 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLevent Sagun
Networked Inequality: Preferential Attachment Bias in Graph Neural Network Link Prediction
Sep 29, 2023
Graph neural network (GNN) link prediction is increasingly deployed in citation, collaboration, and online social networks to recommend academic literature, collaborators, and friends. While prior research has investigated the dyadic fairness of GNN link prediction, the within-group fairness and ``rich get richer'' dynamics of link prediction remain underexplored. However, these aspects have significant consequences for degree and power imbalances in networks. In this paper, we shed light on how degree bias in networks affects Graph Convolutional Network (GCN) link prediction. In particular, we theoretically uncover that GCNs with a symmetric normalized graph filter have a within-group preferential attachment bias. We validate our theoretical analysis on real-world citation, collaboration, and online social networks. We further bridge GCN's preferential attachment bias with unfairness in link prediction and propose a new within-group fairness metric. This metric quantifies disparities in link prediction scores between social groups, towards combating the amplification of degree and power disparities. Finally, we propose a simple training-time strategy to alleviate within-group unfairness, and we show that it is effective on citation, online social, and credit networks.
Weisfeiler and Lehman Go Measurement Modeling: Probing the Validity of the WL Test
Jul 11, 2023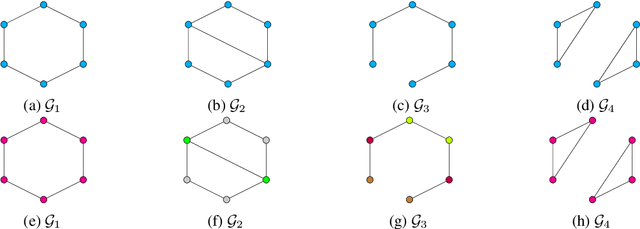
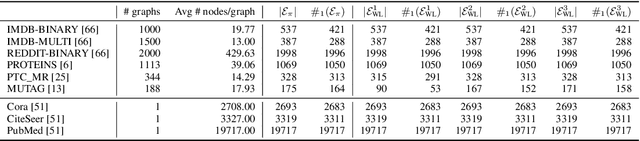
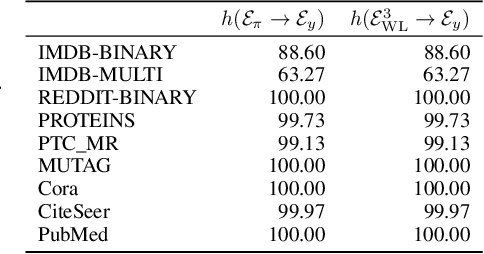
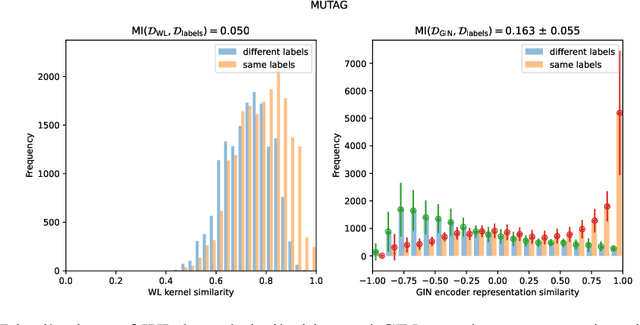
The expressive power of graph neural networks is usually measured by comparing how many pairs of graphs or nodes an architecture can possibly distinguish as non-isomorphic to those distinguishable by the $k$-dimensional Weisfeiler-Lehman ($k$-WL) test. In this paper, we uncover misalignments between practitioners' conceptualizations of expressive power and $k$-WL through a systematic analysis of the reliability and validity of $k$-WL. We further conduct a survey ($n = 18$) of practitioners to surface their conceptualizations of expressive power and their assumptions about $k$-WL. In contrast to practitioners' opinions, our analysis (which draws from graph theory and benchmark auditing) reveals that $k$-WL does not guarantee isometry, can be irrelevant to real-world graph tasks, and may not promote generalization or trustworthiness. We argue for extensional definitions and measurement of expressive power based on benchmarks; we further contribute guiding questions for constructing such benchmarks, which is critical for progress in graph machine learning.
