 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAaron Walsman
ENTL: Embodied Navigation Trajectory Learner
Apr 07, 2023


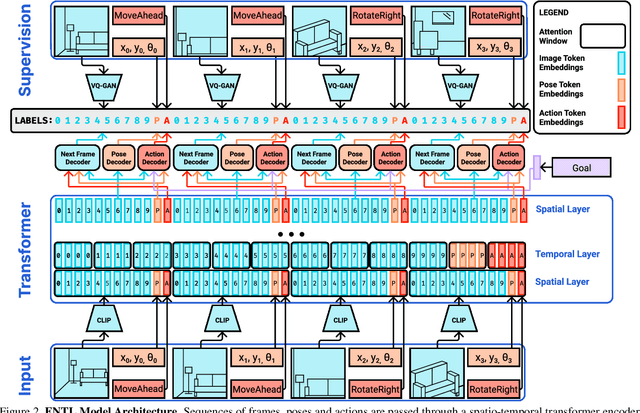

We propose Embodied Navigation Trajectory Learner (ENTL), a method for extracting long sequence representations for embodied navigation. Our approach unifies world modeling, localization and imitation learning into a single sequence prediction task. We train our model using vector-quantized predictions of future states conditioned on current states and actions. ENTL's generic architecture enables sharing of the spatio-temporal sequence encoder for multiple challenging embodied tasks. We achieve competitive performance on navigation tasks using significantly less data than strong baselines while performing auxiliary tasks such as localization and future frame prediction (a proxy for world modeling). A key property of our approach is that the model is pre-trained without any explicit reward signal, which makes the resulting model generalizable to multiple tasks and environments.
Break and Make: Interactive Structural Understanding Using LEGO Bricks
Jul 27, 2022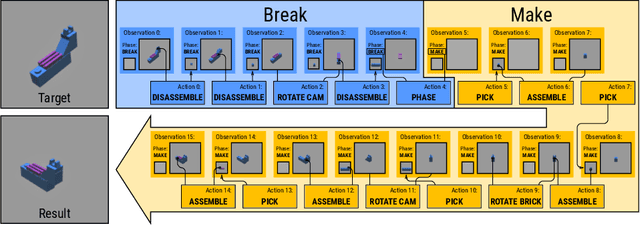
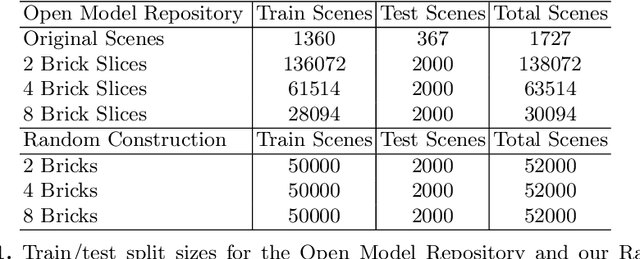
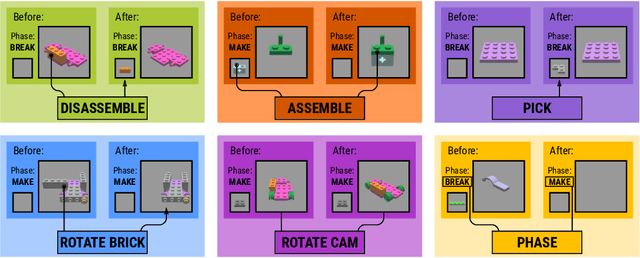

Visual understanding of geometric structures with complex spatial relationships is a fundamental component of human intelligence. As children, we learn how to reason about structure not only from observation, but also by interacting with the world around us -- by taking things apart and putting them back together again. The ability to reason about structure and compositionality allows us to not only build things, but also understand and reverse-engineer complex systems. In order to advance research in interactive reasoning for part-based geometric understanding, we propose a challenging new assembly problem using LEGO bricks that we call Break and Make. In this problem an agent is given a LEGO model and attempts to understand its structure by interactively inspecting and disassembling it. After this inspection period, the agent must then prove its understanding by rebuilding the model from scratch using low-level action primitives. In order to facilitate research on this problem we have built LTRON, a fully interactive 3D simulator that allows learning agents to assemble, disassemble and manipulate LEGO models. We pair this simulator with a new dataset of fan-made LEGO creations that have been uploaded to the internet in order to provide complex scenes containing over a thousand unique brick shapes. We take a first step towards solving this problem using sequence-to-sequence models that provide guidance for how to make progress on this challenging problem. Our simulator and data are available at github.com/aaronwalsman/ltron. Additional training code and PyTorch examples are available at github.com/aaronwalsman/ltron-torch-eccv22.
Amodal 3D Reconstruction for Robotic Manipulation via Stability and Connectivity
Sep 28, 2020



