 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNikit Gawande
Incremental Learning Framework Using Cloud Computing
May 12, 2018
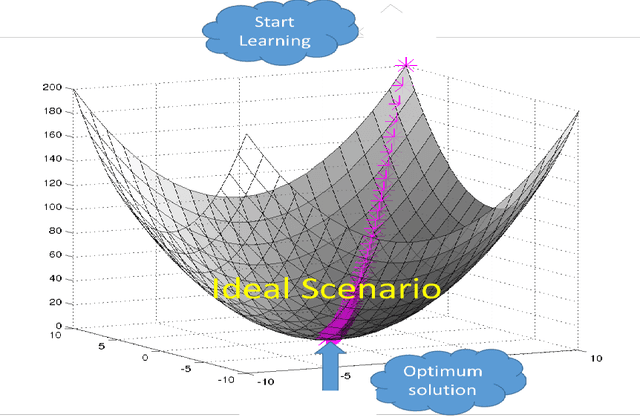
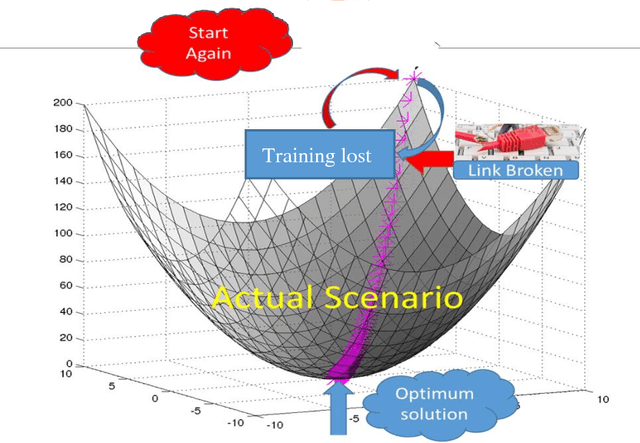

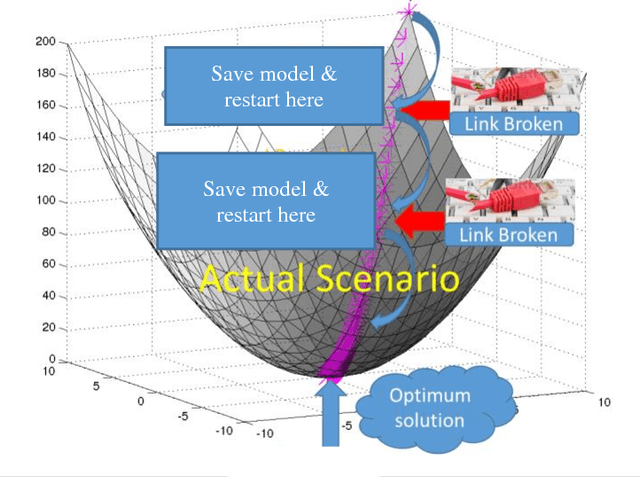
High volume of data, perceived as either challenge or opportunity. Deep learning architecture demands high volume of data to effectively back propagate and train the weights without bias. At the same time, large volume of data demands higher capacity of the machine where it could be executed seamlessly. Budding data scientist along with many research professionals face frequent disconnection issue with cloud computing framework (working without dedicated connection) due to free subscription to the platform. Similar issues also visible while working on local computer where computer may run out of resource or power sometimes and researcher has to start training the models all over again. In this paper, we intend to provide a way to resolve this issue and progressively training the neural network even after having frequent disconnection or resource outage without loosing much of the progress
Distribution Assertive Regression
May 04, 2018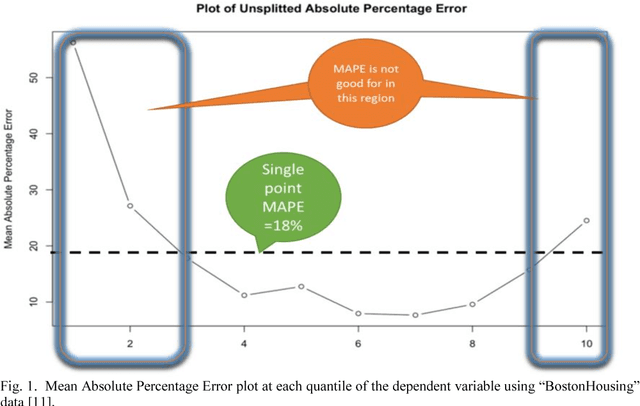

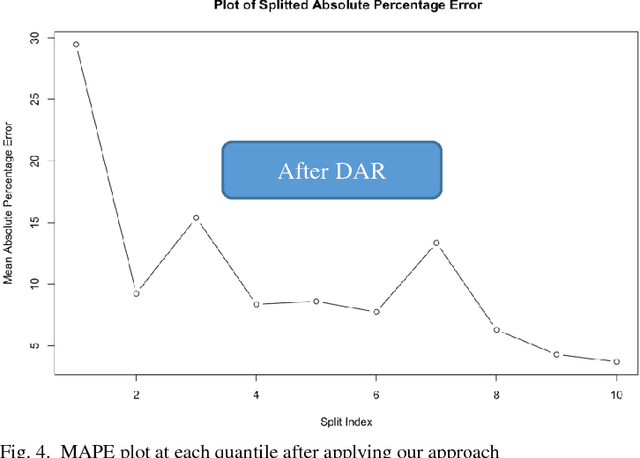
In regression modelling approach, the main step is to fit the regression line as close as possible to the target variable. In this process most algorithms try to fit all of the data in a single line and hence fitting all parts of target variable in one go. It was observed that the error between predicted and target variable usually have a varying behavior across the various quantiles of the dependent variable and hence single point diagnostic like MAPE has its limitation to signify the level of fitness across the distribution of Y(dependent variable). To address this problem, a novel approach is proposed in the paper to deal with regression fitting over various quantiles of target variable. Using this approach we have significantly improved the eccentric behavior of the distance (error) between predicted and actual value of regression. Our proposed solution is based on understanding the segmented behavior of the data with respect to the internal segments within the data and approach for retrospectively fitting the data based on each quantile behavior. We believe exploring and using this approach would help in achieving better and more explainable results in most settings of real world data modelling problems.