Simplicity Bias Leads to Amplified Performance Disparities
Dec 13, 2022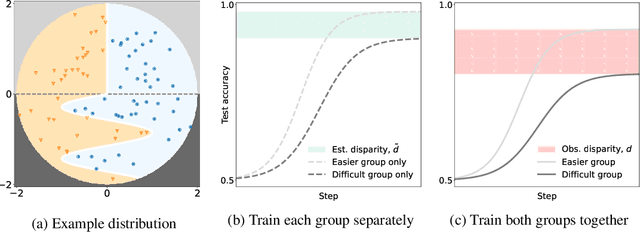
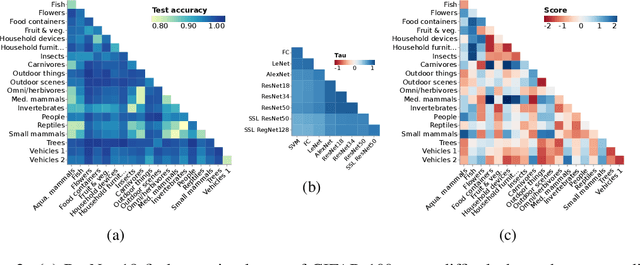
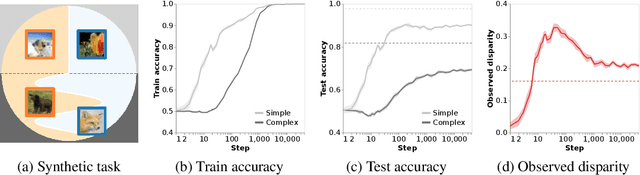
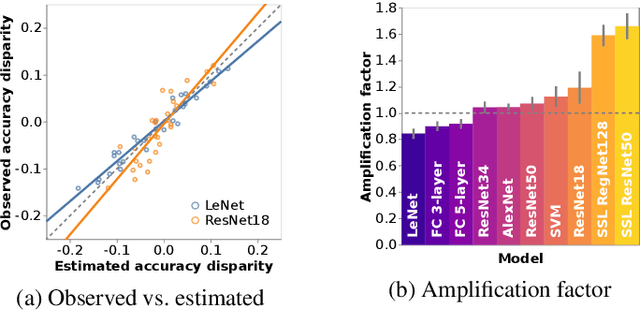
The simple idea that not all things are equally difficult has surprising implications when applied in a fairness context. In this work we explore how "difficulty" is model-specific, such that different models find different parts of a dataset challenging. When difficulty correlates with group information, we term this difficulty disparity. Drawing a connection with recent work exploring the inductive bias towards simplicity of SGD-trained models, we show that when such a disparity exists, it is further amplified by commonly-used models. We quantify this amplification factor across a range of settings aiming towards a fuller understanding of the role of model bias. We also present a challenge to the simplifying assumption that "fixing" a dataset is sufficient to ensure unbiased performance.
Measuring and signing fairness as performance under multiple stakeholder distributions
Jul 20, 2022As learning machines increase their influence on decisions concerning human lives, analyzing their fairness properties becomes a subject of central importance. Yet, our best tools for measuring the fairness of learning systems are rigid fairness metrics encapsulated as mathematical one-liners, offer limited power to the stakeholders involved in the prediction task, and are easy to manipulate when we exhort excessive pressure to optimize them. To advance these issues, we propose to shift focus from shaping fairness metrics to curating the distributions of examples under which these are computed. In particular, we posit that every claim about fairness should be immediately followed by the tagline "Fair under what examples, and collected by whom?". By highlighting connections to the literature in domain generalization, we propose to measure fairness as the ability of the system to generalize under multiple stress tests -- distributions of examples with social relevance. We encourage each stakeholder to curate one or multiple stress tests containing examples reflecting their (possibly conflicting) interests. The machine passes or fails each stress test by falling short of or exceeding a pre-defined metric value. The test results involve all stakeholders in a discussion about how to improve the learning system, and provide flexible assessments of fairness dependent on context and based on interpretable data. We provide full implementation guidelines for stress testing, illustrate both the benefits and shortcomings of this framework, and introduce a cryptographic scheme to enable a degree of prediction accountability from system providers.
