 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Huang": models, code, and papers
From explained variance of correlated components to PCA without orthogonality constraints
Feb 07, 2024
Block Principal Component Analysis (Block PCA) of a data matrix A, where loadings Z are determined by maximization of AZ 2 over unit norm orthogonal loadings, is difficult to use for the design of sparse PCA by 1 regularization, due to the difficulty of taking care of both the orthogonality constraint on loadings and the non differentiable 1 penalty. Our objective in this paper is to relax the orthogonality constraint on loadings by introducing new objective functions expvar(Y) which measure the part of the variance of the data matrix A explained by correlated components Y = AZ. So we propose first a comprehensive study of mathematical and numerical properties of expvar(Y) for two existing definitions Zou et al. [2006], Shen and Huang [2008] and four new definitions. Then we show that only two of these explained variance are fit to use as objective function in block PCA formulations for A rid of orthogonality constraints.
Shadowcast: Stealthy Data Poisoning Attacks Against Vision-Language Models
Feb 05, 2024Vision-Language Models (VLMs) excel in generating textual responses from visual inputs, yet their versatility raises significant security concerns. This study takes the first step in exposing VLMs' susceptibility to data poisoning attacks that can manipulate responses to innocuous, everyday prompts. We introduce Shadowcast, a stealthy data poisoning attack method where poison samples are visually indistinguishable from benign images with matching texts. Shadowcast demonstrates effectiveness in two attack types. The first is Label Attack, tricking VLMs into misidentifying class labels, such as confusing Donald Trump for Joe Biden. The second is Persuasion Attack, which leverages VLMs' text generation capabilities to craft narratives, such as portraying junk food as health food, through persuasive and seemingly rational descriptions. We show that Shadowcast are highly effective in achieving attacker's intentions using as few as 50 poison samples. Moreover, these poison samples remain effective across various prompts and are transferable across different VLM architectures in the black-box setting. This work reveals how poisoned VLMs can generate convincing yet deceptive misinformation and underscores the importance of data quality for responsible deployments of VLMs. Our code is available at: https://github.com/umd-huang-lab/VLM-Poisoning.
Mementos: A Comprehensive Benchmark for Multimodal Large Language Model Reasoning over Image Sequences
Jan 25, 2024Multimodal Large Language Models (MLLMs) have demonstrated proficiency in handling a variety of visual-language tasks. However, current MLLM benchmarks are predominantly designed to evaluate reasoning based on static information about a single image, and the ability of modern MLLMs to extrapolate from image sequences, which is essential for understanding our ever-changing world, has been less investigated. To address this challenge, this paper introduces Mementos, a new benchmark designed to assess MLLMs' sequential image reasoning abilities. Mementos features 4,761 diverse image sequences with varying lengths. We also employ a GPT-4 assisted method to evaluate MLLM reasoning performance. Through a careful evaluation of nine recent MLLMs on Mementos, including GPT-4V and Gemini, we find that they struggle to accurately describe dynamic information about given image sequences, often leading to hallucinations/misrepresentations of objects and their corresponding behaviors. Our quantitative analysis and case studies identify three key factors impacting MLLMs' sequential image reasoning: the correlation between object and behavioral hallucinations, the influence of cooccurring behaviors, and the compounding impact of behavioral hallucinations. Our dataset is available at https://github.com/umd-huang-lab/Mementos.
Faster Sampling without Isoperimetry via Diffusion-based Monte Carlo
Jan 12, 2024To sample from a general target distribution $p_*\propto e^{-f_*}$ beyond the isoperimetric condition, Huang et al. (2023) proposed to perform sampling through reverse diffusion, giving rise to Diffusion-based Monte Carlo (DMC). Specifically, DMC follows the reverse SDE of a diffusion process that transforms the target distribution to the standard Gaussian, utilizing a non-parametric score estimation. However, the original DMC algorithm encountered high gradient complexity, resulting in an exponential dependency on the error tolerance $\epsilon$ of the obtained samples. In this paper, we demonstrate that the high complexity of DMC originates from its redundant design of score estimation, and proposed a more efficient algorithm, called RS-DMC, based on a novel recursive score estimation method. In particular, we first divide the entire diffusion process into multiple segments and then formulate the score estimation step (at any time step) as a series of interconnected mean estimation and sampling subproblems accordingly, which are correlated in a recursive manner. Importantly, we show that with a proper design of the segment decomposition, all sampling subproblems will only need to tackle a strongly log-concave distribution, which can be very efficient to solve using the Langevin-based samplers with a provably rapid convergence rate. As a result, we prove that the gradient complexity of RS-DMC only has a quasi-polynomial dependency on $\epsilon$, which significantly improves exponential gradient complexity in Huang et al. (2023). Furthermore, under commonly used dissipative conditions, our algorithm is provably much faster than the popular Langevin-based algorithms. Our algorithm design and theoretical framework illuminate a novel direction for addressing sampling problems, which could be of broader applicability in the community.
