 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA. Feder Cooper
On the Standardization of Behavioral Use Clauses and Their Adoption for Responsible Licensing of AI
Feb 07, 2024
Growing concerns over negligent or malicious uses of AI have increased the appetite for tools that help manage the risks of the technology. In 2018, licenses with behaviorial-use clauses (commonly referred to as Responsible AI Licenses) were proposed to give developers a framework for releasing AI assets while specifying their users to mitigate negative applications. As of the end of 2023, on the order of 40,000 software and model repositories have adopted responsible AI licenses licenses. Notable models licensed with behavioral use clauses include BLOOM (language) and LLaMA2 (language), Stable Diffusion (image), and GRID (robotics). This paper explores why and how these licenses have been adopted, and why and how they have been adapted to fit particular use cases. We use a mixed-methods methodology of qualitative interviews, clustering of license clauses, and quantitative analysis of license adoption. Based on this evidence we take the position that responsible AI licenses need standardization to avoid confusing users or diluting their impact. At the same time, customization of behavioral restrictions is also appropriate in some contexts (e.g., medical domains). We advocate for ``standardized customization'' that can meet users' needs and can be supported via tooling.
Scalable Extraction of Training Data from (Production) Language Models
Nov 28, 2023This paper studies extractable memorization: training data that an adversary can efficiently extract by querying a machine learning model without prior knowledge of the training dataset. We show an adversary can extract gigabytes of training data from open-source language models like Pythia or GPT-Neo, semi-open models like LLaMA or Falcon, and closed models like ChatGPT. Existing techniques from the literature suffice to attack unaligned models; in order to attack the aligned ChatGPT, we develop a new divergence attack that causes the model to diverge from its chatbot-style generations and emit training data at a rate 150x higher than when behaving properly. Our methods show practical attacks can recover far more data than previously thought, and reveal that current alignment techniques do not eliminate memorization.
CommonCanvas: An Open Diffusion Model Trained with Creative-Commons Images
Oct 25, 2023
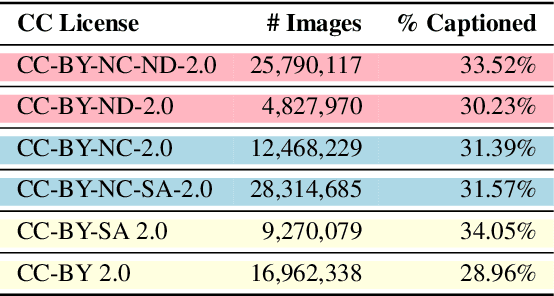