Understanding out-of-distribution accuracies through quantifying difficulty of test samples
Mar 28, 2022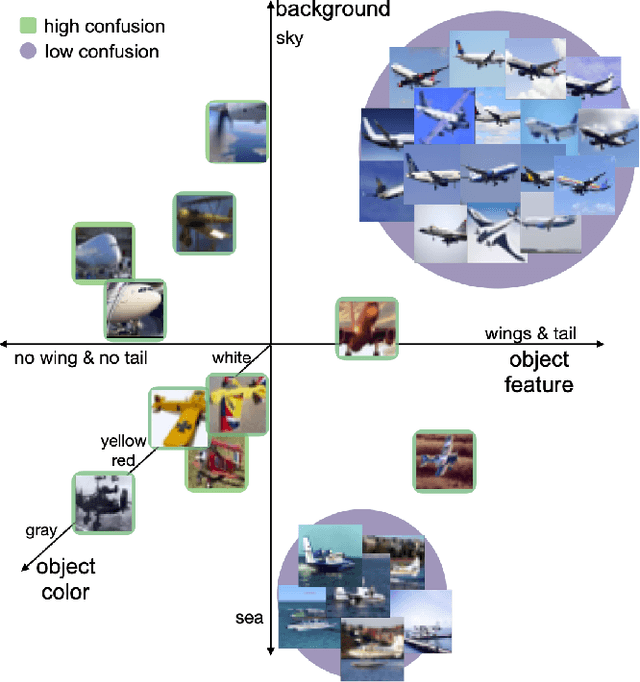
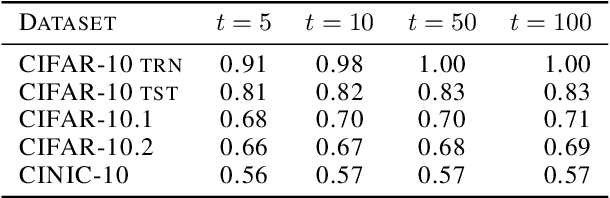
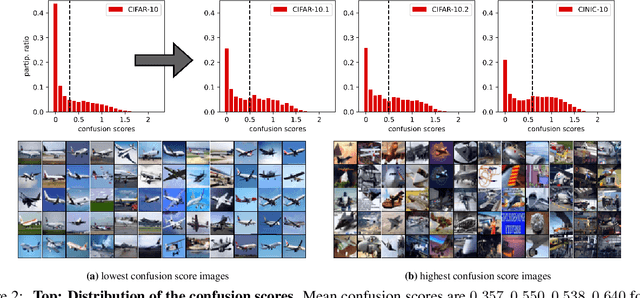
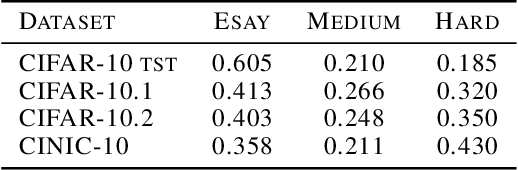
Existing works show that although modern neural networks achieve remarkable generalization performance on the in-distribution (ID) dataset, the accuracy drops significantly on the out-of-distribution (OOD) datasets \cite{recht2018cifar, recht2019imagenet}. To understand why a variety of models consistently make more mistakes in the OOD datasets, we propose a new metric to quantify the difficulty of the test images (either ID or OOD) that depends on the interaction of the training dataset and the model. In particular, we introduce \textit{confusion score} as a label-free measure of image difficulty which quantifies the amount of disagreement on a given test image based on the class conditional probabilities estimated by an ensemble of trained models. Using the confusion score, we investigate CIFAR-10 and its OOD derivatives. Next, by partitioning test and OOD datasets via their confusion scores, we predict the relationship between ID and OOD accuracies for various architectures. This allows us to obtain an estimator of the OOD accuracy of a given model only using ID test labels. Our observations indicate that the biggest contribution to the accuracy drop comes from images with high confusion scores. Upon further inspection, we report on the nature of the misclassified images grouped by their confusion scores: \textit{(i)} images with high confusion scores contain \textit{weak spurious correlations} that appear in multiple classes in the training data and lack clear \textit{class-specific features}, and \textit{(ii)} images with low confusion scores exhibit spurious correlations that belong to another class, namely \textit{class-specific spurious correlations}.
