 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJonas Gehring
The Larger the Better? Improved LLM Code-Generation via Budget Reallocation
Mar 31, 2024
It is a common belief that large language models (LLMs) are better than smaller-sized ones. However, larger models also require significantly more time and compute during inference. This begs the question: what happens when both models operate under the same budget? (e.g., compute, run-time). To address this question, we analyze code generation LLMs of various sizes and make comparisons such as running a 70B model once vs. generating five outputs from a 13B model and selecting one. Our findings reveal that, in a standard unit-test setup, the repeated use of smaller models can yield consistent improvements, with gains of up to 15% across five tasks. On the other hand, in scenarios where unit-tests are unavailable, a ranking-based selection of candidates from the smaller model falls short of the performance of a single output from larger ones. Our results highlight the potential of using smaller models instead of larger ones, and the importance of studying approaches for ranking LLM outputs.
Large Language Models for Compiler Optimization
Sep 11, 2023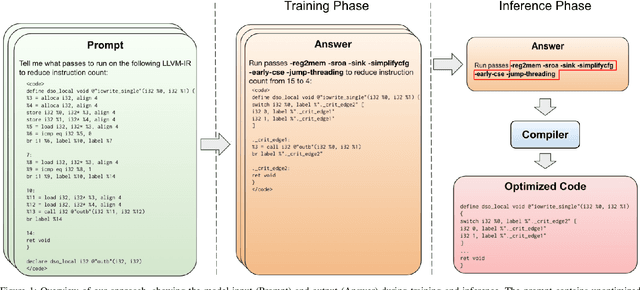
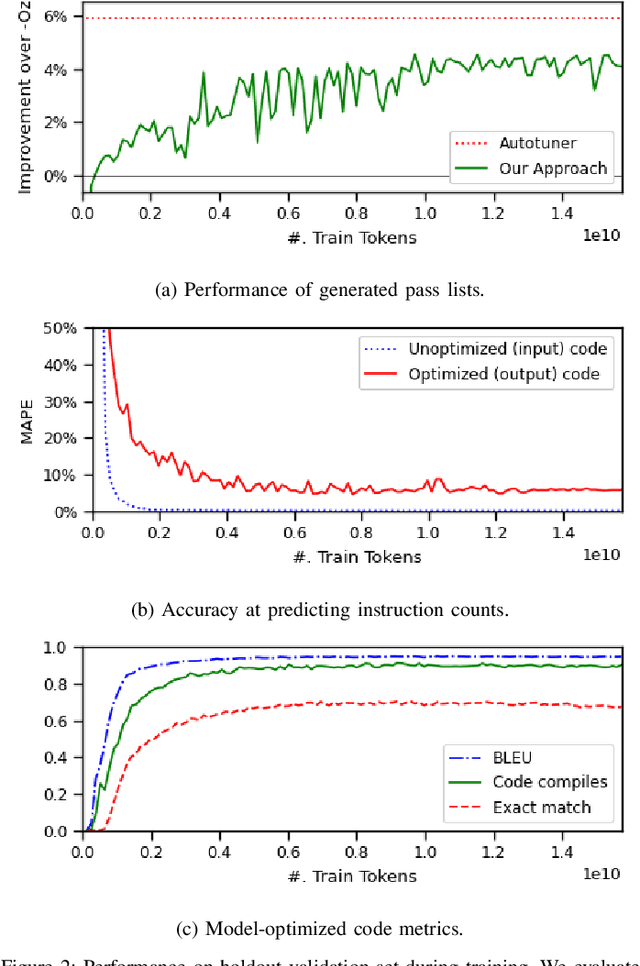
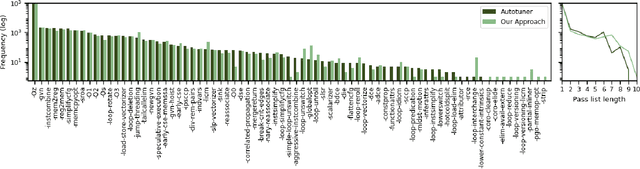
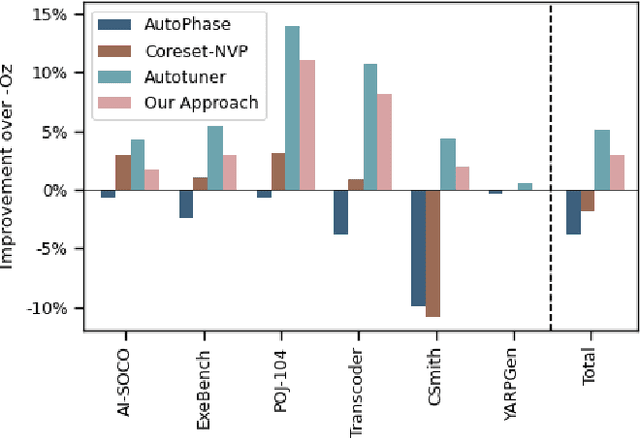
We explore the novel application of Large Language Models to code optimization. We present a 7B-parameter transformer model trained from scratch to optimize LLVM assembly for code size. The model takes as input unoptimized assembly and outputs a list of compiler options to best optimize the program. Crucially, during training, we ask the model to predict the instruction counts before and after optimization, and the optimized code