 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatthew R. Walter
MANGO: A Benchmark for Evaluating Mapping and Navigation Abilities of Large Language Models
Mar 29, 2024
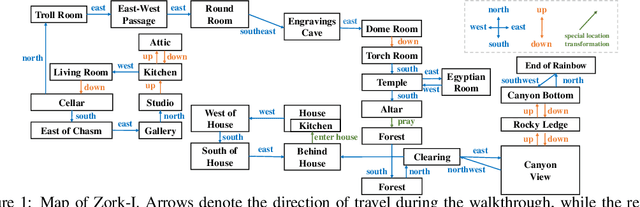
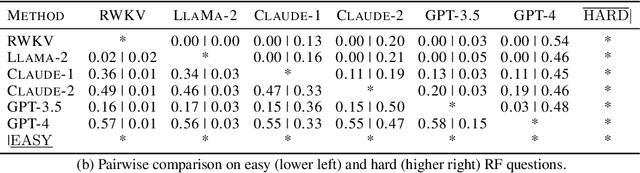
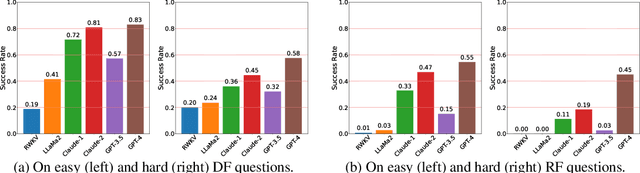
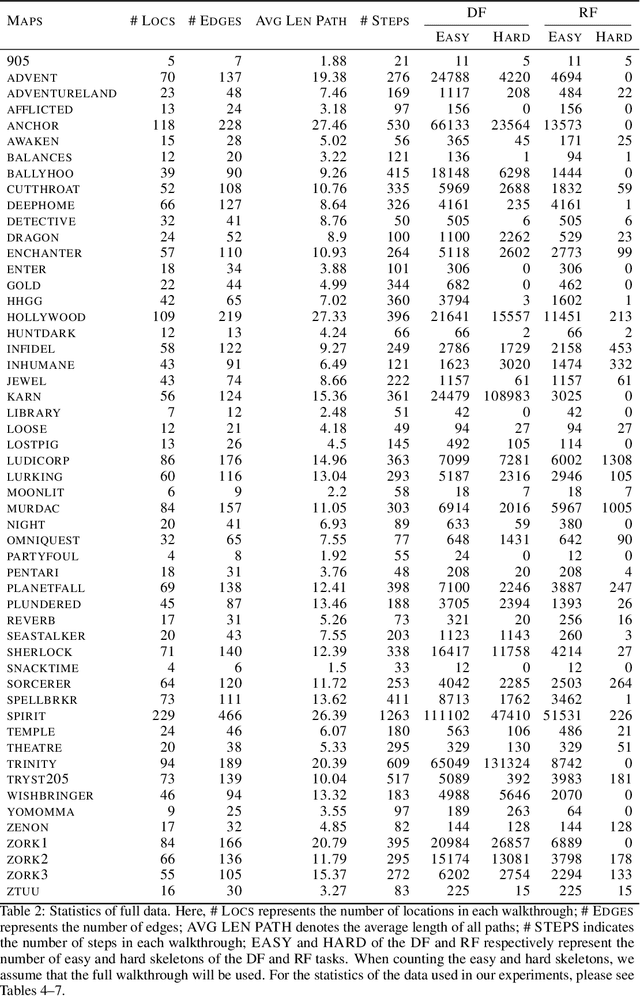
Large language models such as ChatGPT and GPT-4 have recently achieved astonishing performance on a variety of natural language processing tasks. In this paper, we propose MANGO, a benchmark to evaluate their capabilities to perform text-based mapping and navigation. Our benchmark includes 53 mazes taken from a suite of textgames: each maze is paired with a walkthrough that visits every location but does not cover all possible paths. The task is question-answering: for each maze, a large language model reads the walkthrough and answers hundreds of mapping and navigation questions such as "How should you go to Attic from West of House?" and "Where are we if we go north and east from Cellar?". Although these questions are easy to humans, it turns out that even GPT-4, the best-to-date language model, performs poorly at answering them. Further, our experiments suggest that a strong mapping and navigation ability would benefit large language models in performing relevant downstream tasks, such as playing textgames. Our MANGO benchmark will facilitate future research on methods that improve the mapping and navigation capabilities of language models. We host our leaderboard, data, code, and evaluation program at https://mango.ttic.edu and https://github.com/oaklight/mango/.