Vision Models Are More Robust And Fair When Pretrained On Uncurated Images Without Supervision
Feb 22, 2022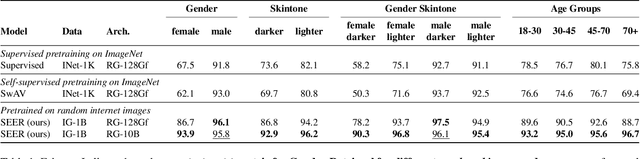
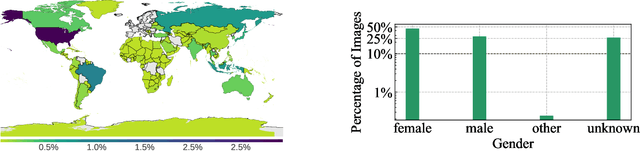
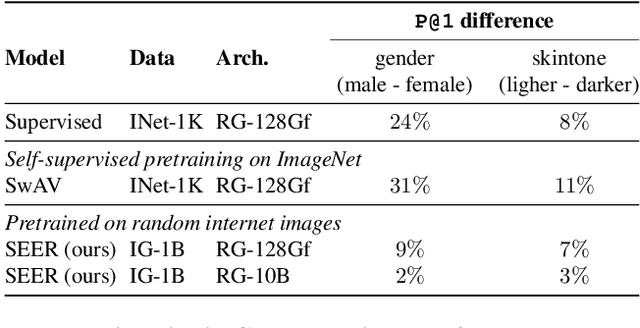
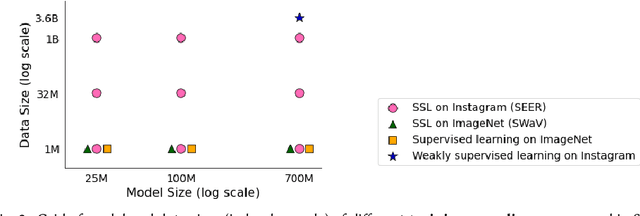
Discriminative self-supervised learning allows training models on any random group of internet images, and possibly recover salient information that helps differentiate between the images. Applied to ImageNet, this leads to object centric features that perform on par with supervised features on most object-centric downstream tasks. In this work, we question if using this ability, we can learn any salient and more representative information present in diverse unbounded set of images from across the globe. To do so, we train models on billions of random images without any data pre-processing or prior assumptions about what we want the model to learn. We scale our model size to dense 10 billion parameters to avoid underfitting on a large data size. We extensively study and validate our model performance on over 50 benchmarks including fairness, robustness to distribution shift, geographical diversity, fine grained recognition, image copy detection and many image classification datasets. The resulting model, not only captures well semantic information, it also captures information about artistic style and learns salient information such as geolocations and multilingual word embeddings based on visual content only. More importantly, we discover that such model is more robust, more fair, less harmful and less biased than supervised models or models trained on object centric datasets such as ImageNet.
Fairness Indicators for Systematic Assessments of Visual Feature Extractors
Feb 15, 2022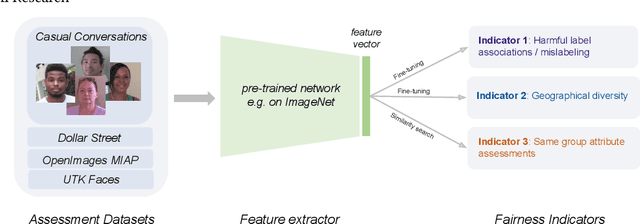


Does everyone equally benefit from computer vision systems? Answers to this question become more and more important as computer vision systems are deployed at large scale, and can spark major concerns when they exhibit vast performance discrepancies between people from various demographic and social backgrounds. Systematic diagnosis of fairness, harms, and biases of computer vision systems is an important step towards building socially responsible systems. To initiate an effort towards standardized fairness audits, we propose three fairness indicators, which aim at quantifying harms and biases of visual systems. Our indicators use existing publicly available datasets collected for fairness evaluations, and focus on three main types of harms and bias identified in the literature, namely harmful label associations, disparity in learned representations of social and demographic traits, and biased performance on geographically diverse images from across the world.We define precise experimental protocols applicable to a wide range of computer vision models. These indicators are part of an ever-evolving suite of fairness probes and are not intended to be a substitute for a thorough analysis of the broader impact of the new computer vision technologies. Yet, we believe it is a necessary first step towards (1) facilitating the widespread adoption and mandate of the fairness assessments in computer vision research, and (2) tracking progress towards building socially responsible models. To study the practical effectiveness and broad applicability of our proposed indicators to any visual system, we apply them to off-the-shelf models built using widely adopted model training paradigms which vary in their ability to whether they can predict labels on a given image or only produce the embeddings. We also systematically study the effect of data domain and model size.
