 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Ensemble Exploration for Unsupervised Skill Discovery
May 25, 2024Unsupervised Reinforcement Learning (RL) provides a promising paradigm for learning useful behaviors via reward-free per-training. Existing methods for unsupervised RL mainly conduct empowerment-driven skill discovery or entropy-based exploration. However, empowerment often leads to static skills, and pure exploration only maximizes the state coverage rather than learning useful behaviors. In this paper, we propose a novel unsupervised RL framework via an ensemble of skills, where each skill performs partition exploration based on the state prototypes. Thus, each skill can explore the clustered area locally, and the ensemble skills maximize the overall state coverage. We adopt state-distribution constraints for the skill occupancy and the desired cluster for learning distinguishable skills. Theoretical analysis is provided for the state entropy and the resulting skill distributions. Based on extensive experiments on several challenging tasks, we find our method learns well-explored ensemble skills and achieves superior performance in various downstream tasks compared to previous methods.
Contrastive Representation for Data Filtering in Cross-Domain Offline Reinforcement Learning
May 10, 2024



Cross-domain offline reinforcement learning leverages source domain data with diverse transition dynamics to alleviate the data requirement for the target domain. However, simply merging the data of two domains leads to performance degradation due to the dynamics mismatch. Existing methods address this problem by measuring the dynamics gap via domain classifiers while relying on the assumptions of the transferability of paired domains. In this paper, we propose a novel representation-based approach to measure the domain gap, where the representation is learned through a contrastive objective by sampling transitions from different domains. We show that such an objective recovers the mutual-information gap of transition functions in two domains without suffering from the unbounded issue of the dynamics gap in handling significantly different domains. Based on the representations, we introduce a data filtering algorithm that selectively shares transitions from the source domain according to the contrastive score functions. Empirical results on various tasks demonstrate that our method achieves superior performance, using only 10% of the target data to achieve 89.2% of the performance on 100% target dataset with state-of-the-art methods.
Large Scale Foundation Models for Intelligent Manufacturing Applications: A Survey
Dec 22, 2023Although the applications of artificial intelligence especially deep learning had greatly improved various aspects of intelligent manufacturing, they still face challenges for wide employment due to the poor generalization ability, difficulties to establish high-quality training datasets, and unsatisfactory performance of deep learning methods. The emergence of large scale foundational models(LSFMs) had triggered a wave in the field of artificial intelligence, shifting deep learning models from single-task, single-modal, limited data patterns to a paradigm encompassing diverse tasks, multimodal, and pre-training on massive datasets. Although LSFMs had demonstrated powerful generalization capabilities, automatic high-quality training dataset generation and superior performance across various domains, applications of LSFMs on intelligent manufacturing were still in their nascent stage. A systematic overview of this topic was lacking, especially regarding which challenges of deep learning can be addressed by LSFMs and how these challenges can be systematically tackled. To fill this gap, this paper systematically expounded current statue of LSFMs and their advantages in the context of intelligent manufacturing. and compared comprehensively with the challenges faced by current deep learning models in various intelligent manufacturing applications. We also outlined the roadmaps for utilizing LSFMs to address these challenges. Finally, case studies of applications of LSFMs in real-world intelligent manufacturing scenarios were presented to illustrate how LSFMs could help industries, improve their efficiency.
Diffusion Model is an Effective Planner and Data Synthesizer for Multi-Task Reinforcement Learning
May 29, 2023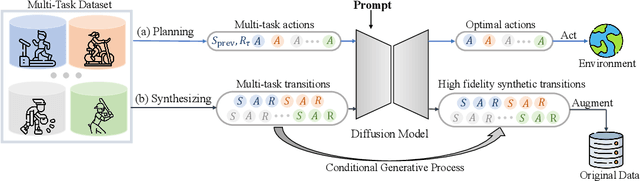



Diffusion models have demonstrated highly-expressive generative capabilities in vision and NLP. Recent studies in reinforcement learning (RL) have shown that diffusion models are also powerful in modeling complex policies or trajectories in offline datasets. However, these works have been limited to single-task settings where a generalist agent capable of addressing multi-task predicaments is absent. In this paper, we aim to investigate the effectiveness of a single diffusion model in modeling large-scale multi-task offline data, which can be challenging due to diverse and multimodal data distribution. Specifically, we propose Multi-Task Diffusion Model (\textsc{MTDiff}), a diffusion-based method that incorporates Transformer backbones and prompt learning for generative planning and data synthesis in multi-task offline settings. \textsc{MTDiff} leverages vast amounts of knowledge available in multi-task data and performs implicit knowledge sharing among tasks. For generative planning, we find \textsc{MTDiff} outperforms state-of-the-art algorithms across 50 tasks on Meta-World and 8 maps on Maze2D. For data synthesis, \textsc{MTDiff} generates high-quality data for testing tasks given a single demonstration as a prompt, which enhances the low-quality datasets for even unseen tasks.