6-DoF Stability Field via Diffusion Models
Oct 26, 2023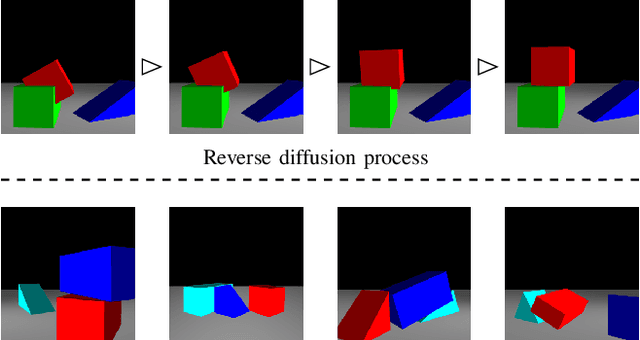
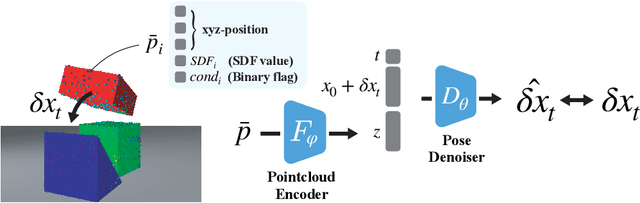
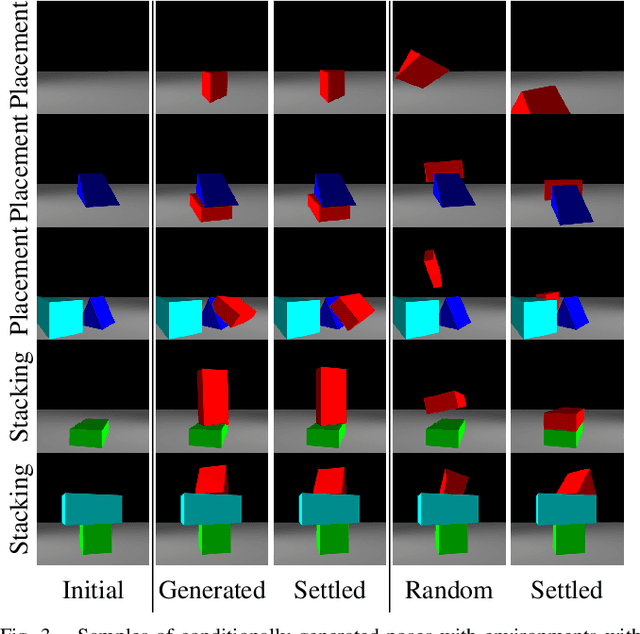

A core capability for robot manipulation is reasoning over where and how to stably place objects in cluttered environments. Traditionally, robots have relied on object-specific, hand-crafted heuristics in order to perform such reasoning, with limited generalizability beyond a small number of object instances and object interaction patterns. Recent approaches instead learn notions of physical interaction, namely motion prediction, but require supervision in the form of labeled object information or come at the cost of high sample complexity, and do not directly reason over stability or object placement. We present 6-DoFusion, a generative model capable of generating 3D poses of an object that produces a stable configuration of a given scene. Underlying 6-DoFusion is a diffusion model that incrementally refines a randomly initialized SE(3) pose to generate a sample from a learned, context-dependent distribution over stable poses. We evaluate our model on different object placement and stacking tasks, demonstrating its ability to construct stable scenes that involve novel object classes as well as to improve the accuracy of state-of-the-art 3D pose estimation methods.
