 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNicolas Usunier
Code Llama: Open Foundation Models for Code
Aug 25, 2023

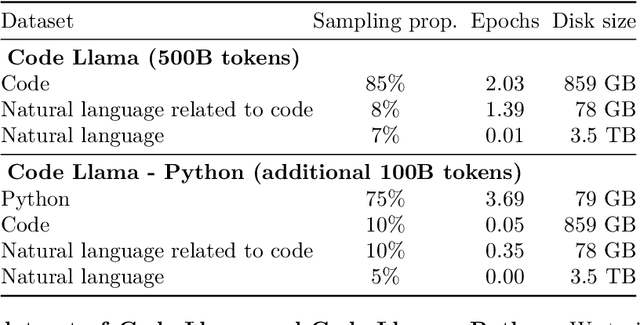
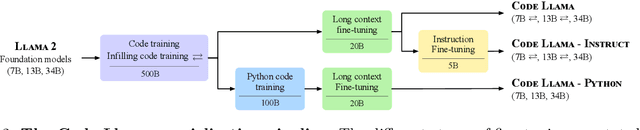
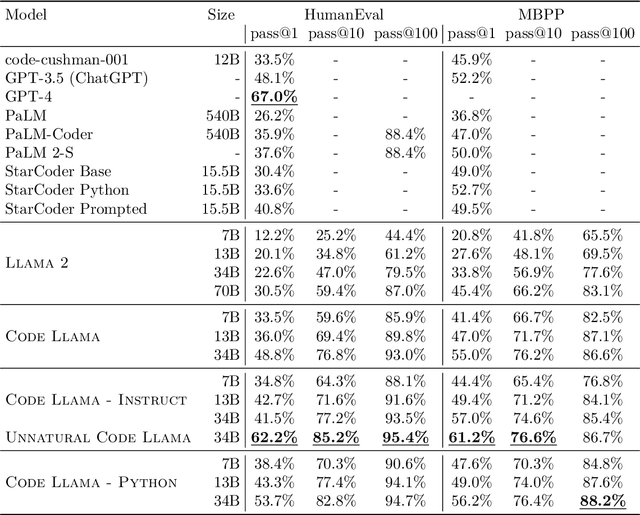
We release Code Llama, a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models, infilling capabilities, support for large input contexts, and zero-shot instruction following ability for programming tasks. We provide multiple flavors to cover a wide range of applications: foundation models (Code Llama), Python specializations (Code Llama - Python), and instruction-following models (Code Llama - Instruct) with 7B, 13B and 34B parameters each. All models are trained on sequences of 16k tokens and show improvements on inputs with up to 100k tokens. 7B and 13B Code Llama and Code Llama - Instruct variants support infilling based on surrounding content. Code Llama reaches state-of-the-art performance among open models on several code benchmarks, with scores of up to 53% and 55% on HumanEval and MBPP, respectively. Notably, Code Llama - Python 7B outperforms Llama 2 70B on HumanEval and MBPP, and all our models outperform every other publicly available model on MultiPL-E. We release Code Llama under a permissive license that allows for both research and commercial use.
Towards Reliable Assessments of Demographic Disparities in Multi-Label Image Classifiers
Feb 16, 2023

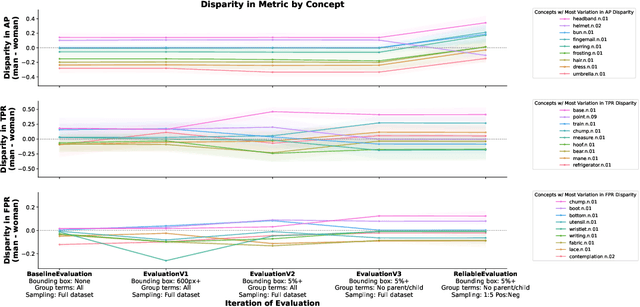

Disaggregated performance metrics across demographic groups are a hallmark of fairness assessments in computer vision. These metrics successfully incentivized performance improvements on person-centric tasks such as face analysis and are used to understand risks of modern models. However, there is a lack of discussion on the vulnerabilities of these measurements for more complex computer vision tasks. In this paper, we consider multi-label image classification and, specifically, object categorization tasks. First, we highlight design choices and trade-offs for measurement that involve more nuance than discussed in prior computer vision literature. These challenges are related to the necessary scale of data, definition of groups for images, choice of metric, and dataset imbalances. Next, through two case studies using modern vision models, we demonstrate that naive implementations of these assessments are brittle. We identify several design choices that look merely like implementation details but significantly impact the conclusions of assessments, both in terms of magnitude and direction (on which group the classifiers work best) of disparities. Based on ablation studies, we propose some recommendations to increase the reliability of these assessments. Finally, through a qualitative analysis we find that concepts with large disparities tend to have varying definitions and representations between groups, with inconsistencies across datasets and annotators. While this result suggests avenues for mitigation through more consistent data collection, it also highlights that ambiguous label definitions remain a challenge when performing model assessments. Vision models are expanding and becoming more ubiquitous; it is even more important that our disparity assessments accurately reflect the true performance of models.