itself. These auxiliary learning tasks significantly improve the optimization performance of the model and improve the model's depth of understanding. We evaluate on a large suite of test programs. Our approach achieves a 3.0% improvement in reducing instruction counts over the compiler, outperforming two state-of-the-art baselines that require thousands of compilations. Furthermore, the model shows surprisingly strong code reasoning abilities, generating compilable code 91% of the time and perfectly emulating the output of the compiler 70% of the time.
Code Llama: Open Foundation Models for Code
Aug 25, 2023
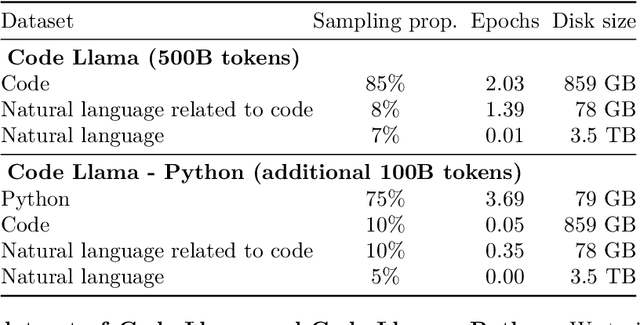
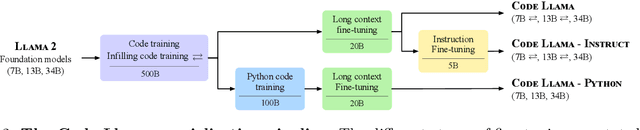
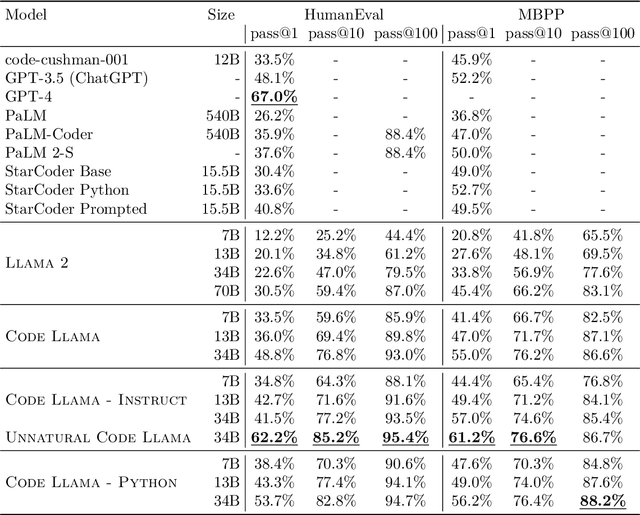
We release Code Llama, a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models, infilling capabilities, support for large input contexts, and zero-shot instruction following ability for programming tasks. We provide multiple flavors to cover a wide range of applications: foundation models (Code Llama), Python specializations (Code Llama - Python), and instruction-following models (Code Llama - Instruct) with 7B, 13B and 34B parameters each. All models are trained on sequences of 16k tokens and show improvements on inputs with up to 100k tokens. 7B and 13B Code Llama and Code Llama - Instruct variants support infilling based on surrounding content. Code Llama reaches state-of-the-art performance among open models on several code benchmarks, with scores of up to 53% and 55% on HumanEval and MBPP, respectively. Notably, Code Llama - Python 7B outperforms Llama 2 70B on HumanEval and MBPP, and all our models outperform every other publicly available model on MultiPL-E. We release Code Llama under a permissive license that allows for both research and commercial use.