Cross-Domain Policy Adaptation via Value-Guided Data Filtering
May 28, 2023
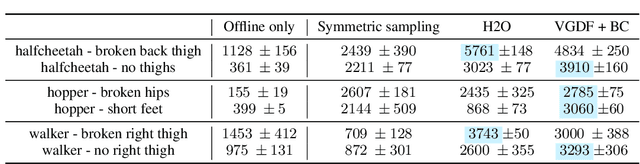


Generalizing policies across different domains with dynamics mismatch poses a significant challenge in reinforcement learning. For example, a robot learns the policy in a simulator, but when it is deployed in the real world, the dynamics of the environment may be different. Given the source and target domain with dynamics mismatch, we consider the online dynamics adaptation problem, in which case the agent can access sufficient source domain data while online interactions with the target domain are limited. Existing research has attempted to solve the problem from the dynamics discrepancy perspective. In this work, we reveal the limitations of these methods and explore the problem from the value difference perspective via a novel insight on the value consistency across domains. Specifically, we present the Value-Guided Data Filtering (VGDF) algorithm, which selectively shares transitions from the source domain based on the proximity of paired value targets across the two domains. Empirical results on various environments with kinematic and morphology shifts demonstrate that our method achieves superior performance compared to prior approaches.
On the Value of Myopic Behavior in Policy Reuse
May 28, 2023



Leveraging learned strategies in unfamiliar scenarios is fundamental to human intelligence. In reinforcement learning, rationally reusing the policies acquired from other tasks or human experts is critical for tackling problems that are difficult to learn from scratch. In this work, we present a framework called Selective Myopic bEhavior Control~(SMEC), which results from the insight that the short-term behaviors of prior policies are sharable across tasks. By evaluating the behaviors of prior policies via a hybrid value function architecture, SMEC adaptively aggregates the sharable short-term behaviors of prior policies and the long-term behaviors of the task policy, leading to coordinated decisions. Empirical results on a collection of manipulation and locomotion tasks demonstrate that SMEC outperforms existing methods, and validate the ability of SMEC to leverage related prior policies.
Quantification before Selection: Active Dynamics Preference for Robust Reinforcement Learning
Sep 28, 2022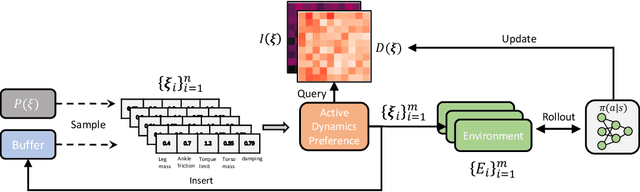
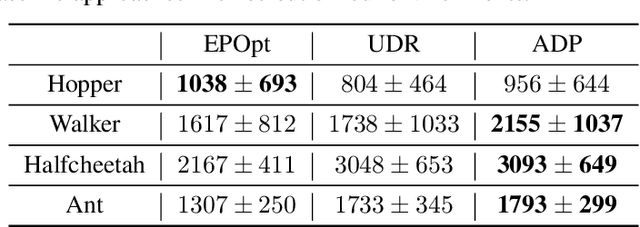
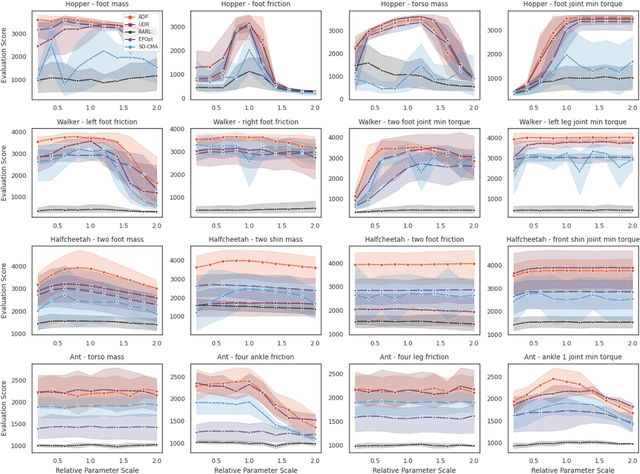