SelfOcc: Self-Supervised Vision-Based 3D Occupancy Prediction
Nov 29, 20233D occupancy prediction is an important task for the robustness of vision-centric autonomous driving, which aims to predict whether each point is occupied in the surrounding 3D space. Existing methods usually require 3D occupancy labels to produce meaningful results. However, it is very laborious to annotate the occupancy status of each voxel. In this paper, we propose SelfOcc to explore a self-supervised way to learn 3D occupancy using only video sequences. We first transform the images into the 3D space (e.g., bird's eye view) to obtain 3D representation of the scene. We directly impose constraints on the 3D representations by treating them as signed distance fields. We can then render 2D images of previous and future frames as self-supervision signals to learn the 3D representations. We propose an MVS-embedded strategy to directly optimize the SDF-induced weights with multiple depth proposals. Our SelfOcc outperforms the previous best method SceneRF by 58.7% using a single frame as input on SemanticKITTI and is the first self-supervised work that produces reasonable 3D occupancy for surround cameras on nuScenes. SelfOcc produces high-quality depth and achieves state-of-the-art results on novel depth synthesis, monocular depth estimation, and surround-view depth estimation on the SemanticKITTI, KITTI-2015, and nuScenes, respectively. Code: https://github.com/huang-yh/SelfOcc.
LLMs cannot find reasoning errors, but can correct them!
Nov 14, 2023While self-correction has shown promise in improving LLM outputs in terms of style and quality (e.g. Chen et al., 2023; Madaan et al., 2023), recent attempts to self-correct logical or reasoning errors often cause correct answers to become incorrect, resulting in worse performances overall (Huang et al., 2023). In this paper, we break down the self-correction process into two core components: mistake finding and output correction. For mistake finding, we release BIG-Bench Mistake, a dataset of logical mistakes in Chain-of-Thought reasoning traces. We provide benchmark numbers for several state-of-the-art LLMs, and demonstrate that LLMs generally struggle with finding logical mistakes. For output correction, we propose a backtracking method which provides large improvements when given information on mistake location. We construe backtracking as a lightweight alternative to reinforcement learning methods, and show that it remains effective with a reward model at 60-70% accuracy.
Visual Storytelling with Question-Answer Plans
Oct 17, 2023Visual storytelling aims to generate compelling narratives from image sequences. Existing models often focus on enhancing the representation of the image sequence, e.g., with external knowledge sources or advanced graph structures. Despite recent progress, the stories are often repetitive, illogical, and lacking in detail. To mitigate these issues, we present a novel framework which integrates visual representations with pretrained language models and planning. Our model translates the image sequence into a visual prefix, a sequence of continuous embeddings which language models can interpret. It also leverages a sequence of question-answer pairs as a blueprint plan for selecting salient visual concepts and determining how they should be assembled into a narrative. Automatic and human evaluation on the VIST benchmark (Huang et al., 2016) demonstrates that blueprint-based models generate stories that are more coherent, interesting, and natural compared to competitive baselines and state-of-the-art systems.
Building on Huang et al. GlossBERT for Word Sense Disambiguation
Dec 14, 2021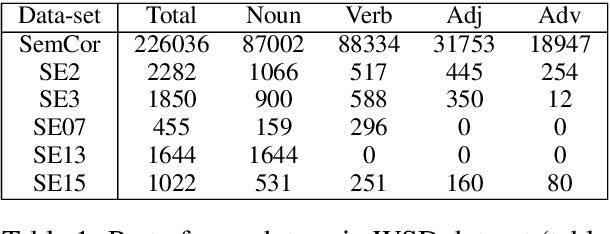
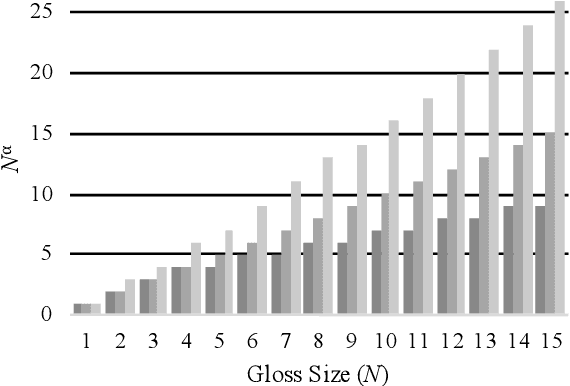
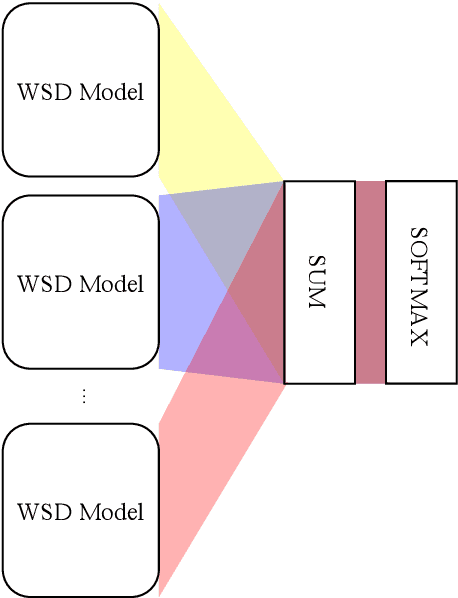
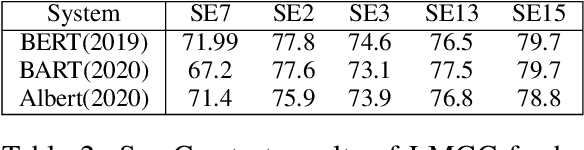
We propose to take on the problem ofWord Sense Disambiguation (WSD). In language, words of the same form can take different meanings depending on context. While humans easily infer the meaning or gloss of such words by their context, machines stumble on this task.As such, we intend to replicated and expand upon the results of Huang et al.GlossBERT, a model which they design to disambiguate these words (Huang et al.,2019). Specifically, we propose the following augmentations: data-set tweaking(alpha hyper-parameter), ensemble methods, and replacement of BERT with BART andALBERT. The following GitHub repository contains all code used in this report, which extends on the code made available by Huang et al.