 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIgor Vasiljevic
Linearizing Large Language Models
May 10, 2024
Linear transformers have emerged as a subquadratic-time alternative to softmax attention and have garnered significant interest due to their fixed-size recurrent state that lowers inference cost. However, their original formulation suffers from poor scaling and underperforms compute-matched transformers. Recent linear models such as RWKV and Mamba have attempted to address these shortcomings by proposing novel time-mixing and gating architectures, but pre-training large language models requires significant data and compute investments. Thus, the search for subquadratic architectures is limited by the availability of compute and quality pre-training datasets. As a cost-effective alternative to pre-training linear transformers, we propose Scalable UPtraining for Recurrent Attention (SUPRA). We present a method to uptrain existing large pre-trained transformers into Recurrent Neural Networks (RNNs) with a modest compute budget. This allows us to leverage the strong pre-training data and performance of existing transformer LLMs, while requiring 5% of the training cost. We find that our linearization technique leads to competitive performance on standard benchmarks, but we identify persistent in-context learning and long-context modeling shortfalls for even the largest linear models. Our code and models can be found at https://github.com/TRI-ML/linear_open_lm.
Transcrib3D: 3D Referring Expression Resolution through Large Language Models
Apr 30, 2024If robots are to work effectively alongside people, they must be able to interpret natural language references to objects in their 3D environment. Understanding 3D referring expressions is challenging -- it requires the ability to both parse the 3D structure of the scene and correctly ground free-form language in the presence of distraction and clutter. We introduce Transcrib3D, an approach that brings together 3D detection methods and the emergent reasoning capabilities of large language models (LLMs). Transcrib3D uses text as the unifying medium, which allows us to sidestep the need to learn shared representations connecting multi-modal inputs, which would require massive amounts of annotated 3D data. As a demonstration of its effectiveness, Transcrib3D achieves state-of-the-art results on 3D reference resolution benchmarks, with a great leap in performance from previous multi-modality baselines. To improve upon zero-shot performance and facilitate local deployment on edge computers and robots, we propose self-correction for fine-tuning that trains smaller models, resulting in performance close to that of large models. We show that our method enables a real robot to perform pick-and-place tasks given queries that contain challenging referring expressions. Project site is at https://ripl.github.io/Transcrib3D.
Language models scale reliably with over-training and on downstream tasks
Mar 13, 2024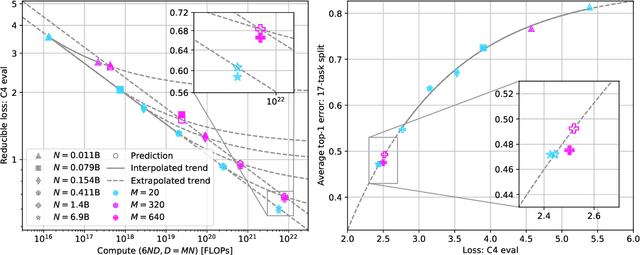
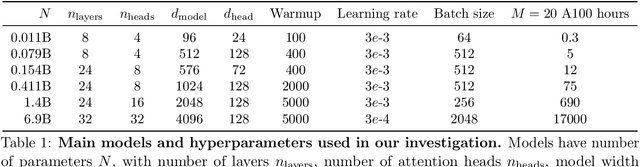
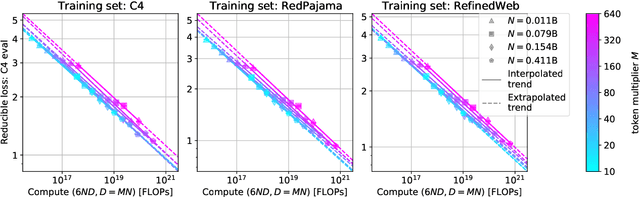

Scaling laws are useful guides for developing language models, but there are still gaps between current scaling studies and how language models are ultimately trained and evaluated. For instance, scaling is usually studied in the compute-optimal training regime (i.e., "Chinchilla optimal" regime); however, in practice, models are often over-trained to reduce inference costs. Moreover, scaling laws mostly predict loss on next-token prediction, but ultimately models are compared based on downstream task performance. In this paper, we address both shortcomings. To do so, we create a testbed of 104 models with 0.011B to 6.9B parameters trained with various numbers of tokens on three data distributions. First, we investigate scaling in the over-trained regime. We fit scaling laws that extrapolate in both the number of model parameters and the ratio of training tokens to parameters. This enables us to predict the validation loss of a 1.4B parameter, 900B token run (i.e., 32$\times$ over-trained) and a 6.9B parameter, 138B token run$\unicode{x2014}$each from experiments that take 300$\times$ less compute. Second, we relate the perplexity of a language model to its downstream task performance via a power law. We use this law to predict top-1 error averaged over downstream tasks for the two aforementioned models using experiments that take 20$\times$ less compute. Our experiments are available at https://github.com/mlfoundations/scaling.