Leveraging Demonstrations with Latent Space Priors
Oct 26, 2022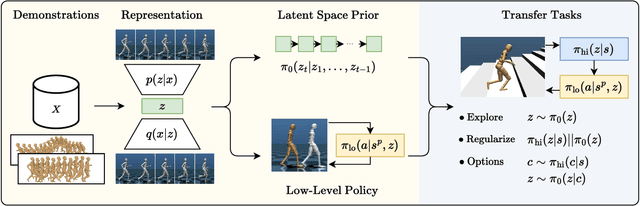
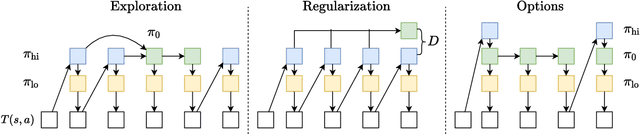


Demonstrations provide insight into relevant state or action space regions, bearing great potential to boost the efficiency and practicality of reinforcement learning agents. In this work, we propose to leverage demonstration datasets by combining skill learning and sequence modeling. Starting with a learned joint latent space, we separately train a generative model of demonstration sequences and an accompanying low-level policy. The sequence model forms a latent space prior over plausible demonstration behaviors to accelerate learning of high-level policies. We show how to acquire such priors from state-only motion capture demonstrations and explore several methods for integrating them into policy learning on transfer tasks. Our experimental results confirm that latent space priors provide significant gains in learning speed and final performance in a set of challenging sparse-reward environments with a complex, simulated humanoid. Videos, source code and pre-trained models are available at the corresponding project website at https://facebookresearch.github.io/latent-space-priors .
Contextual bandits with concave rewards, and an application to fair ranking
Oct 18, 2022
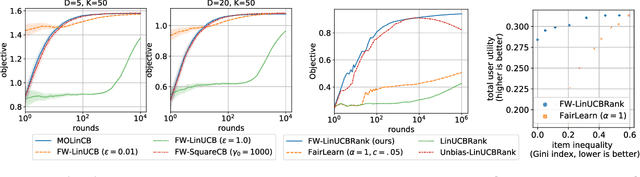
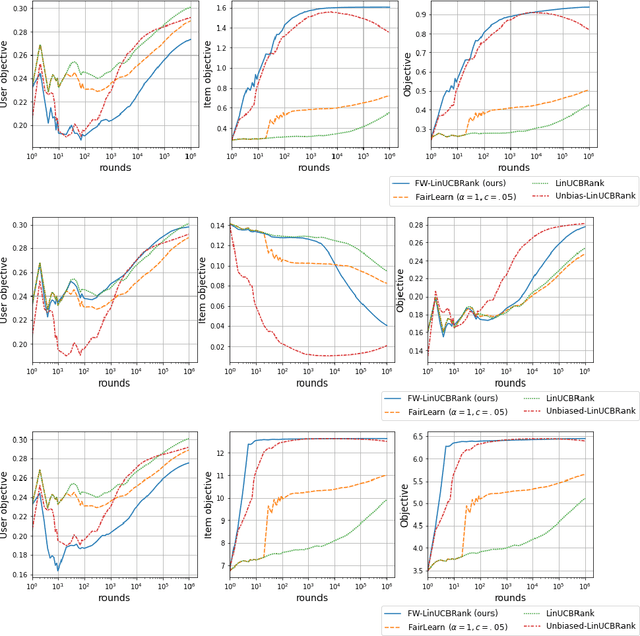
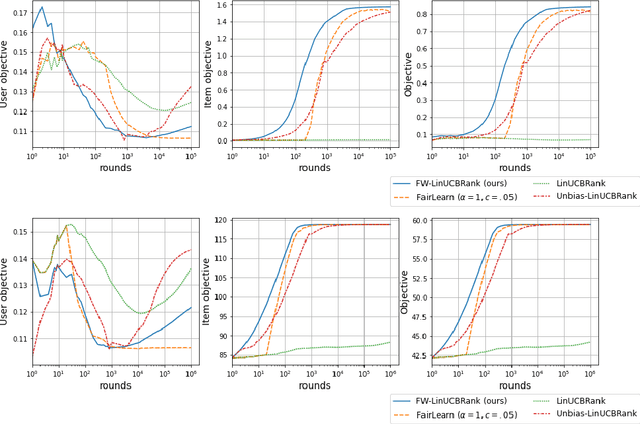
We consider Contextual Bandits with Concave Rewards (CBCR), a multi-objective bandit problem where the desired trade-off between the rewards is defined by a known concave objective function, and the reward vector depends on an observed stochastic context. We present the first algorithm with provably vanishing regret for CBCR without restrictions on the policy space, whereas prior works were restricted to finite policy spaces or tabular representations. Our solution is based on a geometric interpretation of CBCR algorithms as optimization algorithms over the convex set of expected rewards spanned by all stochastic policies. Building on Frank-Wolfe analyses in constrained convex optimization, we derive a novel reduction from the CBCR regret to the regret of a scalar-reward bandit problem. We illustrate how to apply the reduction off-the-shelf to obtain algorithms for CBCR with both linear and general reward functions, in the case of non-combinatorial actions. Motivated by fairness in recommendation, we describe a special case of CBCR with rankings and fairness-aware objectives, leading to the first algorithm with regret guarantees for contextual combinatorial bandits with fairness of exposure.
Fast online ranking with fairness of exposure
Sep 13, 2022
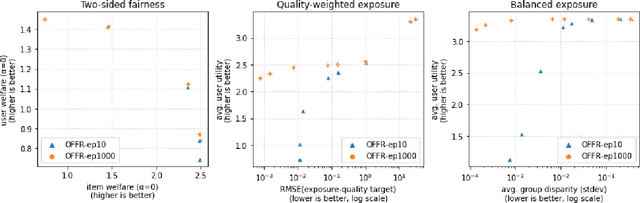
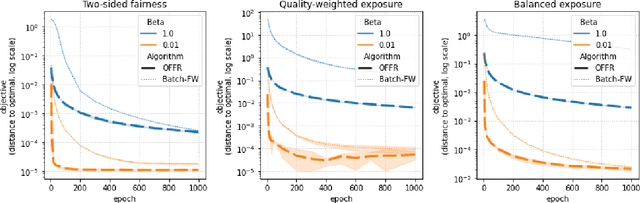

