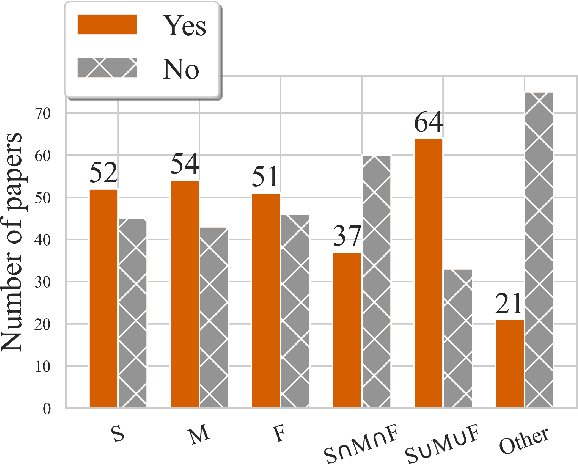
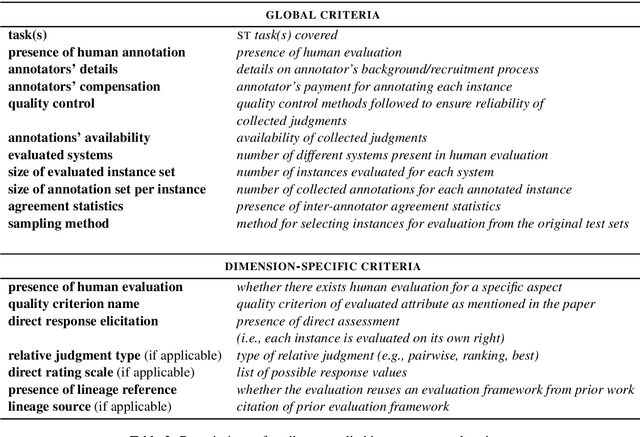
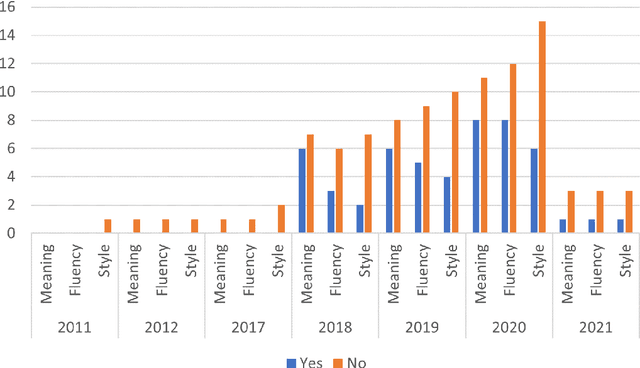
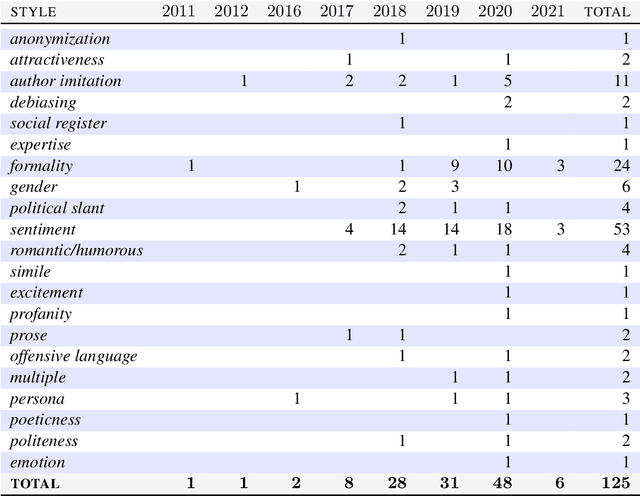
This paper reviews and summarizes human evaluation practices described in 97 style transfer papers with respect to three main evaluation aspects: style transfer, meaning preservation, and fluency. In principle, evaluations by human raters should be the most reliable. However, in style transfer papers, we find that protocols for human evaluations are often underspecified and not standardized, which hampers the reproducibility of research in this field and progress toward better human and automatic evaluation methods.
Beyond Noise: Mitigating the Impact of Fine-grained Semantic Divergences on Neural Machine Translation
May 31, 2021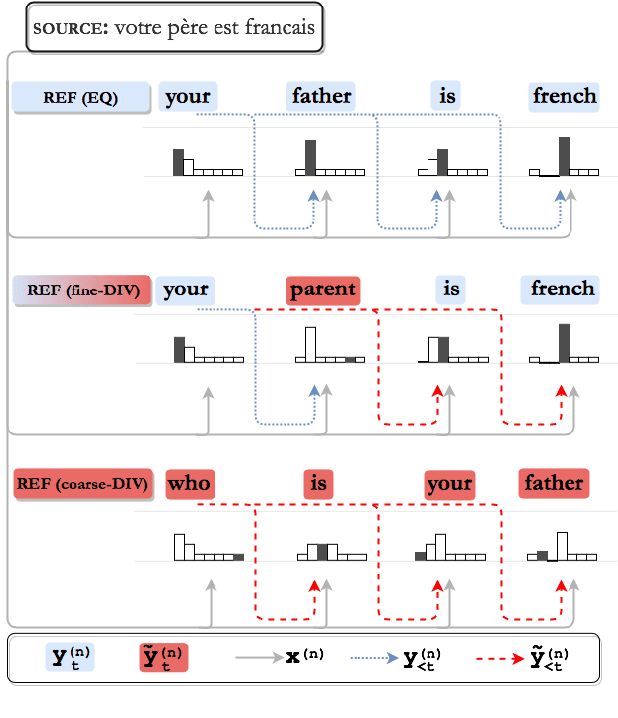

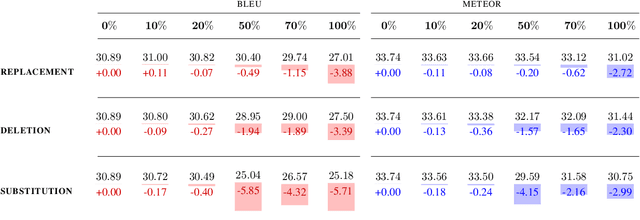
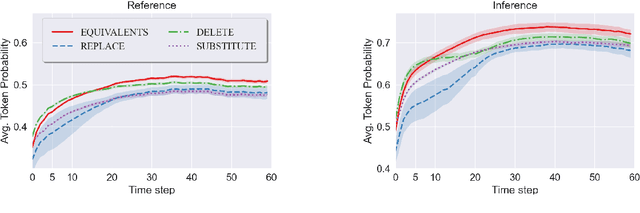
While it has been shown that Neural Machine Translation (NMT) is highly sensitive to noisy parallel training samples, prior work treats all types of mismatches between source and target as noise. As a result, it remains unclear how samples that are mostly equivalent but contain a small number of semantically divergent tokens impact NMT training. To close this gap, we analyze the impact of different types of fine-grained semantic divergences on Transformer models. We show that models trained on synthetic divergences output degenerated text more frequently and are less confident in their predictions. Based on these findings, we introduce a divergent-aware NMT framework that uses factors to help NMT recover from the degradation caused by naturally occurring divergences, improving both translation quality and model calibration on EN-FR tasks.