Blending Imitation and Reinforcement Learning for Robust Policy Improvement
Oct 04, 2023
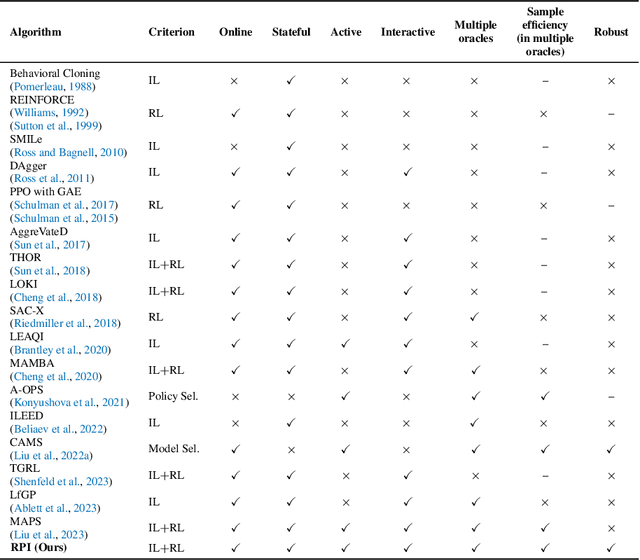
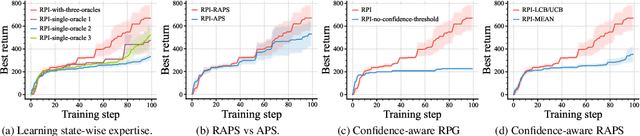
While reinforcement learning (RL) has shown promising performance, its sample complexity continues to be a substantial hurdle, restricting its broader application across a variety of domains. Imitation learning (IL) utilizes oracles to improve sample efficiency, yet it is often constrained by the quality of the oracles deployed. which actively interleaves between IL and RL based on an online estimate of their performance. RPI draws on the strengths of IL, using oracle queries to facilitate exploration, an aspect that is notably challenging in sparse-reward RL, particularly during the early stages of learning. As learning unfolds, RPI gradually transitions to RL, effectively treating the learned policy as an improved oracle. This algorithm is capable of learning from and improving upon a diverse set of black-box oracles. Integral to RPI are Robust Active Policy Selection (RAPS) and Robust Policy Gradient (RPG), both of which reason over whether to perform state-wise imitation from the oracles or learn from its own value function when the learner's performance surpasses that of the oracles in a specific state. Empirical evaluations and theoretical analysis validate that RPI excels in comparison to existing state-of-the-art methodologies, demonstrating superior performance across various benchmark domains.
Enhancing scientific exploration of the deep sea through shared autonomy in remote manipulation
Sep 15, 2023Shared autonomy enables novice remote users to conduct deep-ocean science operations with robotic manipulators.
Statler: State-Maintaining Language Models for Embodied Reasoning
Jul 03, 2023
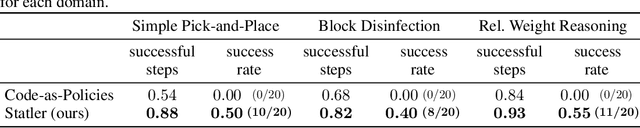
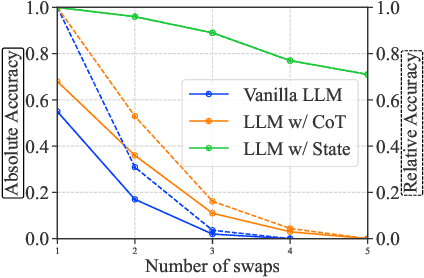
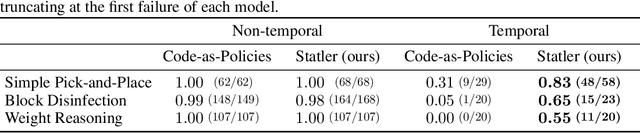
Large language models (LLMs) provide a promising tool that enable robots to perform complex robot reasoning tasks. However, the limited context window of contemporary LLMs makes reasoning over long time horizons difficult. Embodied tasks such as those that one might expect a household robot to perform typically require that the planner consider information acquired a long time ago (e.g., properties of the many objects that the robot previously encountered in the environment). Attempts to capture the world state using an LLM's implicit internal representation is complicated by the paucity of task- and environment-relevant information available in a robot's action history, while methods that rely on the ability to convey information via the prompt to the LLM are subject to its limited context window. In this paper, we propose Statler, a framework that endows LLMs with an explicit representation of the world state as a form of ``memory'' that is maintained over time. Integral to Statler is its use of two instances of general LLMs -- a world-model reader and a world-model writer -- that interface with and maintain the world state. By providing access to this world state ``memory'', Statler improves the ability of existing LLMs to reason over longer time horizons without the constraint of context length. We evaluate the effectiveness of our approach on three simulated table-top manipulation domains and a real robot domain, and show that it improves the state-of-the-art in LLM-based robot reasoning. Project website: https://statler-lm.github.io/
