 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAditya Grover
Prepacking: A Simple Method for Fast Prefilling and Increased Throughput in Large Language Models
Apr 15, 2024
During inference for transformer-based large language models (LLM), prefilling is the computation of the key-value (KV) cache for input tokens in the prompt prior to autoregressive generation. For longer input prompt lengths, prefilling will incur a significant overhead on decoding time. In this work, we highlight the following pitfall of prefilling: for batches containing high-varying prompt lengths, significant computation is wasted by the standard practice of padding sequences to the maximum length. As LLMs increasingly support longer context lengths, potentially up to 10 million tokens, variations in prompt lengths within a batch become more pronounced. To address this, we propose Prepacking, a simple yet effective method to optimize prefilling computation. To avoid redundant computation on pad tokens, prepacking combines prompts of varying lengths into a sequence and packs multiple sequences into a compact batch using a bin-packing algorithm. It then modifies the attention mask and positional encoding to compute multiple prefilled KV-caches for multiple prompts within a single sequence. On standard curated dataset containing prompts with varying lengths, we obtain a significant speed and memory efficiency improvements as compared to the default padding-based prefilling computation within Huggingface across a range of base model configurations and inference serving scenarios.
Comparing Bad Apples to Good Oranges: Aligning Large Language Models via Joint Preference Optimization
Mar 31, 2024A common technique for aligning large language models (LLMs) relies on acquiring human preferences by comparing multiple generations conditioned on a fixed context. This only leverages the pairwise comparisons when the generations are placed in an identical context. However, such conditional rankings often fail to capture the complex and multidimensional aspects of human preferences. In this work, we revisit the traditional paradigm of preference acquisition and propose a new axis that is based on eliciting preferences jointly over the instruction-response pairs. While prior preference optimizations are designed for conditional ranking protocols (e.g., DPO), our proposed preference acquisition protocol introduces DOVE, a new preference optimization objective that upweights the joint probability of the chosen instruction-response pair over the rejected instruction-response pair. Interestingly, we find that the LLM trained with joint instruction-response preference data using DOVE outperforms the LLM trained with DPO by 5.2% and 3.3% win-rate for the summarization and open-ended dialogue datasets, respectively. Our findings reveal that joint preferences over instruction and response pairs can significantly enhance the alignment of LLMs by tapping into a broader spectrum of human preference elicitation. The data and code is available at https://github.com/Hritikbansal/dove.
Scaling Vision-and-Language Navigation With Offline RL
Mar 27, 2024
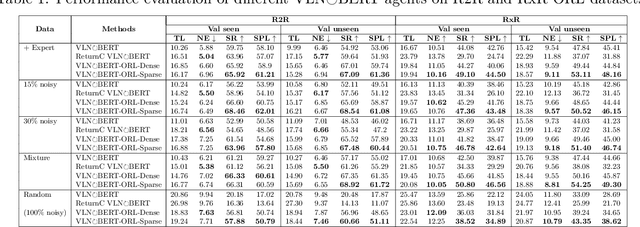
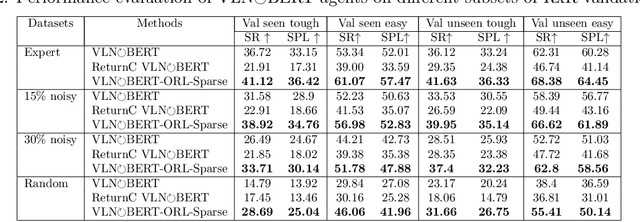
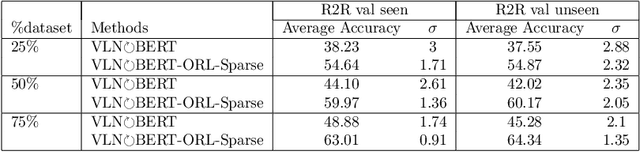
The study of vision-and-language navigation (VLN) has typically relied on expert trajectories, which may not always be available in real-world situations due to the significant effort required to collect them. On the other hand, existing approaches to training VLN agents that go beyond available expert data involve data augmentations or online exploration which can be tedious and risky. In contrast, it is easy to access large repositories of suboptimal offline trajectories. Inspired by research in offline reinforcement learning (ORL), we introduce a new problem setup of VLN-ORL which studies VLN using suboptimal demonstration data. We introduce a simple and effective reward-conditioned approach that can account for dataset suboptimality for training VLN agents, as well as benchmarks to evaluate progress and promote research in this area. We empirically study various noise models for characterizing dataset suboptimality among other unique challenges in VLN-ORL and instantiate it for the VLN$\circlearrowright$BERT and MTVM architectures in the R2R and RxR environments. Our experiments demonstrate that the proposed reward-conditioned approach leads to significant performance improvements, even in complex and intricate environments.