Learning-based 3D object reconstruction enables single- or few-shot estimation of 3D object models. For robotics, this holds the potential to allow model-based methods to rapidly adapt to novel objects and scenes. Existing 3D reconstruction techniques optimize for visual reconstruction fidelity, typically measured by chamfer distance or voxel IOU. We find that when applied to realistic, cluttered robotics environments, these systems produce reconstructions with low physical realism, resulting in poor task performance when used for model-based control. We propose ARM, an amodal 3D reconstruction system that introduces (1) a stability prior over object shapes, (2) a connectivity prior, and (3) a multi-channel input representation that allows for reasoning over relationships between groups of objects. By using these priors over the physical properties of objects, our system improves reconstruction quality not just by standard visual metrics, but also performance of model-based control on a variety of robotics manipulation tasks in challenging, cluttered environments. Code is available at github.com/wagnew3/ARM.
In the Wild: From ML Models to Pragmatic ML Systems
Jul 06, 2020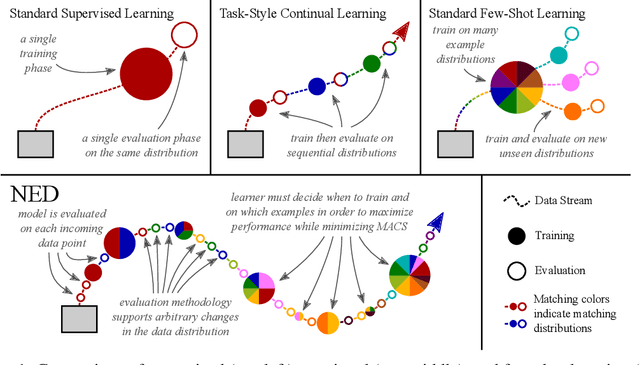
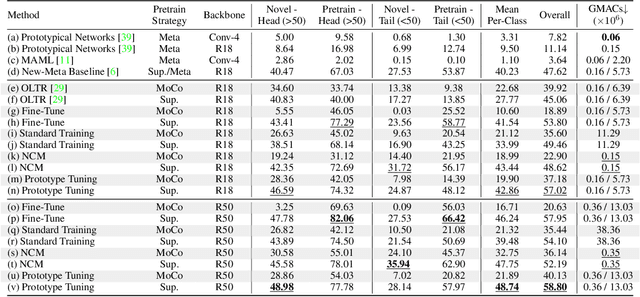
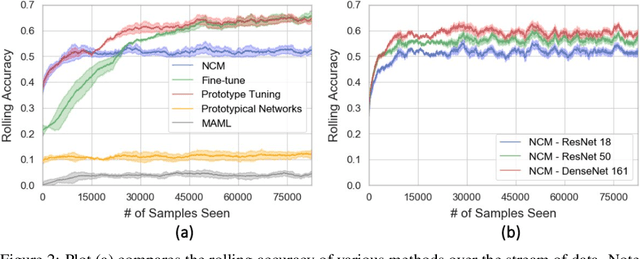

Enabling robust intelligence in the wild entails learning systems that offer uninterrupted inference while affording sustained training, with varying amounts of data & supervision. Such a pragmatic ML system should be able to cope with the openness & flexibility inherent in the real world. The machine learning community has organically broken down this challenging task into manageable sub tasks such as supervised, few-shot, continual, & self-supervised learning; each affording distinctive challenges & leading to a unique set of methods. Notwithstanding this amazing progress, the restricted & isolated nature of these tasks has resulted in methods that excel in one setting, but struggle to extend beyond them. To foster the research required to extend ML models to ML systems, we introduce a unified learning & evaluation framework - iN thE wilD (NED). NED is designed to be a more general paradigm by loosening the restrictive design decisions of past settings (e.g. closed-world assumption) & imposing fewer restrictions on learning algorithms (e.g. predefined train & test phases). The learners can infer the experimental parameters themselves by optimizing for both accuracy & compute. In NED, a learner receives a stream of data & makes sequential predictions while choosing how to update itself, adapt to data from novel categories, & deal with changing data distributions; while optimizing the total amount of compute. We evaluate a large set of existing methods across several sub fields using NED & present surprising yet revealing findings about modern day techniques. For instance, prominent few shot methods break down in NED, achieving dramatic drops of over 40% accuracy relative to simple baselines; & the SOTA self-supervised methods Momentum Contrast obtains 35% lower accuracy than supervised pretraining on novel classes. We also show that a simple baseline outperforms existing methods on NED.
Part Segmentation for Highly Accurate Deformable Tracking in Occlusions via Fully Convolutional Neural Networks
Aug 05, 2019