Transformed CNNs: recasting pre-trained convolutional layers with self-attention
Jun 10, 2021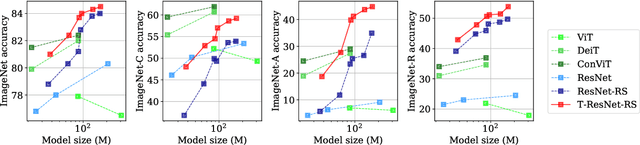
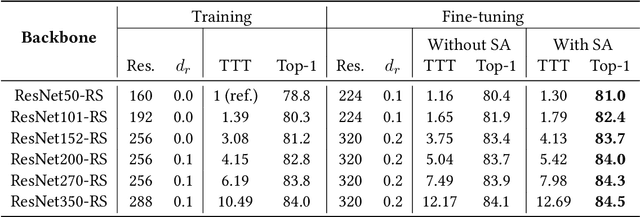
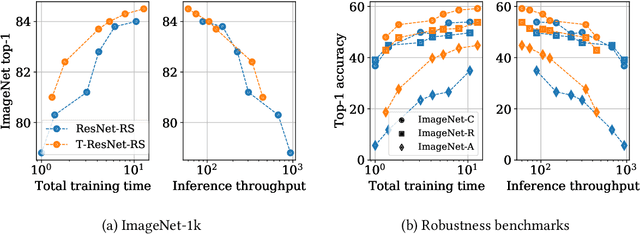
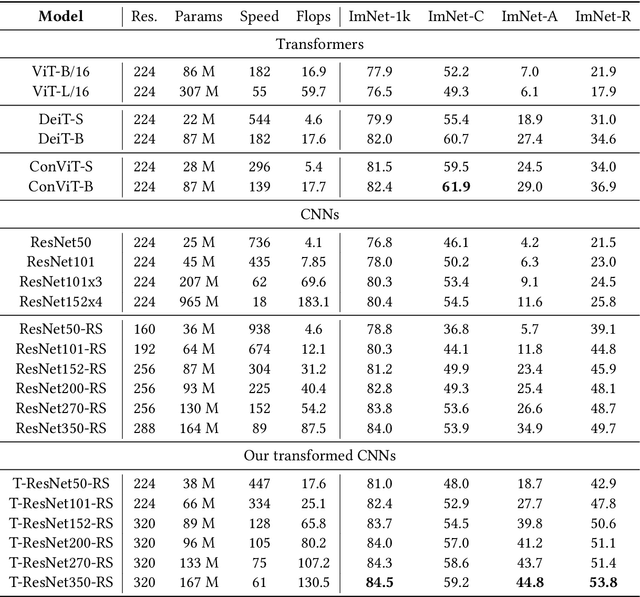
Vision Transformers (ViT) have recently emerged as a powerful alternative to convolutional networks (CNNs). Although hybrid models attempt to bridge the gap between these two architectures, the self-attention layers they rely on induce a strong computational bottleneck, especially at large spatial resolutions. In this work, we explore the idea of reducing the time spent training these layers by initializing them as convolutional layers. This enables us to transition smoothly from any pre-trained CNN to its functionally identical hybrid model, called Transformed CNN (T-CNN). With only 50 epochs of fine-tuning, the resulting T-CNNs demonstrate significant performance gains over the CNN (+2.2% top-1 on ImageNet-1k for a ResNet50-RS) as well as substantially improved robustness (+11% top-1 on ImageNet-C). We analyze the representations learnt by the T-CNN, providing deeper insights into the fruitful interplay between convolutions and self-attention. Finally, we experiment initializing the T-CNN from a partially trained CNN, and find that it reaches better performance than the corresponding hybrid model trained from scratch, while reducing training time.
ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases
Mar 19, 2021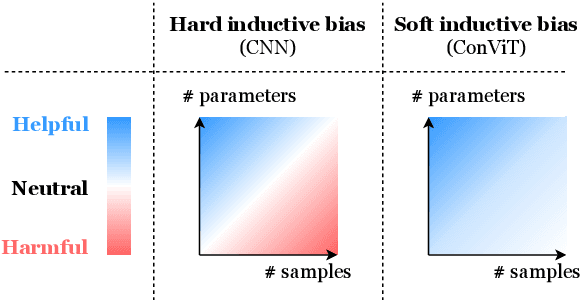
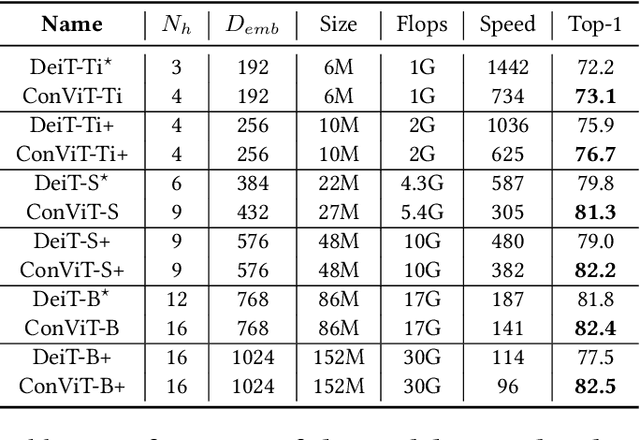
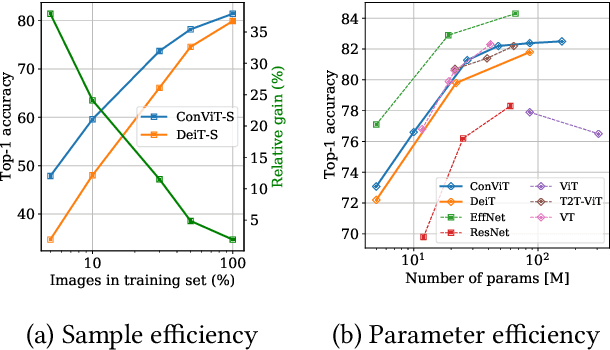
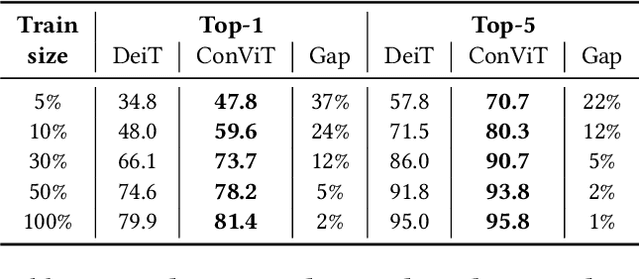
Convolutional architectures have proven extremely successful for vision tasks. Their hard inductive biases enable sample-efficient learning, but come at the cost of a potentially lower performance ceiling. Vision Transformers (ViTs) rely on more flexible self-attention layers, and have recently outperformed CNNs for image classification. However, they require costly pre-training on large external datasets or distillation from pre-trained convolutional networks. In this paper, we ask the following question: is it possible to combine the strengths of these two architectures while avoiding their respective limitations? To this end, we introduce gated positional self-attention (GPSA), a form of positional self-attention which can be equipped with a "soft" convolutional inductive bias. We initialize the GPSA layers to mimic the locality of convolutional layers, then give each attention head the freedom to escape locality by adjusting a gating parameter regulating the attention paid to position versus content information. The resulting convolutional-like ViT architecture, ConViT, outperforms the DeiT on ImageNet, while offering a much improved sample efficiency. We further investigate the role of locality in learning by first quantifying how it is encouraged in vanilla self-attention layers, then analyzing how it is escaped in GPSA layers. We conclude by presenting various ablations to better understand the success of the ConViT. Our code and models are released publicly.