Mamba-ND: Selective State Space Modeling for Multi-Dimensional Data
Feb 08, 2024In recent years, Transformers have become the de-facto architecture for sequence modeling on text and a variety of multi-dimensional data, such as images and video. However, the use of self-attention layers in a Transformer incurs prohibitive compute and memory complexity that scales quadratically w.r.t. the sequence length. A recent architecture, Mamba, based on state space models has been shown to achieve comparable performance for modeling text sequences, while scaling linearly with the sequence length. In this work, we present Mamba-ND, a generalized design extending the Mamba architecture to arbitrary multi-dimensional data. Our design alternatively unravels the input data across different dimensions following row-major orderings. We provide a systematic comparison of Mamba-ND with several other alternatives, based on prior multi-dimensional extensions such as Bi-directional LSTMs and S4ND. Empirically, we show that Mamba-ND demonstrates performance competitive with the state-of-the-art on a variety of multi-dimensional benchmarks, including ImageNet-1K classification, HMDB-51 action recognition, and ERA5 weather forecasting.
ChaosBench: A Multi-Channel, Physics-Based Benchmark for Subseasonal-to-Seasonal Climate Prediction
Feb 01, 2024Accurate prediction of climate in the subseasonal-to-seasonal scale is crucial for disaster readiness, reduced economic risk, and improved policy-making amidst climate change. Yet, S2S prediction remains challenging due to the chaotic nature of the system. At present, existing benchmarks for weather and climate applications, tend to (1) have shorter forecasting range of up-to 14 days, (2) do not include a wide range of operational baseline forecasts, and (3) lack physics-based constraints for explainability. Thus, we propose ChaosBench, a large-scale, multi-channel, physics-based benchmark for S2S prediction. ChaosBench has over 460K frames of real-world observations and simulations, each with 60 variable-channels and spanning for up-to 45 years. We also propose several physics-based, in addition to vision-based metrics, that enables for a more physically-consistent model. Furthermore, we include a diverse set of physics-based forecasts from 4 national weather agencies as baselines to our data-driven counterpart. We establish two tasks that vary in complexity: full and sparse dynamics prediction. Our benchmark is one of the first to perform large-scale evaluation on existing models including PanguWeather, FourCastNetV2, GraphCast, and ClimaX, and finds methods originally developed for weather-scale applications fails on S2S task. We release our benchmark code and datasets at https://leap-stc.github.io/ChaosBench.
InstructAny2Pix: Flexible Visual Editing via Multimodal Instruction Following
Dec 30, 2023The ability to provide fine-grained control for generating and editing visual imagery has profound implications for computer vision and its applications. Previous works have explored extending controllability in two directions: instruction tuning with text-based prompts and multi-modal conditioning. However, these works make one or more unnatural assumptions on the number and/or type of modality inputs used to express controllability. We propose InstructAny2Pix, a flexible multi-modal instruction-following system that enables users to edit an input image using instructions involving audio, images, and text. InstructAny2Pix consists of three building blocks that facilitate this capability: a multi-modal encoder that encodes different modalities such as images and audio into a unified latent space, a diffusion model that learns to decode representations in this latent space into images, and a multi-modal LLM that can understand instructions involving multiple images and audio pieces and generate a conditional embedding of the desired output, which can be used by the diffusion decoder. Additionally, to facilitate training efficiency and improve generation quality, we include an additional refinement prior module that enhances the visual quality of LLM outputs. These designs are critical to the performance of our system. We demonstrate that our system can perform a series of novel instruction-guided editing tasks. The code is available at https://github.com/jacklishufan/InstructAny2Pix.git
Guided Flows for Generative Modeling and Decision Making
Dec 07, 2023Classifier-free guidance is a key component for enhancing the performance of conditional generative models across diverse tasks. While it has previously demonstrated remarkable improvements for the sample quality, it has only been exclusively employed for diffusion models. In this paper, we integrate classifier-free guidance into Flow Matching (FM) models, an alternative simulation-free approach that trains Continuous Normalizing Flows (CNFs) based on regressing vector fields. We explore the usage of \emph{Guided Flows} for a variety of downstream applications. We show that Guided Flows significantly improves the sample quality in conditional image generation and zero-shot text-to-speech synthesis, boasting state-of-the-art performance. Notably, we are the first to apply flow models for plan generation in the offline reinforcement learning setting, showcasing a 10x speedup in computation compared to diffusion models while maintaining comparable performance.