As recommender systems become increasingly central for sorting and prioritizing the content available online, they have a growing impact on the opportunities or revenue of their items producers. For instance, they influence which recruiter a resume is recommended to, or to whom and how much a music track, video or news article is being exposed. This calls for recommendation approaches that not only maximize (a proxy of) user satisfaction, but also consider some notion of fairness in the exposure of items or groups of items. Formally, such recommendations are usually obtained by maximizing a concave objective function in the space of randomized rankings. When the total exposure of an item is defined as the sum of its exposure over users, the optimal rankings of every users become coupled, which makes the optimization process challenging. Existing approaches to find these rankings either solve the global optimization problem in a batch setting, i.e., for all users at once, which makes them inapplicable at scale, or are based on heuristics that have weak theoretical guarantees. In this paper, we propose the first efficient online algorithm to optimize concave objective functions in the space of rankings which applies to every concave and smooth objective function, such as the ones found for fairness of exposure. Based on online variants of the Frank-Wolfe algorithm, we show that our algorithm is computationally fast, generating rankings on-the-fly with computation cost dominated by the sort operation, memory efficient, and has strong theoretical guarantees. Compared to baseline policies that only maximize user-side performance, our algorithm allows to incorporate complex fairness of exposure criteria in the recommendations with negligible computational overhead.
Measuring and signing fairness as performance under multiple stakeholder distributions
Jul 20, 2022As learning machines increase their influence on decisions concerning human lives, analyzing their fairness properties becomes a subject of central importance. Yet, our best tools for measuring the fairness of learning systems are rigid fairness metrics encapsulated as mathematical one-liners, offer limited power to the stakeholders involved in the prediction task, and are easy to manipulate when we exhort excessive pressure to optimize them. To advance these issues, we propose to shift focus from shaping fairness metrics to curating the distributions of examples under which these are computed. In particular, we posit that every claim about fairness should be immediately followed by the tagline "Fair under what examples, and collected by whom?". By highlighting connections to the literature in domain generalization, we propose to measure fairness as the ability of the system to generalize under multiple stress tests -- distributions of examples with social relevance. We encourage each stakeholder to curate one or multiple stress tests containing examples reflecting their (possibly conflicting) interests. The machine passes or fails each stress test by falling short of or exceeding a pre-defined metric value. The test results involve all stakeholders in a discussion about how to improve the learning system, and provide flexible assessments of fairness dependent on context and based on interpretable data. We provide full implementation guidelines for stress testing, illustrate both the benefits and shortcomings of this framework, and introduce a cryptographic scheme to enable a degree of prediction accountability from system providers.