Training a robust policy is critical for policy deployment in real-world systems or dealing with unknown dynamics mismatch in different dynamic systems. Domain Randomization~(DR) is a simple and elegant approach that trains a conservative policy to counter different dynamic systems without expert knowledge about the target system parameters. However, existing works reveal that the policy trained through DR tends to be over-conservative and performs poorly in target domains. Our key insight is that dynamic systems with different parameters provide different levels of difficulty for the policy, and the difficulty of behaving well in a system is constantly changing due to the evolution of the policy. If we can actively sample the systems with proper difficulty for the policy on the fly, it will stabilize the training process and prevent the policy from becoming over-conservative or over-optimistic. To operationalize this idea, we introduce Active Dynamics Preference~(ADP), which quantifies the informativeness and density of sampled system parameters. ADP actively selects system parameters with high informativeness and low density. We validate our approach in four robotic locomotion tasks with various discrepancies between the training and testing environments. Extensive results demonstrate that our approach has superior robustness for system inconsistency compared to several baselines.
Open-Ended Diverse Solution Discovery with Regulated Behavior Patterns for Cross-Domain Adaptation
Sep 24, 2022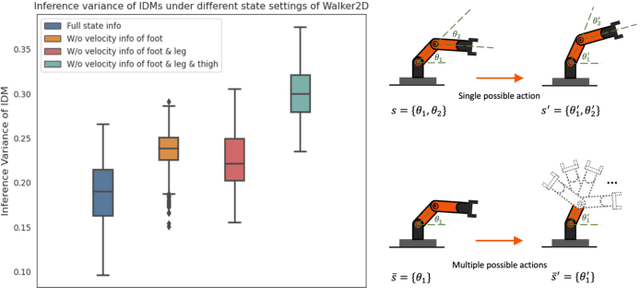
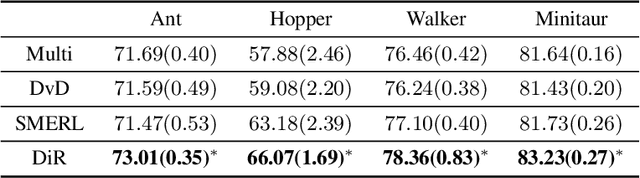
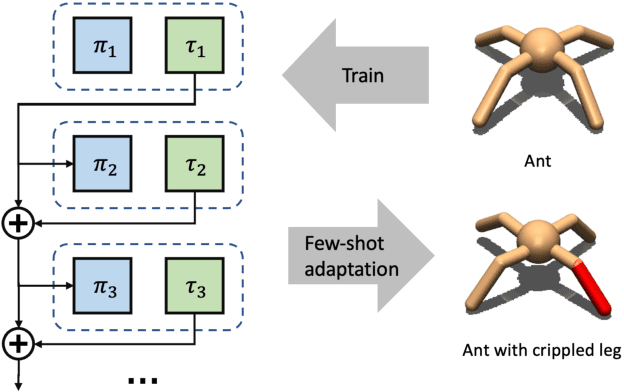
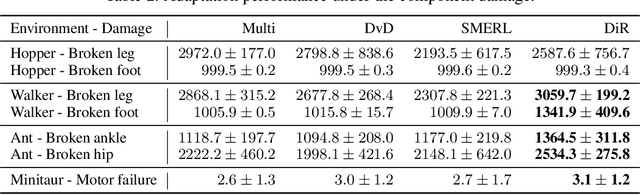
While Reinforcement Learning can achieve impressive results for complex tasks, the learned policies are generally prone to fail in downstream tasks with even minor model mismatch or unexpected perturbations. Recent works have demonstrated that a policy population with diverse behavior characteristics can generalize to downstream environments with various discrepancies. However, such policies might result in catastrophic damage during the deployment in practical scenarios like real-world systems due to the unrestricted behaviors of trained policies. Furthermore, training diverse policies without regulation of the behavior can result in inadequate feasible policies for extrapolating to a wide range of test conditions with dynamics shifts. In this work, we aim to train diverse policies under the regularization of the behavior patterns. We motivate our paradigm by observing the inverse dynamics in the environment with partial state information and propose Diversity in Regulation(DiR) training diverse policies with regulated behaviors to discover desired patterns that benefit the generalization. Considerable empirical results on various variations of different environments indicate that our method attains improvements over other diversity-driven counterparts.