Robust Self-Supervised Extrinsic Self-Calibration
Aug 07, 2023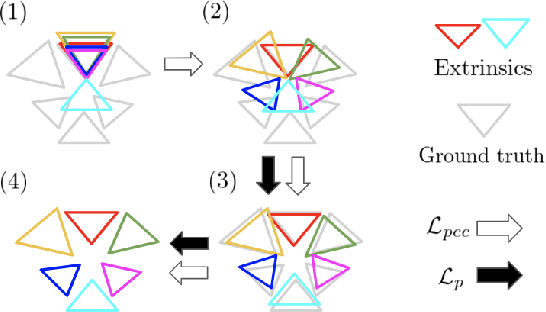



Autonomous vehicles and robots need to operate over a wide variety of scenarios in order to complete tasks efficiently and safely. Multi-camera self-supervised monocular depth estimation from videos is a promising way to reason about the environment, as it generates metrically scaled geometric predictions from visual data without requiring additional sensors. However, most works assume well-calibrated extrinsics to fully leverage this multi-camera setup, even though accurate and efficient calibration is still a challenging problem. In this work, we introduce a novel method for extrinsic calibration that builds upon the principles of self-supervised monocular depth and ego-motion learning. Our proposed curriculum learning strategy uses monocular depth and pose estimators with velocity supervision to estimate extrinsics, and then jointly learns extrinsic calibration along with depth and pose for a set of overlapping cameras rigidly attached to a moving vehicle. Experiments on a benchmark multi-camera dataset (DDAD) demonstrate that our method enables self-calibration in various scenes robustly and efficiently compared to a traditional vision-based pose estimation pipeline. Furthermore, we demonstrate the benefits of extrinsics self-calibration as a way to improve depth prediction via joint optimization.
* Project page: https://sites.google.com/view/tri-sesc
Towards Zero-Shot Scale-Aware Monocular Depth Estimation
Jun 29, 2023
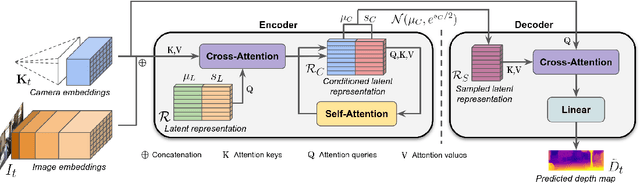

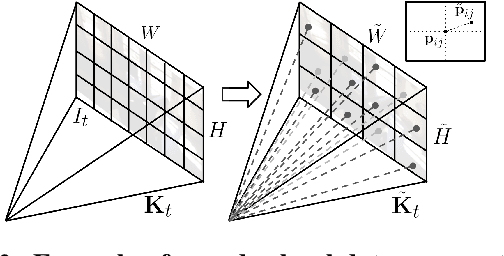
Monocular depth estimation is scale-ambiguous, and thus requires scale supervision to produce metric predictions. Even so, the resulting models will be geometry-specific, with learned scales that cannot be directly transferred across domains. Because of that, recent works focus instead on relative depth, eschewing scale in favor of improved up-to-scale zero-shot transfer. In this work we introduce ZeroDepth, a novel monocular depth estimation framework capable of predicting metric scale for arbitrary test images from different domains and camera parameters. This is achieved by (i) the use of input-level geometric embeddings that enable the network to learn a scale prior over objects; and (ii) decoupling the encoder and decoder stages, via a variational latent representation that is conditioned on single frame information. We evaluated ZeroDepth targeting both outdoor (KITTI, DDAD, nuScenes) and indoor (NYUv2) benchmarks, and achieved a new state-of-the-art in both settings using the same pre-trained model, outperforming methods that train on in-domain data and require test-time scaling to produce metric estimates.