Optimizing generalized Gini indices for fairness in rankings
Apr 14, 2022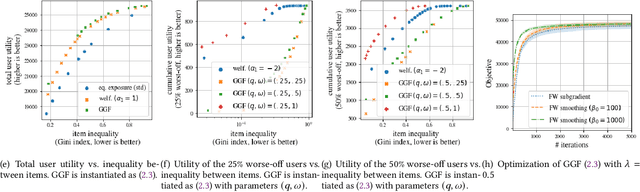
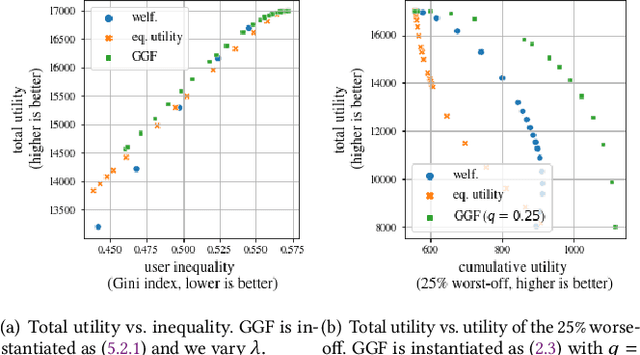
There is growing interest in designing recommender systems that aim at being fair towards item producers or their least satisfied users. Inspired by the domain of inequality measurement in economics, this paper explores the use of generalized Gini welfare functions (GGFs) as a means to specify the normative criterion that recommender systems should optimize for. GGFs weight individuals depending on their ranks in the population, giving more weight to worse-off individuals to promote equality. Depending on these weights, GGFs minimize the Gini index of item exposure to promote equality between items, or focus on the performance on specific quantiles of least satisfied users. GGFs for ranking are challenging to optimize because they are non-differentiable. We resolve this challenge by leveraging tools from non-smooth optimization and projection operators used in differentiable sorting. We present experiments using real datasets with up to 15k users and items, which show that our approach obtains better trade-offs than the baselines on a variety of recommendation tasks and fairness criteria.
Fairness Indicators for Systematic Assessments of Visual Feature Extractors
Feb 15, 2022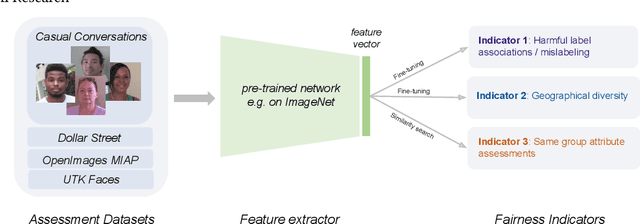


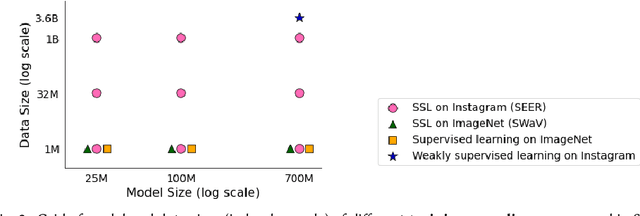
Does everyone equally benefit from computer vision systems? Answers to this question become more and more important as computer vision systems are deployed at large scale, and can spark major concerns when they exhibit vast performance discrepancies between people from various demographic and social backgrounds. Systematic diagnosis of fairness, harms, and biases of computer vision systems is an important step towards building socially responsible systems. To initiate an effort towards standardized fairness audits, we propose three fairness indicators, which aim at quantifying harms and biases of visual systems. Our indicators use existing publicly available datasets collected for fairness evaluations, and focus on three main types of harms and bias identified in the literature, namely harmful label associations, disparity in learned representations of social and demographic traits, and biased performance on geographically diverse images from across the world.We define precise experimental protocols applicable to a wide range of computer vision models. These indicators are part of an ever-evolving suite of fairness probes and are not intended to be a substitute for a thorough analysis of the broader impact of the new computer vision technologies. Yet, we believe it is a necessary first step towards (1) facilitating the widespread adoption and mandate of the fairness assessments in computer vision research, and (2) tracking progress towards building socially responsible models. To study the practical effectiveness and broad applicability of our proposed indicators to any visual system, we apply them to off-the-shelf models built using widely adopted model training paradigms which vary in their ability to whether they can predict labels on a given image or only produce the embeddings. We also systematically study the effect of data domain and model size.