Leveraging Demonstrations with Latent Space Priors
Oct 26, 2022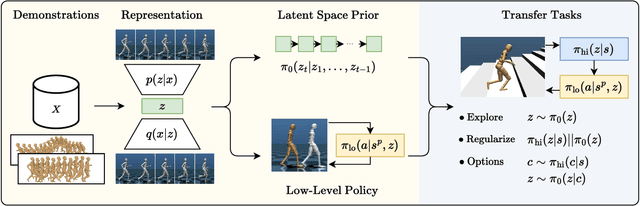


Demonstrations provide insight into relevant state or action space regions, bearing great potential to boost the efficiency and practicality of reinforcement learning agents. In this work, we propose to leverage demonstration datasets by combining skill learning and sequence modeling. Starting with a learned joint latent space, we separately train a generative model of demonstration sequences and an accompanying low-level policy. The sequence model forms a latent space prior over plausible demonstration behaviors to accelerate learning of high-level policies. We show how to acquire such priors from state-only motion capture demonstrations and explore several methods for integrating them into policy learning on transfer tasks. Our experimental results confirm that latent space priors provide significant gains in learning speed and final performance in a set of challenging sparse-reward environments with a complex, simulated humanoid. Videos, source code and pre-trained models are available at the corresponding project website at https://facebookresearch.github.io/latent-space-priors .
Hierarchical Skills for Efficient Exploration
Oct 20, 2021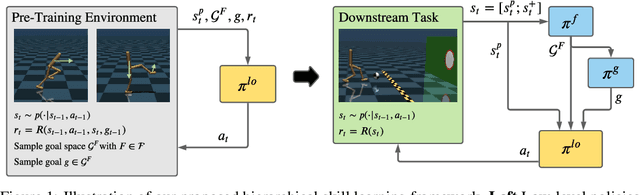
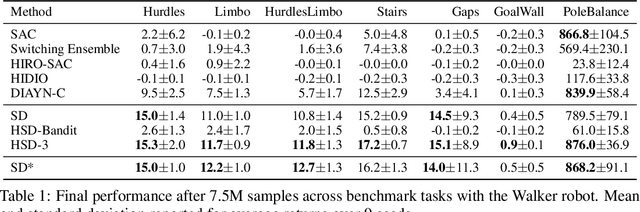


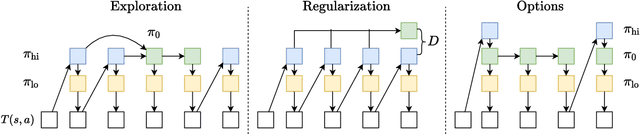
In reinforcement learning, pre-trained low-level skills have the potential to greatly facilitate exploration. However, prior knowledge of the downstream task is required to strike the right balance between generality (fine-grained control) and specificity (faster learning) in skill design. In previous work on continuous control, the sensitivity of methods to this trade-off has not been addressed explicitly, as locomotion provides a suitable prior for navigation tasks, which have been of foremost interest. In this work, we analyze this trade-off for low-level policy pre-training with a new benchmark suite of diverse, sparse-reward tasks for bipedal robots. We alleviate the need for prior knowledge by proposing a hierarchical skill learning framework that acquires skills of varying complexity in an unsupervised manner. For utilization on downstream tasks, we present a three-layered hierarchical learning algorithm to automatically trade off between general and specific skills as required by the respective task. In our experiments, we show that our approach performs this trade-off effectively and achieves better results than current state-of-the-art methods for end- to-end hierarchical reinforcement learning and unsupervised skill discovery. Code and videos are available at https://facebookresearch.github.io/hsd3 .