Active Policy Improvement from Multiple Black-box Oracles
Jun 17, 2023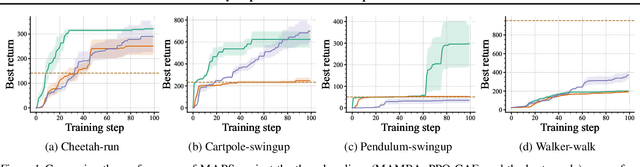



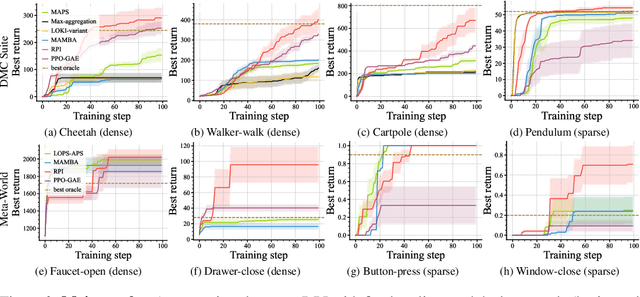
Reinforcement learning (RL) has made significant strides in various complex domains. However, identifying an effective policy via RL often necessitates extensive exploration. Imitation learning aims to mitigate this issue by using expert demonstrations to guide exploration. In real-world scenarios, one often has access to multiple suboptimal black-box experts, rather than a single optimal oracle. These experts do not universally outperform each other across all states, presenting a challenge in actively deciding which oracle to use and in which state. We introduce MAPS and MAPS-SE, a class of policy improvement algorithms that perform imitation learning from multiple suboptimal oracles. In particular, MAPS actively selects which of the oracles to imitate and improve their value function estimates, and MAPS-SE additionally leverages an active state exploration criterion to determine which states one should explore. We provide a comprehensive theoretical analysis and demonstrate that MAPS and MAPS-SE enjoy sample efficiency advantage over the state-of-the-art policy improvement algorithms. Empirical results show that MAPS-SE significantly accelerates policy optimization via state-wise imitation learning from multiple oracles across a broad spectrum of control tasks in the DeepMind Control Suite. Our code is publicly available at: https://github.com/ripl/maps.
NeRFuser: Large-Scale Scene Representation by NeRF Fusion
May 22, 2023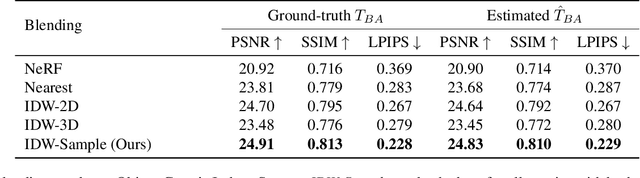

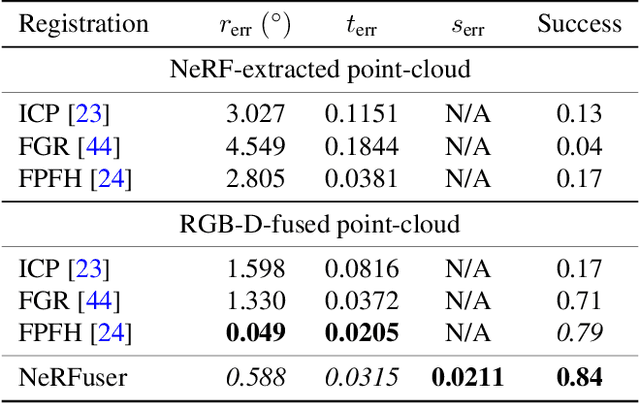
A practical benefit of implicit visual representations like Neural Radiance Fields (NeRFs) is their memory efficiency: large scenes can be efficiently stored and shared as small neural nets instead of collections of images. However, operating on these implicit visual data structures requires extending classical image-based vision techniques (e.g., registration, blending) from image sets to neural fields. Towards this goal, we propose NeRFuser, a novel architecture for NeRF registration and blending that assumes only access to pre-generated NeRFs, and not the potentially large sets of images used to generate them. We propose registration from re-rendering, a technique to infer the transformation between NeRFs based on images synthesized from individual NeRFs. For blending, we propose sample-based inverse distance weighting to blend visual information at the ray-sample level. We evaluate NeRFuser on public benchmarks and a self-collected object-centric indoor dataset, showing the robustness of our method, including to views that are challenging to render from the individual source NeRFs.