NeRFuser: Large-Scale Scene Representation by NeRF Fusion
May 22, 2023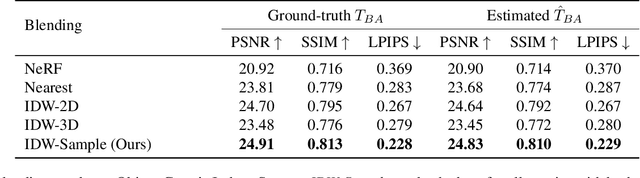

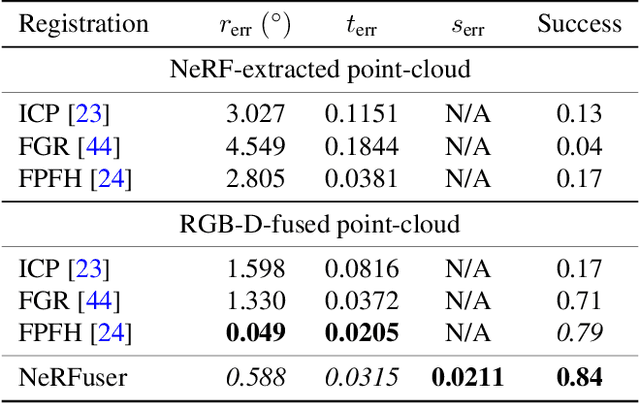
A practical benefit of implicit visual representations like Neural Radiance Fields (NeRFs) is their memory efficiency: large scenes can be efficiently stored and shared as small neural nets instead of collections of images. However, operating on these implicit visual data structures requires extending classical image-based vision techniques (e.g., registration, blending) from image sets to neural fields. Towards this goal, we propose NeRFuser, a novel architecture for NeRF registration and blending that assumes only access to pre-generated NeRFs, and not the potentially large sets of images used to generate them. We propose registration from re-rendering, a technique to infer the transformation between NeRFs based on images synthesized from individual NeRFs. For blending, we propose sample-based inverse distance weighting to blend visual information at the ray-sample level. We evaluate NeRFuser on public benchmarks and a self-collected object-centric indoor dataset, showing the robustness of our method, including to views that are challenging to render from the individual source NeRFs.
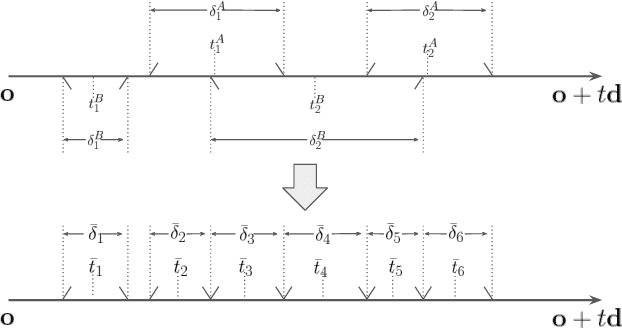
DeLiRa: Self-Supervised Depth, Light, and Radiance Fields
Apr 06, 2023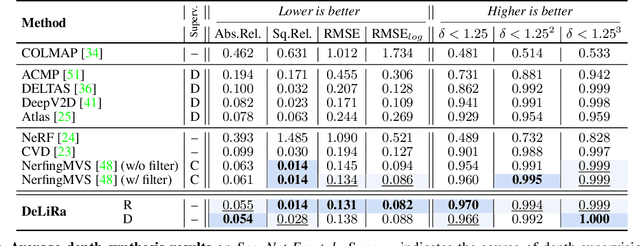
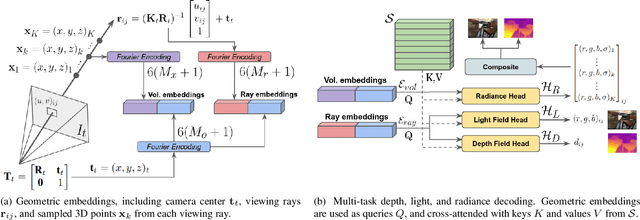
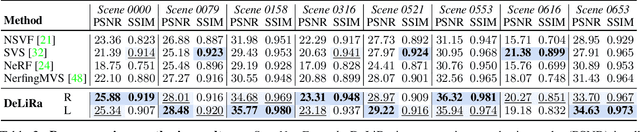
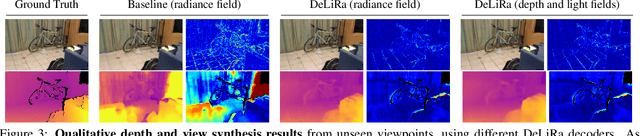
Differentiable volumetric rendering is a powerful paradigm for 3D reconstruction and novel view synthesis. However, standard volume rendering approaches struggle with degenerate geometries in the case of limited viewpoint diversity, a common scenario in robotics applications. In this work, we propose to use the multi-view photometric objective from the self-supervised