Forward Modeling for Partial Observation Strategy Games - A StarCraft Defogger
Nov 30, 2018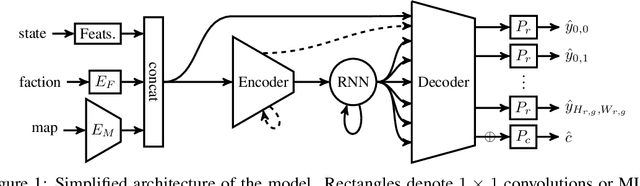
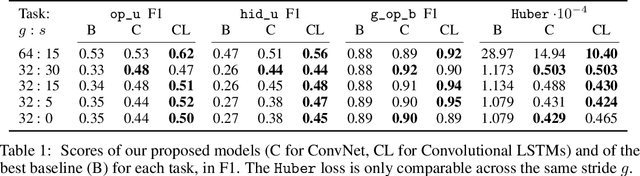
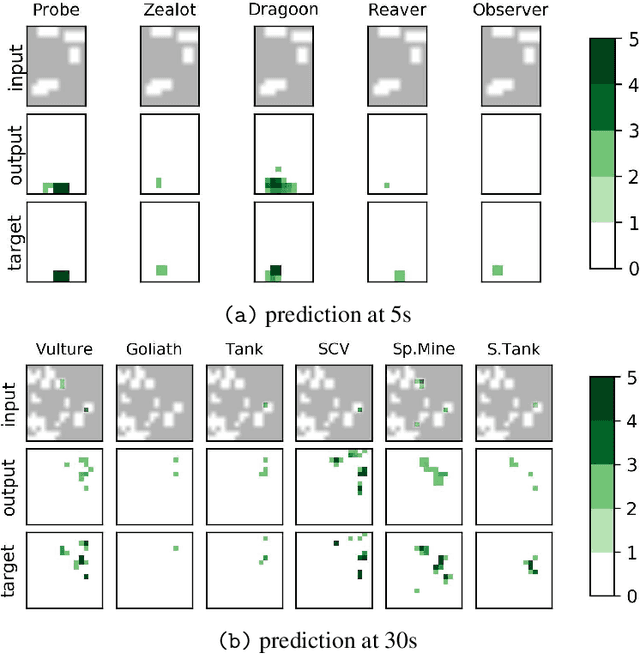
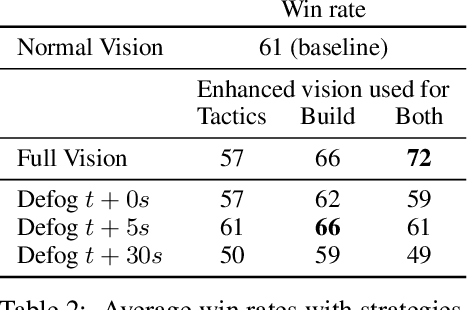
We formulate the problem of defogging as state estimation and future state prediction from previous, partial observations in the context of real-time strategy games. We propose to employ encoder-decoder neural networks for this task, and introduce proxy tasks and baselines for evaluation to assess their ability of capturing basic game rules and high-level dynamics. By combining convolutional neural networks and recurrent networks, we exploit spatial and sequential correlations and train well-performing models on a large dataset of human games of StarCraft: Brood War. Finally, we demonstrate the relevance of our models to downstream tasks by applying them for enemy unit prediction in a state-of-the-art, rule-based StarCraft bot. We observe improvements in win rates against several strong community bots.
