 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAasheesh Barvey
Proactive Intervention to Downtrend Employee Attrition using Artificial Intelligence Techniques
Jul 11, 2018
To predict the employee attrition beforehand and to enable management to take individualized preventive action. Using Ensemble classification modeling techniques and Linear Regression. Model could predict over 91% accurate employee prediction, lead-time in separation and individual reasons causing attrition. Prior intimation of employee attrition enables manager to take preventive actions to retain employee or to manage the business consequences of attrition. Once deployed this will model can help in downtrend Employee Attrition, will help manager to manage team more effectively. Model does not cover the natural calamities, and unforeseen events occurring at an individual level like accident, death etc.
Personalized Influence Estimation Technique
May 25, 2018
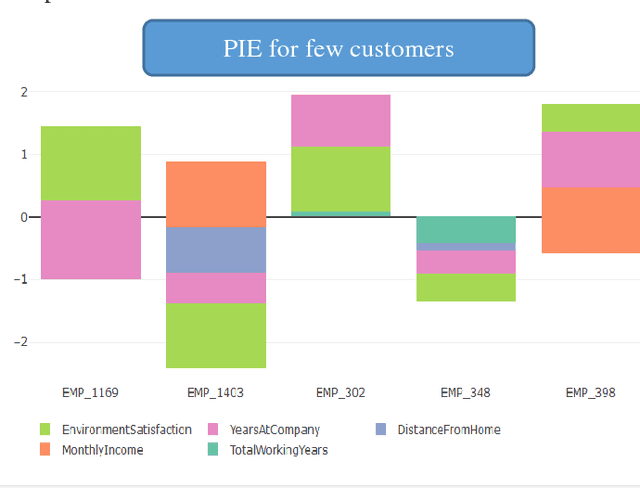
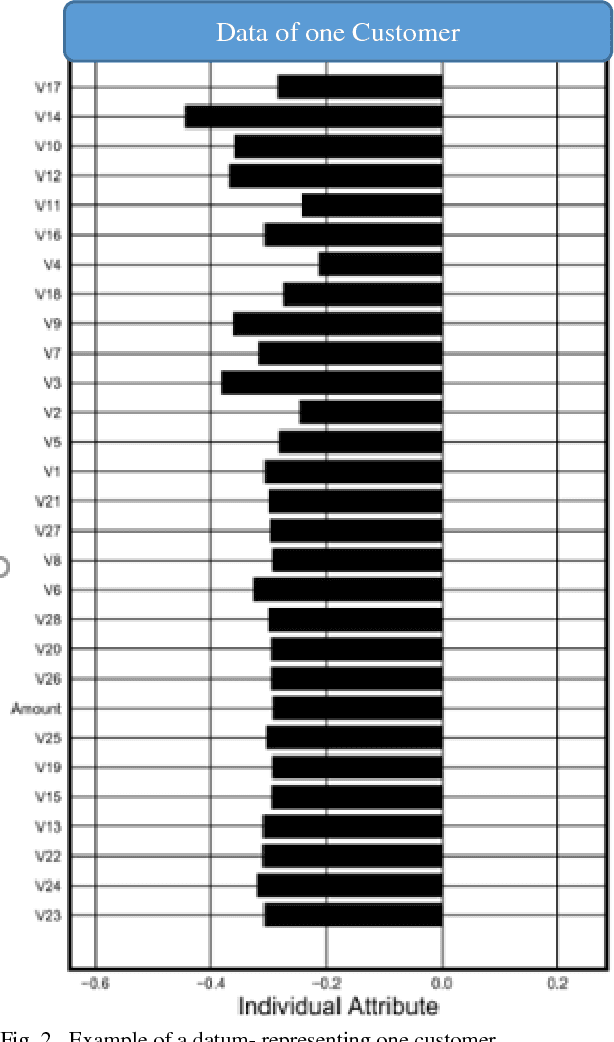
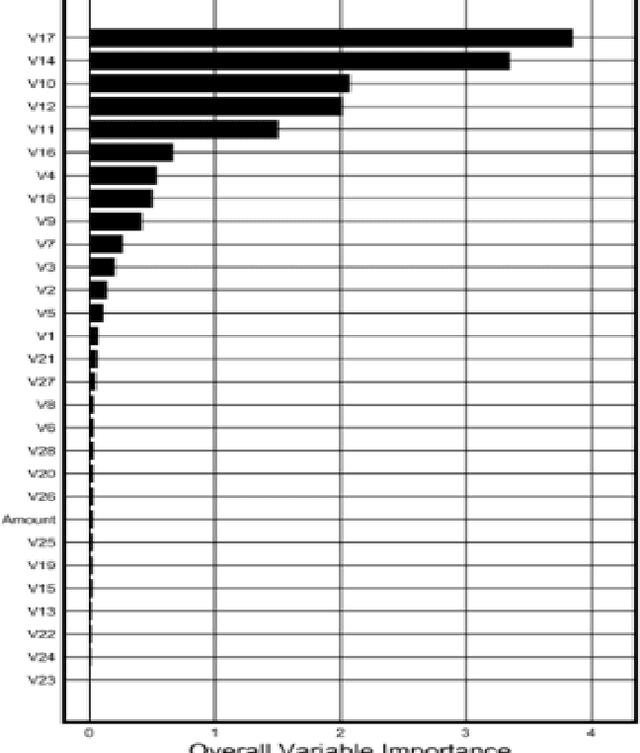
Customer Satisfaction is the most important factors in the industry irrespective of domain. Key Driver Analysis is a common practice in data science to help the business to evaluate the same. Understanding key features, which influence the outcome or dependent feature, is highly important in statistical model building. This helps to eliminate not so important factors from the model to minimize noise coming from the features, which does not contribute significantly enough to explain the behavior of the dependent feature, which we want to predict. Personalized Influence Estimation is a technique introduced in this paper, which can estimate key factor influence for individual observations, which contribute most for each observations behavior pattern based on the dependent class or estimate. Observations can come from multiple business problem i.e. customers related to satisfaction study, customer related to Fraud Detection, network devices for Fault detection etc. It is highly important to understand the cause of issue at each observation level to take appropriate Individualized action at customer level or device level etc. This technique is based on joint behavior of the feature dimension for the specific observation, and relative importance of the feature to estimate impact. The technique mentioned in this paper is aimed to help organizations to understand each respondents or observations individual key contributing factor of Influence. Result of the experiment is really encouraging and able to justify key reasons for churn for majority of the sample appropriately