Eliciting User Preferences for Personalized Multi-Objective Decision Making through Comparative Feedback
Feb 07, 2023In classic reinforcement learning (RL) and decision making problems, policies are evaluated with respect to a scalar reward function, and all optimal policies are the same with regards to their expected return. However, many real-world problems involve balancing multiple, sometimes conflicting, objectives whose relative priority will vary according to the preferences of each user. Consequently, a policy that is optimal for one user might be sub-optimal for another. In this work, we propose a multi-objective decision making framework that accommodates different user preferences over objectives, where preferences are learned via policy comparisons. Our model consists of a Markov decision process with a vector-valued reward function, with each user having an unknown preference vector that expresses the relative importance of each objective. The goal is to efficiently compute a near-optimal policy for a given user. We consider two user feedback models. We first address the case where a user is provided with two policies and returns their preferred policy as feedback. We then move to a different user feedback model, where a user is instead provided with two small weighted sets of representative trajectories and selects the preferred one. In both cases, we suggest an algorithm that finds a nearly optimal policy for the user using a small number of comparison queries.
N-LIMB: Neural Limb Optimization for Efficient Morphological Design
Jul 24, 2022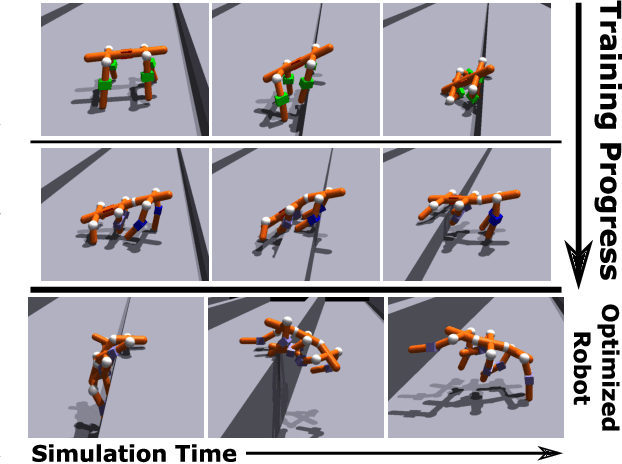
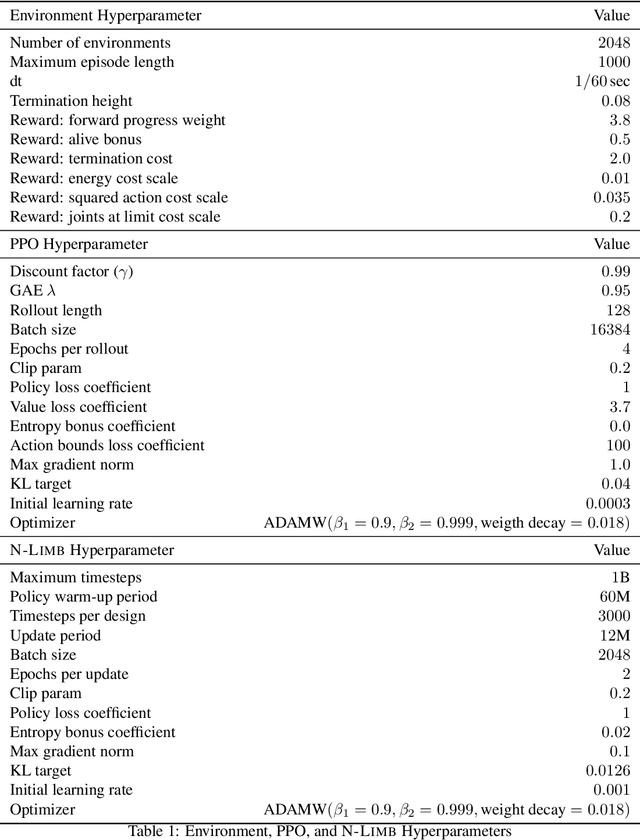
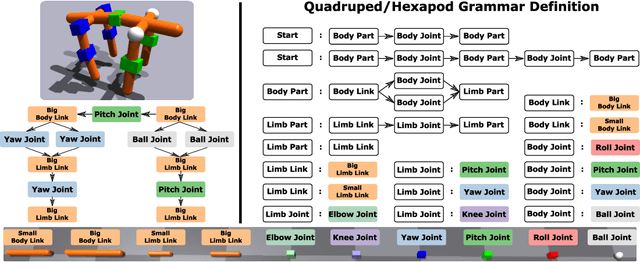
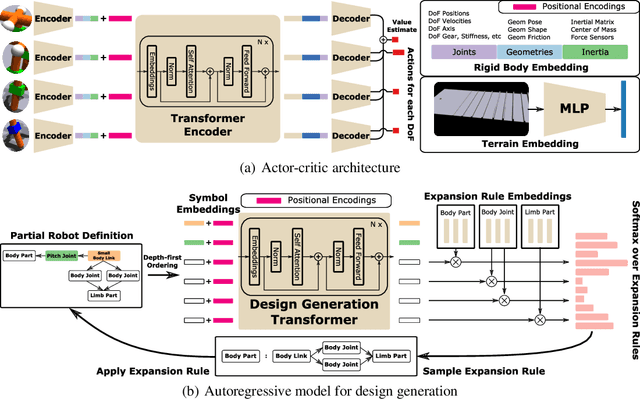
A robot's ability to complete a task is heavily dependent on its physical design. However, identifying an optimal physical design and its corresponding control policy is inherently challenging. The freedom to choose the number of links, their type, and how they are connected results in a combinatorial design space, and the evaluation of any design in that space requires deriving its optimal controller. In this work, we present N-LIMB, an efficient approach to optimizing the design and control of a robot over large sets of morphologies. Central to our framework is a universal, design-conditioned control policy capable of controlling a diverse sets of designs. This policy greatly improves the sample efficiency of our approach by allowing the transfer of experience across designs and reducing the cost to evaluate new designs. We train this policy to maximize expected return over a distribution of designs, which is simultaneously updated towards higher performing designs under the universal policy. In this way, our approach converges towards a design distribution peaked around high-performing designs and a controller that is effectively fine-tuned for those designs. We demonstrate the potential of our approach on a series of locomotion tasks across varying terrains and show the discovery novel and high-performing design-control pairs.