High-Level Strategy Selection under Partial Observability in StarCraft: Brood War
Nov 21, 2018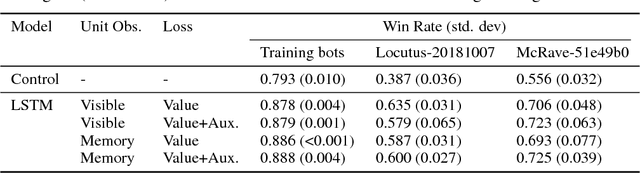
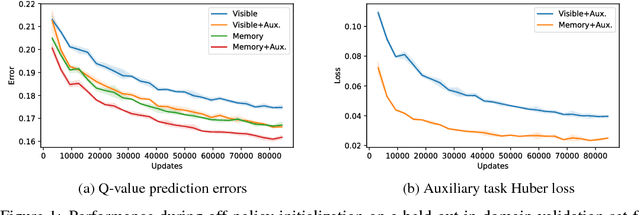
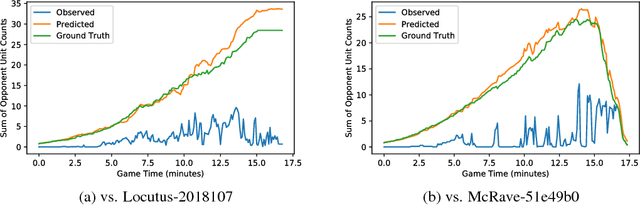
We consider the problem of high-level strategy selection in the adversarial setting of real-time strategy games from a reinforcement learning perspective, where taking an action corresponds to switching to the respective strategy. Here, a good strategy successfully counters the opponent's current and possible future strategies which can only be estimated using partial observations. We investigate whether we can utilize the full game state information during training time (in the form of an auxiliary prediction task) to increase performance. Experiments carried out within a StarCraft: Brood War bot against strong community bots show substantial win rate improvements over a fixed-strategy baseline and encouraging results when learning with the auxiliary task.
STARDATA: A StarCraft AI Research Dataset
Aug 07, 2017
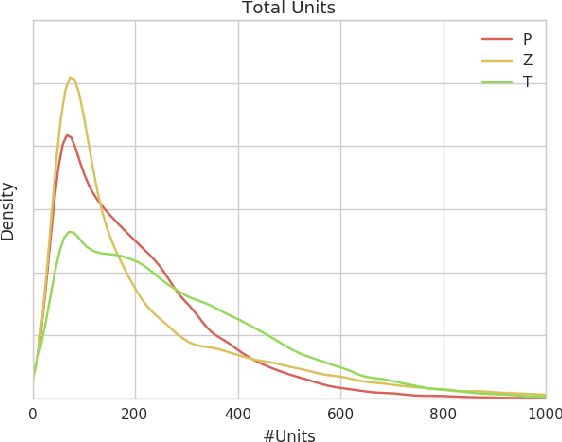

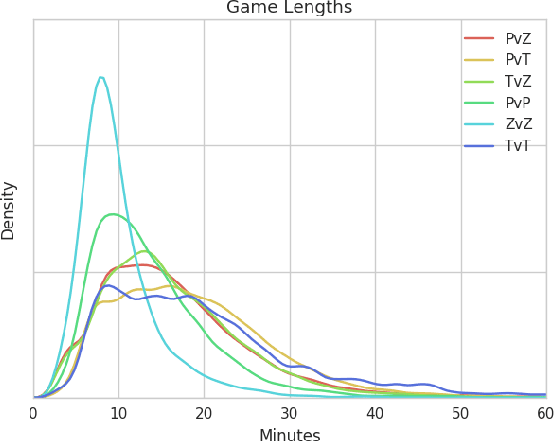
We release a dataset of 65646 StarCraft replays that contains 1535 million frames and 496 million player actions. We provide full game state data along with the original replays that can be viewed in StarCraft. The game state data was recorded every 3 frames which ensures suitability for a wide variety of machine learning tasks such as strategy classification, inverse reinforcement learning, imitation learning, forward modeling, partial information extraction, and others. We use TorchCraft to extract and store the data, which standardizes the data format for both reading from replays and reading directly from the game. Furthermore, the data can be used on different operating systems and platforms. The dataset contains valid, non-corrupted replays only and its quality and diversity was ensured by a number of heuristics. We illustrate the diversity of the data with various statistics and provide examples of tasks that benefit from the dataset. We make the dataset available at https://github.com/TorchCraft/StarData . En Taro Adun!