We assemble a dataset of Creative-Commons-licensed (CC) images, which we use to train a set of open diffusion models that are qualitatively competitive with Stable Diffusion 2 (SD2). This task presents two challenges: (1) high-resolution CC images lack the captions necessary to train text-to-image generative models; (2) CC images are relatively scarce. In turn, to address these challenges, we use an intuitive transfer learning technique to produce a set of high-quality synthetic captions paired with curated CC images. We then develop a data- and compute-efficient training recipe that requires as little as 3% of the LAION-2B data needed to train existing SD2 models, but obtains comparable quality. These results indicate that we have a sufficient number of CC images (~70 million) for training high-quality models. Our training recipe also implements a variety of optimizations that achieve ~3X training speed-ups, enabling rapid model iteration. We leverage this recipe to train several high-quality text-to-image models, which we dub the CommonCanvas family. Our largest model achieves comparable performance to SD2 on a human evaluation, despite being trained on our CC dataset that is significantly smaller than LAION and using synthetic captions for training. We release our models, data, and code at https://github.com/mosaicml/diffusion/blob/main/assets/common-canvas.md
Variance, Self-Consistency, and Arbitrariness in Fair Classification
Feb 01, 2023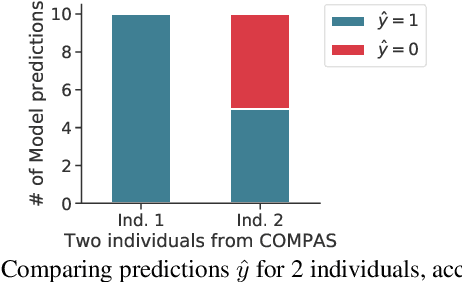
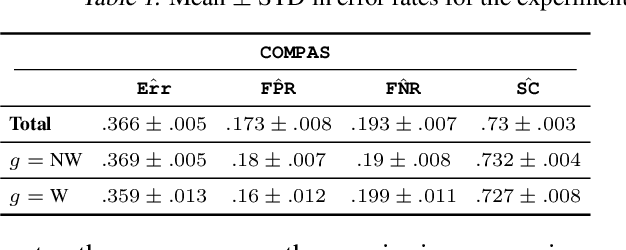
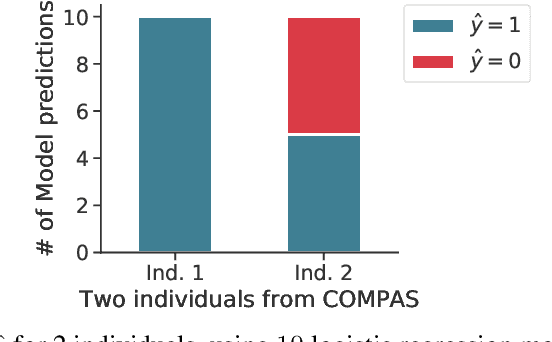
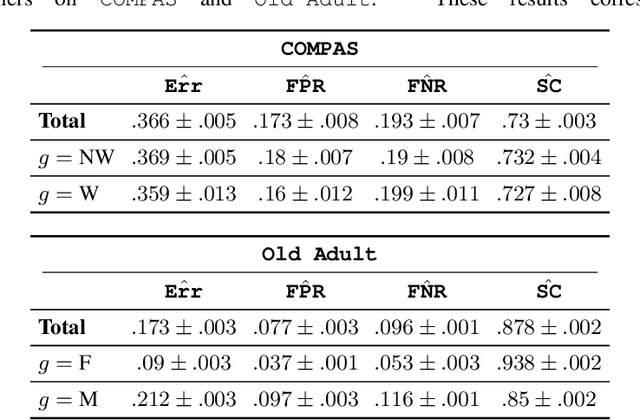
In fair classification, it is common to train a model, and to compare and correct subgroup-specific error rates for disparities. However, even if a model's classification decisions satisfy a fairness metric, it is not necessarily the case that these decisions are equally confident. This becomes clear if we measure variance: We can fix everything in the learning process except the subset of training data, train multiple models, measure (dis)agreement in predictions for each test example, and interpret disagreement to mean that the learning process is more unstable with respect to its classification decision. Empirically, some decisions can in fact be so unstable that they are effectively arbitrary. To reduce this arbitrariness, we formalize a notion of self-consistency of a learning process, develop an ensembling algorithm that provably increases self-consistency, and empirically demonstrate its utility to often improve both fairness and accuracy. Further, our evaluation reveals a startling observation: Applying ensembling to common fair classification benchmarks can significantly reduce subgroup error rate disparities, without employing common pre-, in-, or post-processing fairness interventions. Taken together, our results indicate that variance, particularly on small datasets, can muddle the reliability of conclusions about fairness. One solution is to develop larger benchmark tasks. To this end, we release a toolkit that makes the Home Mortgage Disclosure Act datasets easily usable for future research.
Non-Determinism and the Lawlessness of ML Code
Jun 23, 2022