Soft Robots Learn to Crawl: Jointly Optimizing Design and Control with Sim-to-Real Transfer
Feb 09, 2022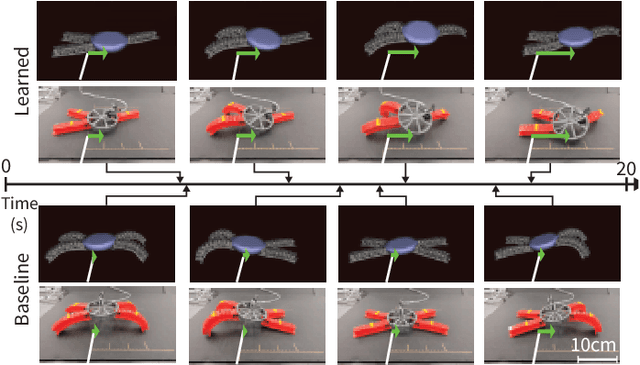
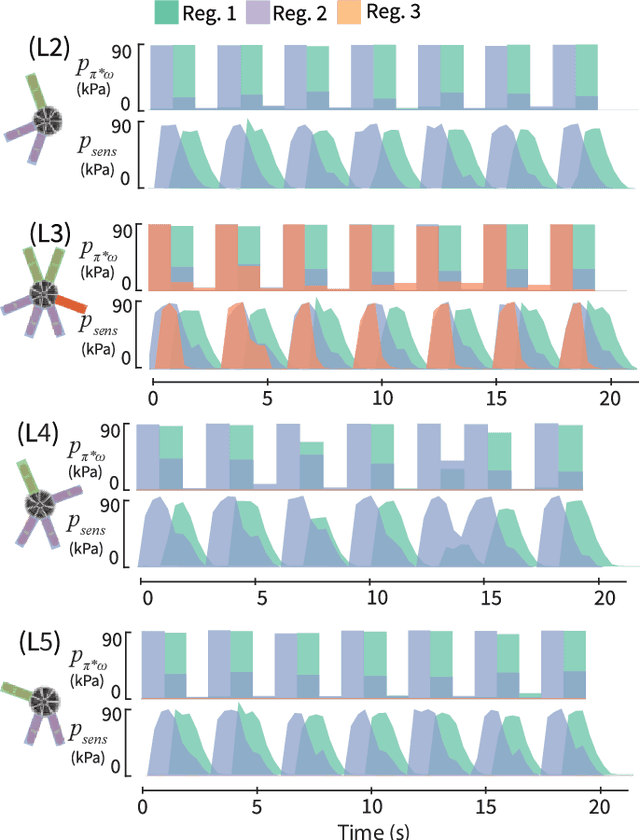
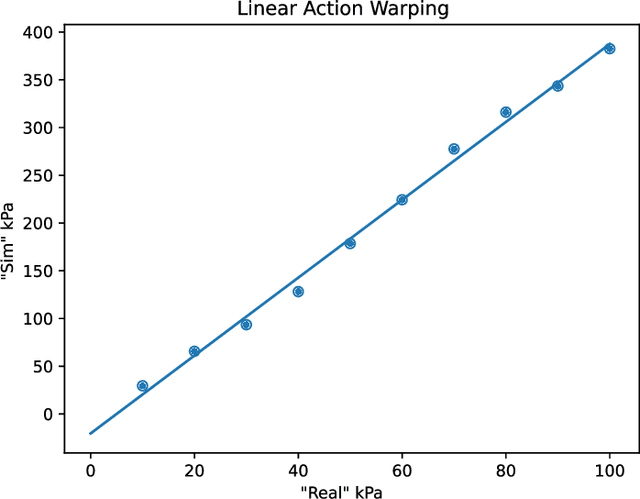
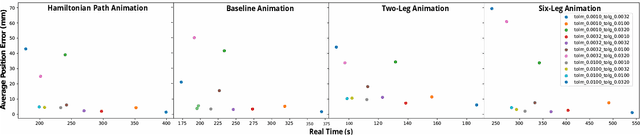
This work provides a complete framework for the simulation, co-optimization, and sim-to-real transfer of the design and control of soft legged robots. The compliance of soft robots provides a form of "mechanical intelligence" -- the ability to passively exhibit behaviors that would otherwise be difficult to program. Exploiting this capacity requires careful consideration of the coupling between mechanical design and control. Co-optimization provides a promising means to generate sophisticated soft robots by reasoning over this coupling. However, the complex nature of soft robot dynamics makes it difficult to provide a simulation environment that is both sufficiently accurate to allow for sim-to-real transfer, while also being fast enough for contemporary co-optimization algorithms. In this work, we show that finite element simulation combined with recent model order reduction techniques provide both the efficiency and the accuracy required to successfully learn effective soft robot design-control pairs that transfer to reality. We propose a reinforcement learning-based framework for co-optimization and demonstrate successful optimization, construction, and zero-shot sim-to-real transfer of several soft crawling robots. Our learned robot outperforms an expert-designed crawling robot, showing that our approach can generate novel, high-performing designs even in well-understood domains.