Two-sided fairness in rankings via Lorenz dominance
Oct 28, 2021
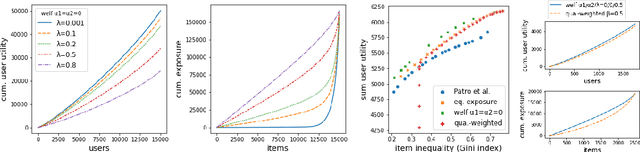

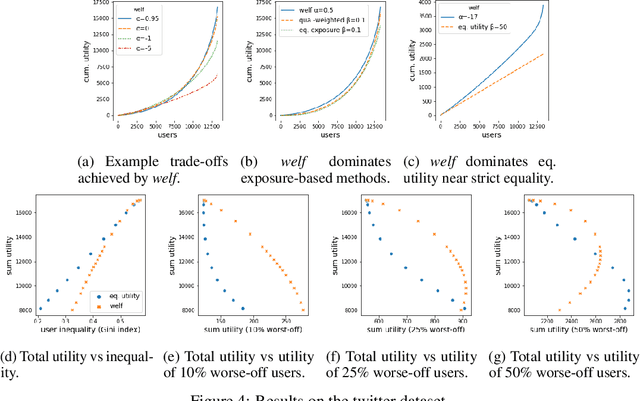
We consider the problem of generating rankings that are fair towards both users and item producers in recommender systems. We address both usual recommendation (e.g., of music or movies) and reciprocal recommendation (e.g., dating). Following concepts of distributive justice in welfare economics, our notion of fairness aims at increasing the utility of the worse-off individuals, which we formalize using the criterion of Lorenz efficiency. It guarantees that rankings are Pareto efficient, and that they maximally redistribute utility from better-off to worse-off, at a given level of overall utility. We propose to generate rankings by maximizing concave welfare functions, and develop an efficient inference procedure based on the Frank-Wolfe algorithm. We prove that unlike existing approaches based on fairness constraints, our approach always produces fair rankings. Our experiments also show that it increases the utility of the worse-off at lower costs in terms of overall utility.
Hierarchical Skills for Efficient Exploration
Oct 20, 2021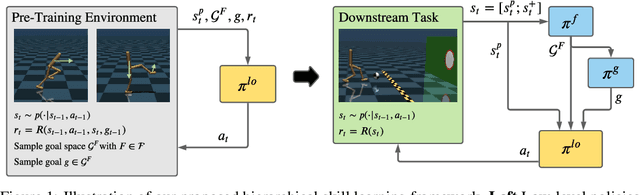
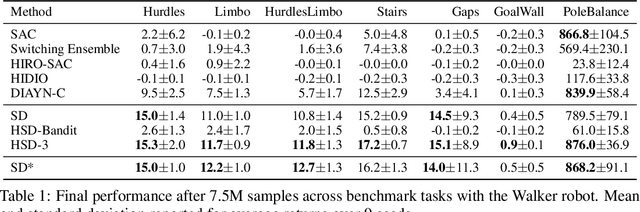


In reinforcement learning, pre-trained low-level skills have the potential to greatly facilitate exploration. However, prior knowledge of the downstream task is required to strike the right balance between generality (fine-grained control) and specificity (faster learning) in skill design. In previous work on continuous control, the sensitivity of methods to this trade-off has not been addressed explicitly, as locomotion provides a suitable prior for navigation tasks, which have been of foremost interest. In this work, we analyze this trade-off for low-level policy pre-training with a new benchmark suite of diverse, sparse-reward tasks for bipedal robots. We alleviate the need for prior knowledge by proposing a hierarchical skill learning framework that acquires skills of varying complexity in an unsupervised manner. For utilization on downstream tasks, we present a three-layered hierarchical learning algorithm to automatically trade off between general and specific skills as required by the respective task. In our experiments, we show that our approach performs this trade-off effectively and achieves better results than current state-of-the-art methods for end- to-end hierarchical reinforcement learning and unsupervised skill discovery. Code and videos are available at https://facebookresearch.github.io/hsd3 .