Successfully tracking the human body is an important perceptual challenge for robots that must work around people. Existing methods fall into two broad categories: geometric tracking and direct pose estimation using machine learning. While recent work has shown direct estimation techniques can be quite powerful, geometric tracking methods using point clouds can provide a very high level of 3D accuracy which is necessary for many robotic applications. However these approaches can have difficulty in clutter when large portions of the subject are occluded. To overcome this limitation, we propose a solution based on fully convolutional neural networks (FCN). We develop an optimized Fast-FCN network architecture for our application which allows us to filter observed point clouds and improve tracking accuracy while maintaining interactive frame rates. We also show that this model can be trained with a limited number of examples and almost no manual labelling by using an existing geometric tracker and data augmentation to automatically generate segmentation maps. We demonstrate the accuracy of our full system by comparing it against an existing geometric tracker, and show significant improvement in these challenging scenarios.
Early Fusion for Goal Directed Robotic Vision
Nov 21, 2018



Increasingly, perceptual systems are being codified as strict pipelines wherein vision is treated as a pre-processing step to provide a dense representation of the scene to planners for high level reasoning downstream. Problematically, this paradigm forces models to represent nearly every aspect of the scene even if it has no bearing on the task at hand. In this work, we flip this paradigm, by introducing vision models whose feature representations are conditioned on embedded representations of the agent's goal. This allows the model to build scene descriptions that are specifically designed to help achieve that goal. We find this leads to models that learn faster, are substantially more parameter efficient and more robust than existing attention mechanisms in our domain. Our experiments are performed on a simulated robot item retrieval problem and trained in a fully end-to-end manner via imitation learning.
CHALET: Cornell House Agent Learning Environment
Jan 23, 2018



We present CHALET, a 3D house simulator with support for navigation and manipulation. CHALET includes 58 rooms and 10 house configuration, and allows to easily create new house and room layouts. CHALET supports a range of common household activities, including moving objects, toggling appliances, and placing objects inside closeable containers. The environment and actions available are designed to create a challenging domain to train and evaluate autonomous agents, including for tasks that combine language, vision, and planning in a dynamic environment.
Dynamic High Resolution Deformable Articulated Tracking
Nov 21, 2017



The last several years have seen significant progress in using depth cameras for tracking articulated objects such as human bodies, hands, and robotic manipulators. Most approaches focus on tracking skeletal parameters of a fixed shape model, which makes them insufficient for applications that require accurate estimates of deformable object surfaces. To overcome this limitation, we present a 3D model-based tracking system for articulated deformable objects. Our system is able to track human body pose and high resolution surface contours in real time using a commodity depth sensor and GPU hardware. We implement this as a joint optimization over a skeleton to account for changes in pose, and over the vertices of a high resolution mesh to track the subject's shape. Through experimental results we show that we are able to capture dynamic sub-centimeter surface detail such as folds and wrinkles in clothing. We also show that this shape estimation aids kinematic pose estimation by providing a more accurate target to match against the point cloud. The end result is highly accurate spatiotemporal and semantic information which is well suited for physical human robot interaction as well as virtual and augmented reality systems.
Benchmarking in Manipulation Research: The YCB Object and Model Set and Benchmarking Protocols
Feb 10, 2015



In this paper we present the Yale-CMU-Berkeley (YCB) Object and Model set, intended to be used to facilitate benchmarking in robotic manipulation, prosthetic design and rehabilitation research. The objects in the set are designed to cover a wide range of aspects of the manipulation problem; it includes objects of daily life with different shapes, sizes, textures, weight and rigidity, as well as some widely used manipulation tests. The associated database provides high-resolution RGBD scans, physical properties, and geometric models of the objects for easy incorporation into manipulation and planning software platforms. In addition to describing the objects and models in the set along with how they were chosen and derived, we provide a framework and a number of example task protocols, laying out how the set can be used to quantitatively evaluate a range of manipulation approaches including planning, learning, mechanical design, control, and many others. A comprehensive literature survey on existing benchmarks and object datasets is also presented and their scope and limitations are discussed. The set will be freely distributed to research groups worldwide at a series of tutorials at robotics conferences, and will be otherwise available at a reasonable purchase cost. It is our hope that the ready availability of this set along with the ground laid in terms of protocol templates will enable the community of manipulation researchers to more easily compare approaches as well as continually evolve benchmarking tests as the field matures.
* Submitted to Robotics and Automation Magazine (RAM) Special Issue on Replicable and Measurable Robotics Research. 35 Pages