Neural Topic Modeling with Deep Mutual Information Estimation
Mar 12, 2022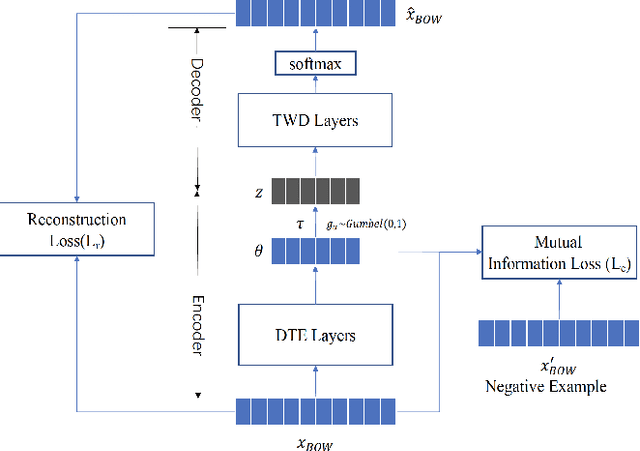
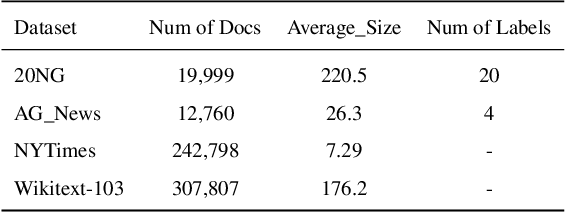
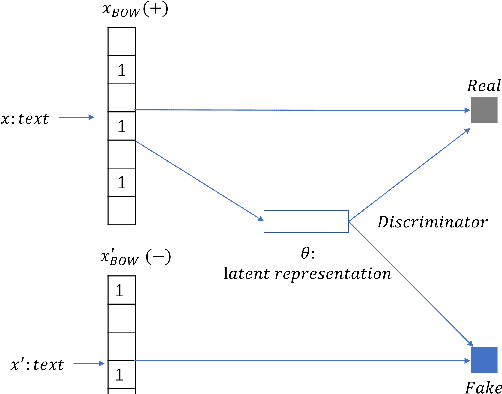
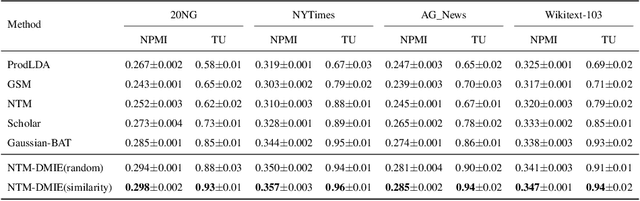
The emerging neural topic models make topic modeling more easily adaptable and extendable in unsupervised text mining. However, the existing neural topic models is difficult to retain representative information of the documents within the learnt topic representation. In this paper, we propose a neural topic model which incorporates deep mutual information estimation, i.e., Neural Topic Modeling with Deep Mutual Information Estimation(NTM-DMIE). NTM-DMIE is a neural network method for topic learning which maximizes the mutual information between the input documents and their latent topic representation. To learn robust topic representation, we incorporate the discriminator to discriminate negative examples and positive examples via adversarial learning. Moreover, we use both global and local mutual information to preserve the rich information of the input documents in the topic representation. We evaluate NTM-DMIE on several metrics, including accuracy of text clustering, with topic representation, topic uniqueness and topic coherence. Compared to the existing methods, the experimental results show that NTM-DMIE can outperform in all the metrics on the four datasets.