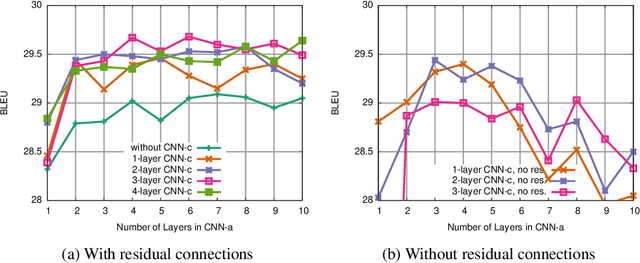
Convolutional Sequence to Sequence Learning
Jul 25, 2017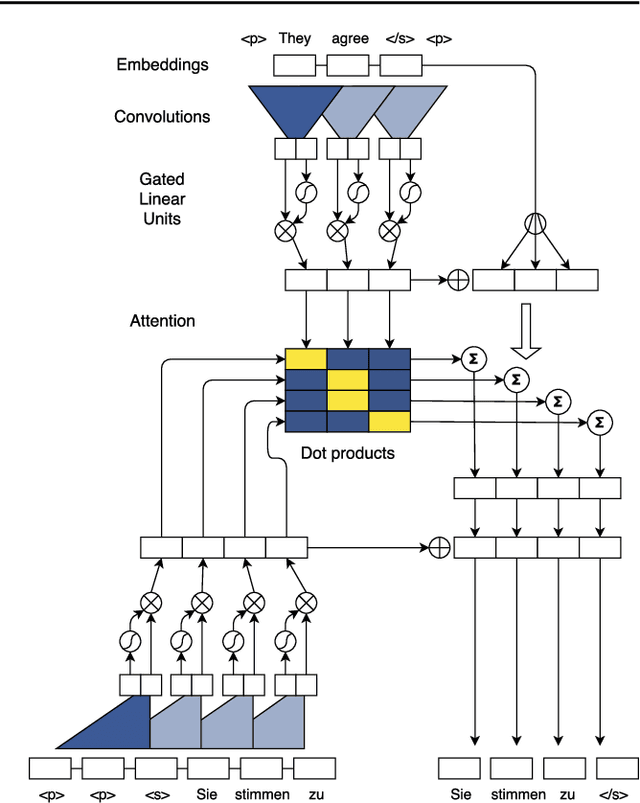
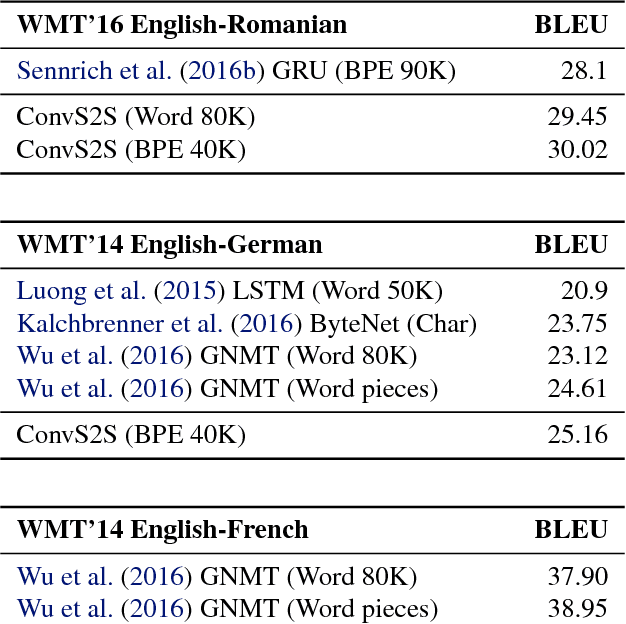
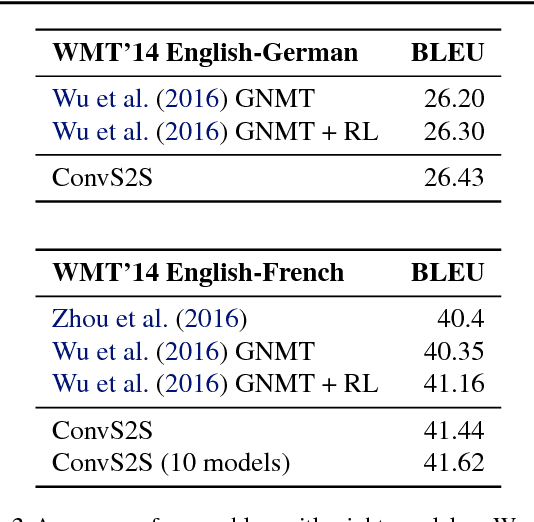
The prevalent approach to sequence to sequence learning maps an input sequence to a variable length output sequence via recurrent neural networks. We introduce an architecture based entirely on convolutional neural networks. Compared to recurrent models, computations over all elements can be fully parallelized during training and optimization is easier since the number of non-linearities is fixed and independent of the input length. Our use of gated linear units eases gradient propagation and we equip each decoder layer with a separate attention module. We outperform the accuracy of the deep LSTM setup of Wu et al. (2016) on both WMT'14 English-German and WMT'14 English-French translation at an order of magnitude faster speed, both on GPU and CPU.