Futuristic Classification with Dynamic Reference Frame Strategy
May 25, 2018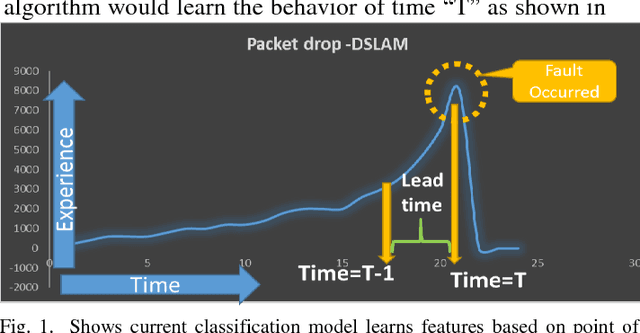
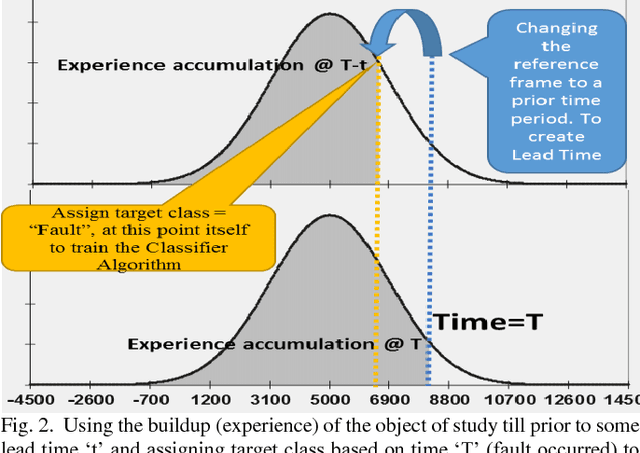
Classification is one of the widely used analytical techniques in data science domain across different business to associate a pattern which contribute to the occurrence of certain event which is predicted with some likelihood. This Paper address a lacuna of creating some time window before the prediction actually happen to enable organizations some space to act on the prediction. There are some really good state of the art machine learning techniques to optimally identify the possible churners in either customer base or employee base, similarly for fault prediction too if the prediction does not come with some buffer time to act on the fault it is very difficult to provide a seamless experience to the user. New concept of reference frame creation is introduced to solve this problem in this paper
Distribution Assertive Regression
May 04, 2018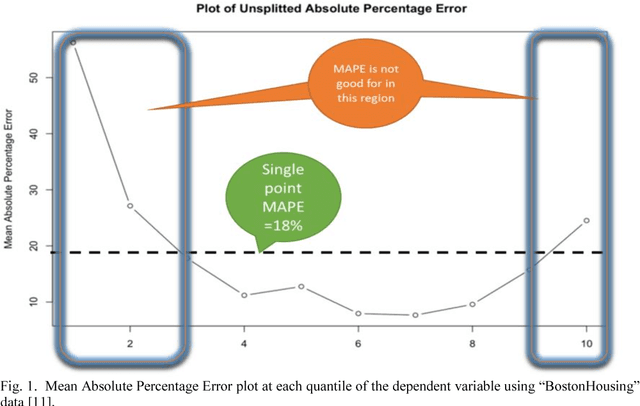

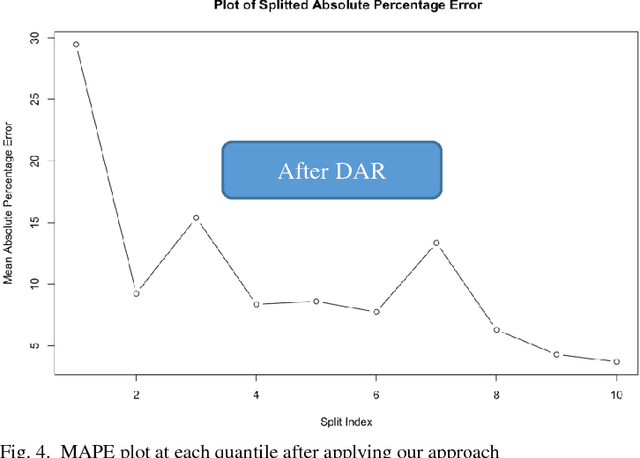
In regression modelling approach, the main step is to fit the regression line as close as possible to the target variable. In this process most algorithms try to fit all of the data in a single line and hence fitting all parts of target variable in one go. It was observed that the error between predicted and target variable usually have a varying behavior across the various quantiles of the dependent variable and hence single point diagnostic like MAPE has its limitation to signify the level of fitness across the distribution of Y(dependent variable). To address this problem, a novel approach is proposed in the paper to deal with regression fitting over various quantiles of target variable. Using this approach we have significantly improved the eccentric behavior of the distance (error) between predicted and actual value of regression. Our proposed solution is based on understanding the segmented behavior of the data with respect to the internal segments within the data and approach for retrospectively fitting the data based on each quantile behavior. We believe exploring and using this approach would help in achieving better and more explainable results in most settings of real world data modelling problems.