Evolutionary Action Selection for Gradient-based Policy Learning
Jan 20, 2022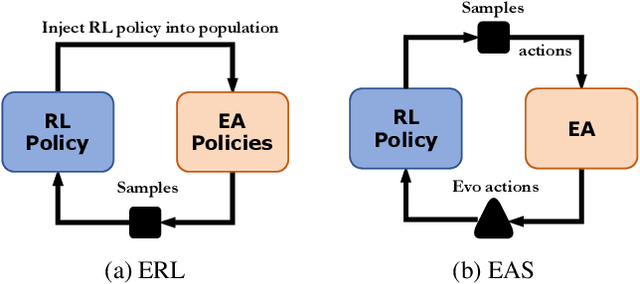
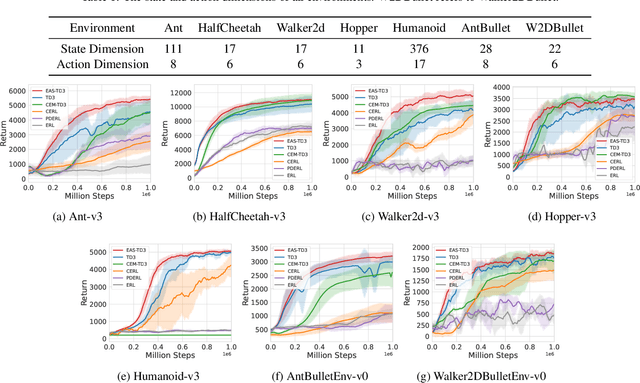
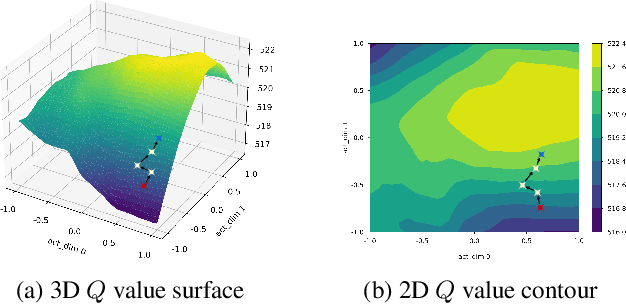
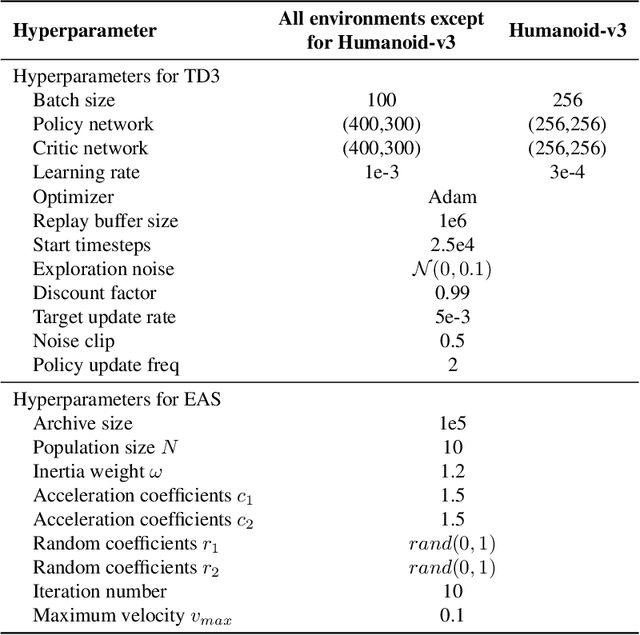
Evolutionary Algorithms (EAs) and Deep Reinforcement Learning (DRL) have recently been combined to integrate the advantages of the two solutions for better policy learning. However, in existing hybrid methods, EA is used to directly train the policy network, which will lead to sample inefficiency and unpredictable impact on the policy performance. To better integrate these two approaches and avoid the drawbacks caused by the introduction of EA, we devote ourselves to devising a more efficient and reasonable method of combining EA and DRL. In this paper, we propose Evolutionary Action Selection-Twin Delayed Deep Deterministic Policy Gradient (EAS-TD3), a novel combination of EA and DRL. In EAS, we focus on optimizing the action chosen by the policy network and attempt to obtain high-quality actions to guide policy learning through an evolutionary algorithm. We conduct several experiments on challenging continuous control tasks. The result shows that EAS-TD3 shows superior performance over other state-of-art methods.