depth estimation literature as a geometric regularizer for volumetric rendering, significantly improving novel view synthesis without requiring additional information. Building upon this insight, we explore the explicit modeling of scene geometry using a generalist Transformer, jointly learning a radiance field as well as depth and light fields with a set of shared latent codes. We demonstrate that sharing geometric information across tasks is mutually beneficial, leading to improvements over single-task learning without an increase in network complexity. Our DeLiRa architecture achieves state-of-the-art results on the ScanNet benchmark, enabling high quality volumetric rendering as well as real-time novel view and depth synthesis in the limited viewpoint diversity setting.
Neural Camera Models
Aug 27, 2022



Modern computer vision has moved beyond the domain of internet photo collections and into the physical world, guiding camera-equipped robots and autonomous cars through unstructured environments. To enable these embodied agents to interact with real-world objects, cameras are increasingly being used as depth sensors, reconstructing the environment for a variety of downstream reasoning tasks. Machine-learning-aided depth perception, or depth estimation, predicts for each pixel in an image the distance to the imaged scene point. While impressive strides have been made in depth estimation, significant challenges remain: (1) ground truth depth labels are difficult and expensive to collect at scale, (2) camera information is typically assumed to be known, but is often unreliable and (3) restrictive camera assumptions are common, even though a great variety of camera types and lenses are used in practice. In this thesis, we focus on relaxing these assumptions, and describe contributions toward the ultimate goal of turning cameras into truly generic depth sensors.
