 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSten Sootla
Code Llama: Open Foundation Models for Code
Aug 25, 2023

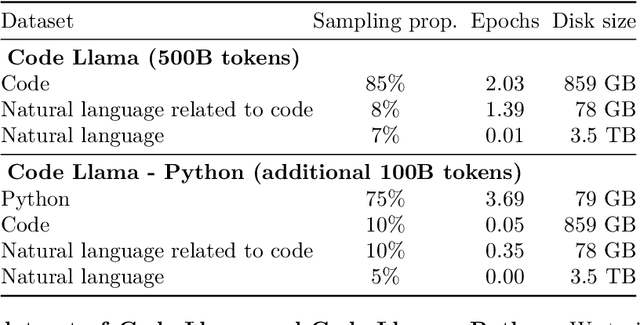
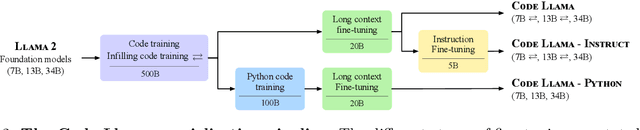
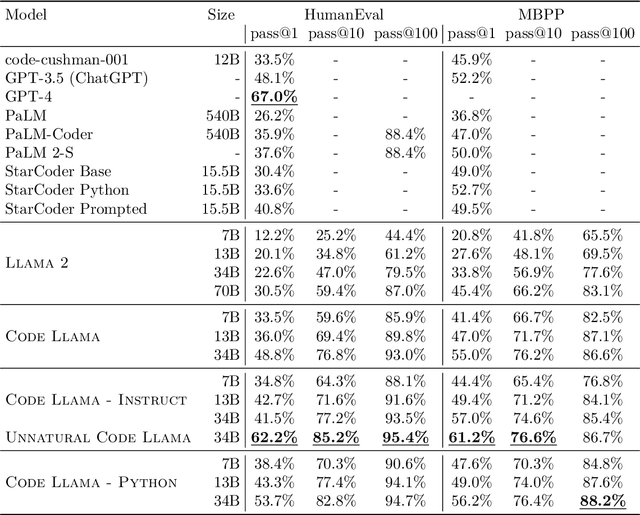
We release Code Llama, a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models, infilling capabilities, support for large input contexts, and zero-shot instruction following ability for programming tasks. We provide multiple flavors to cover a wide range of applications: foundation models (Code Llama), Python specializations (Code Llama - Python), and instruction-following models (Code Llama - Instruct) with 7B, 13B and 34B parameters each. All models are trained on sequences of 16k tokens and show improvements on inputs with up to 100k tokens. 7B and 13B Code Llama and Code Llama - Instruct variants support infilling based on surrounding content. Code Llama reaches state-of-the-art performance among open models on several code benchmarks, with scores of up to 53% and 55% on HumanEval and MBPP, respectively. Notably, Code Llama - Python 7B outperforms Llama 2 70B on HumanEval and MBPP, and all our models outperform every other publicly available model on MultiPL-E. We release Code Llama under a permissive license that allows for both research and commercial use.
PLCMOS -- a data-driven non-intrusive metric for the evaluation of packet loss concealment algorithms
May 24, 2023



Speech quality assessment is a problem for every researcher working on models that produce or process speech. Human subjective ratings, the gold standard in speech quality assessment, are expensive and time-consuming to acquire in a quantity that is sufficient to get reliable data, while automated objective metrics show a low correlation with gold standard ratings. This paper presents PLCMOS, a non-intrusive data-driven tool for generating a robust, accurate estimate of the mean opinion score a human rater would assign an audio file that has been processed by being transmitted over a degraded packet-switched network with missing packets being healed by a packet loss concealment algorithm. Our new model shows a model-wise Pearson's correlation of ~0.97 and rank correlation of ~0.95 with human ratings, substantially above all other available intrusive and non-intrusive metrics. The model is released as an ONNX model for other researchers to use when building PLC systems.
INTERSPEECH 2022 Audio Deep Packet Loss Concealment Challenge
Apr 11, 2022


Audio Packet Loss Concealment (PLC) is the hiding of gaps in audio streams caused by data transmission failures in packet switched networks. This is a common problem, and of increasing importance as end-to-end VoIP telephony and teleconference systems become the default and ever more widely used form of communication in business as well as in personal usage. This paper presents the INTERSPEECH 2022 Audio Deep Packet Loss Concealment challenge. We first give an overview of the PLC problem, and introduce some classical approaches to PLC as well as recent work. We then present the open source dataset released as part of this challenge as well as the evaluation methods and metrics used to determine the winner. We also briefly introduce PLCMOS, a novel data-driven metric that can be used to quickly evaluate the performance PLC systems. Finally, we present the results of the INTERSPEECH 2022 Audio Deep PLC Challenge, and provide a summary of important takeaways.
AECMOS: A speech quality assessment metric for echo impairment
Oct 08, 2021



Traditionally, the quality of acoustic echo cancellers is evaluated using intrusive speech quality assessment measures such as ERLE \cite{g168} and PESQ \cite{p862}, or by carrying out subjective laboratory tests. Unfortunately, the former are not well correlated with human subjective measures, while the latter are time and resource consuming to carry out. We provide a new tool for speech quality assessment for echo impairment which can be used to evaluate the performance of acoustic echo cancellers. More precisely, we develop a neural network model to evaluate call quality degradations in two separate categories: echo and degradations from other sources. We show that our model is accurate as measured by correlation with human subjective quality ratings. Our tool can be used effectively to stack rank echo cancellation models. AECMOS is being made publicly available as an Azure service.