Scaling transformer neural networks for skillful and reliable medium-range weather forecasting
Dec 06, 2023Weather forecasting is a fundamental problem for anticipating and mitigating the impacts of climate change. Recently, data-driven approaches for weather forecasting based on deep learning have shown great promise, achieving accuracies that are competitive with operational systems. However, those methods often employ complex, customized architectures without sufficient ablation analysis, making it difficult to understand what truly contributes to their success. Here we introduce Stormer, a simple transformer model that achieves state-of-the-art performance on weather forecasting with minimal changes to the standard transformer backbone. We identify the key components of Stormer through careful empirical analyses, including weather-specific embedding, randomized dynamics forecast, and pressure-weighted loss. At the core of Stormer is a randomized forecasting objective that trains the model to forecast the weather dynamics over varying time intervals. During inference, this allows us to produce multiple forecasts for a target lead time and combine them to obtain better forecast accuracy. On WeatherBench 2, Stormer performs competitively at short to medium-range forecasts and outperforms current methods beyond 7 days, while requiring orders-of-magnitude less training data and compute. Additionally, we demonstrate Stormer's favorable scaling properties, showing consistent improvements in forecast accuracy with increases in model size and training tokens. Code and checkpoints will be made publicly available.
VideoCon: Robust Video-Language Alignment via Contrast Captions
Nov 15, 2023Despite being (pre)trained on a massive amount of data, state-of-the-art video-language alignment models are not robust to semantically-plausible contrastive changes in the video captions. Our work addresses this by identifying a broad spectrum of contrast misalignments, such as replacing entities, actions, and flipping event order, which alignment models should be robust against. To this end, we introduce the VideoCon, a video-language alignment dataset constructed by a large language model that generates plausible contrast video captions and explanations for differences between original and contrast video captions. Then, a generative video-language model is finetuned with VideoCon to assess video-language entailment and generate explanations. Our VideoCon-based alignment model significantly outperforms current models. It exhibits a 12-point increase in AUC for the video-language alignment task on human-generated contrast captions. Finally, our model sets new state of the art zero-shot performance in temporally-extensive video-language tasks such as text-to-video retrieval (SSv2-Temporal) and video question answering (ATP-Hard). Moreover, our model shows superior performance on novel videos and human-crafted captions and explanations. Our code and data are available at https://github.com/Hritikbansal/videocon.
ExPT: Synthetic Pretraining for Few-Shot Experimental Design
Oct 30, 2023Experimental design is a fundamental problem in many science and engineering fields. In this problem, sample efficiency is crucial due to the time, money, and safety costs of real-world design evaluations. Existing approaches either rely on active data collection or access to large, labeled datasets of past experiments, making them impractical in many real-world scenarios. In this work, we address the more challenging yet realistic setting of few-shot experimental design, where only a few labeled data points of input designs and their corresponding values are available. We approach this problem as a conditional generation task, where a model conditions on a few labeled examples and the desired output to generate an optimal input design. To this end, we introduce Experiment Pretrained Transformers (ExPT), a foundation model for few-shot experimental design that employs a novel combination of synthetic pretraining with in-context learning. In ExPT, we only assume knowledge of a finite collection of unlabelled data points from the input domain and pretrain a transformer neural network to optimize diverse synthetic functions defined over this domain. Unsupervised pretraining allows ExPT to adapt to any design task at test time in an in-context fashion by conditioning on a few labeled data points from the target task and generating the candidate optima. We evaluate ExPT on few-shot experimental design in challenging domains and demonstrate its superior generality and performance compared to existing methods. The source code is available at https://github.com/tung-nd/ExPT.git.