Depth Field Networks for Generalizable Multi-view Scene Representation
Jul 28, 2022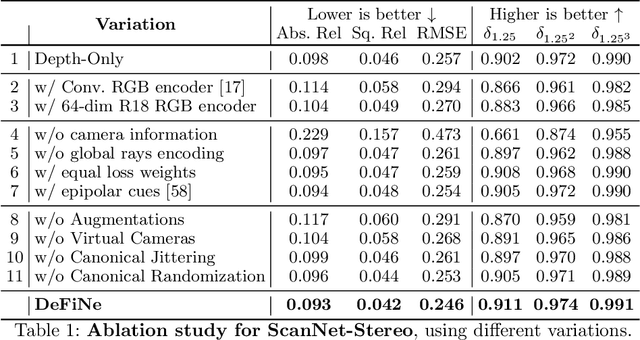
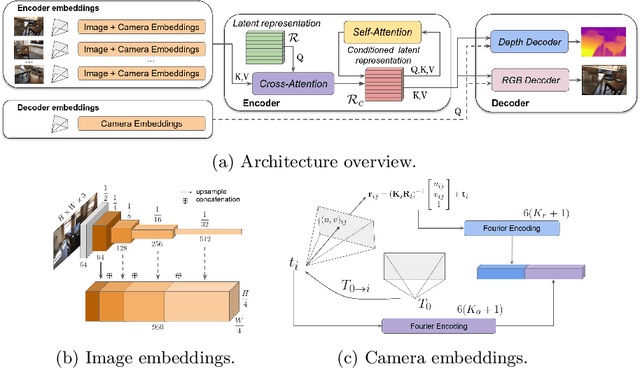
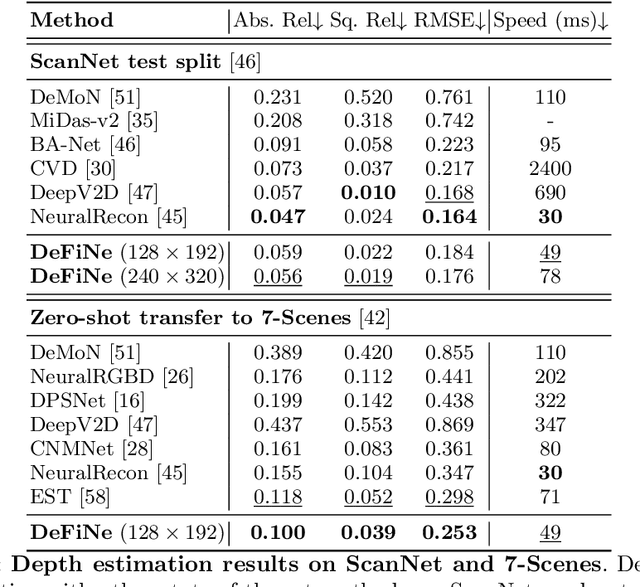
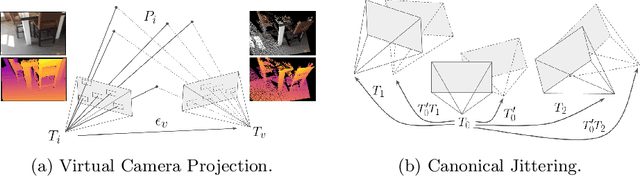
Modern 3D computer vision leverages learning to boost geometric reasoning, mapping image data to classical structures such as cost volumes or epipolar constraints to improve matching. These architectures are specialized according to the particular problem, and thus require significant task-specific tuning, often leading to poor domain generalization performance. Recently, generalist Transformer architectures have achieved impressive results in tasks such as optical flow and depth estimation by encoding geometric priors as inputs rather than as enforced constraints. In this paper, we extend this idea and propose to learn an implicit, multi-view consistent scene representation, introducing a series of 3D data augmentation techniques as a geometric inductive prior to increase view diversity. We also show that introducing view synthesis as an auxiliary task further improves depth estimation. Our Depth Field Networks (DeFiNe) achieve state-of-the-art results in stereo and video depth estimation without explicit geometric constraints, and improve on zero-shot domain generalization by a wide margin.
Self-Supervised Camera Self-Calibration from Video
Dec 06, 2021



Camera calibration is integral to robotics and computer vision algorithms that seek to infer geometric properties of the scene from visual input streams. In practice, calibration is a laborious procedure requiring specialized data collection and careful tuning. This process must be repeated whenever the parameters of the camera change, which can be a frequent occurrence for mobile robots and autonomous vehicles. In contrast, self-supervised depth and ego-motion estimation approaches can bypass explicit calibration by inferring per-frame projection models that optimize a view synthesis objective. In this paper, we extend this approach to explicitly calibrate a wide range of cameras from raw videos in the wild. We propose a learning algorithm to regress per-sequence calibration parameters using an efficient family of general camera models. Our procedure achieves self-calibration results with sub-pixel reprojection error, outperforming other learning-based methods. We validate our approach on a wide variety of camera geometries, including perspective, fisheye, and catadioptric. Finally, we show that our approach leads to improvements in the downstream task of depth estimation, achieving state-of-the-art results on the EuRoC dataset with greater computational efficiency than contemporary methods.