Legal literature on machine learning (ML) tends to focus on harms, and as a result tends to reason about individual model outcomes and summary error rates. This focus on model-level outcomes and errors has masked important aspects of ML that are rooted in its inherent non-determinism. We show that the effects of non-determinism, and consequently its implications for the law, instead become clearer from the perspective of reasoning about ML outputs as probability distributions over possible outcomes. This distributional viewpoint accounts for non-determinism by emphasizing the possible outcomes of ML. Importantly, this type of reasoning is not exclusive with current legal reasoning; it complements (and in fact can strengthen) analyses concerning individual, concrete outcomes for specific automated decisions. By clarifying the important role of non-determinism, we demonstrate that ML code falls outside of the cyberlaw frame of treating "code as law," as this frame assumes that code is deterministic. We conclude with a brief discussion of what work ML can do to constrain the potentially harm-inducing effects of non-determinism, and we clarify where the law must do work to bridge the gap between its current individual-outcome focus and the distributional approach that we recommend.
Accountability in an Algorithmic Society: Relationality, Responsibility, and Robustness in Machine Learning
Feb 23, 2022In 1996, philosopher Helen Nissenbaum issued a clarion call concerning the erosion of accountability in society due to the ubiquitous delegation of consequential functions to computerized systems. Using the conceptual framing of moral blame, Nissenbaum described four types of barriers to accountability that computerization presented: 1) "many hands," the problem of attributing moral responsibility for outcomes caused by many moral actors; 2) "bugs," a way software developers might shrug off responsibility by suggesting software errors are unavoidable; 3) "computer as scapegoat," shifting blame to computer systems as if they were moral actors; and 4) "ownership without liability," a free pass to the tech industry to deny responsibility for the software they produce. We revisit these four barriers in relation to the recent ascendance of data-driven algorithmic systems--technology often folded under the heading of machine learning (ML) or artificial intelligence (AI)--to uncover the new challenges for accountability that these systems present. We then look ahead to how one might construct and justify a moral, relational framework for holding responsible parties accountable, and argue that the FAccT community is uniquely well-positioned to develop such a framework to weaken the four barriers.
Tecnologica cosa: Modeling Storyteller Personalities in Boccaccio's Decameron
Sep 22, 2021



We explore Boccaccio's Decameron to see how digital humanities tools can be used for tasks that have limited data in a language no longer in contemporary use: medieval Italian. We focus our analysis on the question: Do the different storytellers in the text exhibit distinct personalities? To answer this question, we curate and release a dataset based on the authoritative edition of the text. We use supervised classification methods to predict storytellers based on the stories they tell, confirming the difficulty of the task, and demonstrate that topic modeling can extract thematic storyteller "profiles."
Model Selection's Disparate Impact in Real-World Deep Learning Applications
Apr 01, 2021


Algorithmic fairness has emphasized the role of biased data in automated decision outcomes. Recently, there has been a shift in attention to sources of bias that implicate fairness in other stages in the ML pipeline. We contend that one source of such bias, human preferences in model selection, remains under-explored in terms of its role in disparate impact across demographic groups. Using a deep learning model trained on real-world medical imaging data, we verify our claim empirically and argue that choice of metric for model comparison can significantly bias model selection outcomes.
Hyperparameter Optimization Is Deceiving Us, and How to Stop It
Feb 10, 2021



While hyperparameter optimization (HPO) is known to greatly impact learning algorithm performance, it is often treated as an empirical afterthought. Recent empirical works have highlighted the risk of this second-rate treatment of HPO. They show that inconsistent performance results, based on choice of hyperparameter subspace to search, are a widespread problem in ML research. When comparing two algorithms, J and K searching one subspace can yield the conclusion that J outperforms K, whereas searching another can entail the opposite result. In short, your choice of hyperparameters can deceive you. We provide a theoretical complement to this prior work: We analytically characterize this problem, which we term hyperparameter deception, and show that grid search is inherently deceptive. We prove a defense with guarantees against deception, and demonstrate a defense in practice.
Where Is the Normative Proof? Assumptions and Contradictions in ML Fairness Research
Nov 03, 2020Across machine learning (ML) sub-disciplines researchers make mathematical assumptions to facilitate proof-writing. While such assumptions are necessary for providing mathematical guarantees for how algorithms behave, they also necessarily limit the applicability of these algorithms to different problem settings. This practice is known--in fact, obvious--and accepted in ML research. However, similar attention is not paid to the normative assumptions that ground this work. I argue such assumptions are equally as important, especially in areas of ML with clear social impact, such as fairness. This is because, similar to how mathematical assumptions constrain applicability, normative assumptions also limit algorithm applicability to certain problem domains. I show that, in existing papers published in top venues, once normative assumptions are clarified, it is often possible to get unclear or contradictory results. While the mathematical assumptions and results are sound, the implicit normative assumptions and accompanying normative results contraindicate using these methods in practical fairness applications.