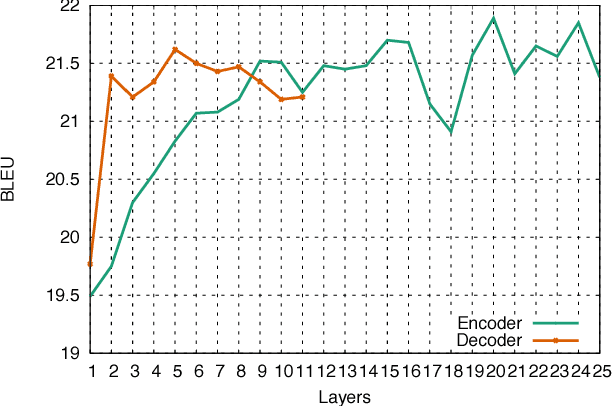
A Convolutional Encoder Model for Neural Machine Translation
Jul 25, 2017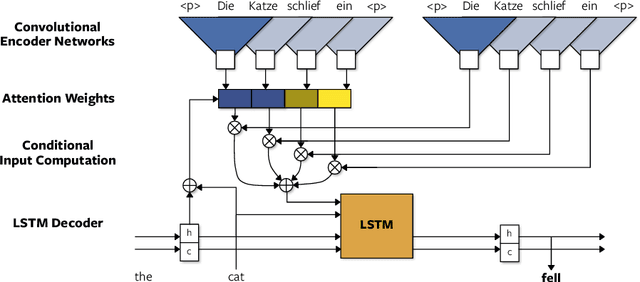

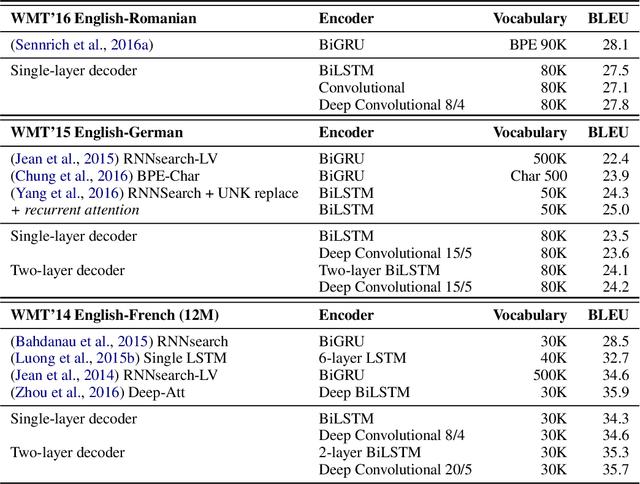
The prevalent approach to neural machine translation relies on bi-directional LSTMs to encode the source sentence. In this paper we present a faster and simpler architecture based on a succession of convolutional layers. This allows to encode the entire source sentence simultaneously compared to recurrent networks for which computation is constrained by temporal dependencies. On WMT'16 English-Romanian translation we achieve competitive accuracy to the state-of-the-art and we outperform several recently published results on the WMT'15 English-German task. Our models obtain almost the same accuracy as a very deep LSTM setup on WMT'14 English-French translation. Our convolutional encoder speeds up CPU decoding by more than two times at the same or higher accuracy as a strong bi-directional LSTM baseline.