 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbbas Ghaddar
On the importance of Data Scale in Pretraining Arabic Language Models
Jan 15, 2024
Pretraining monolingual language models have been proven to be vital for performance in Arabic Natural Language Processing (NLP) tasks. In this paper, we conduct a comprehensive study on the role of data in Arabic Pretrained Language Models (PLMs). More precisely, we reassess the performance of a suite of state-of-the-art Arabic PLMs by retraining them on massive-scale, high-quality Arabic corpora. We have significantly improved the performance of the leading Arabic encoder-only BERT-base and encoder-decoder T5-base models on the ALUE and ORCA leaderboards, thereby reporting state-of-the-art results in their respective model categories. In addition, our analysis strongly suggests that pretraining data by far is the primary contributor to performance, surpassing other factors. Our models and source code are publicly available at https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/JABER-PyTorch.
AraMUS: Pushing the Limits of Data and Model Scale for Arabic Natural Language Processing
Jun 11, 2023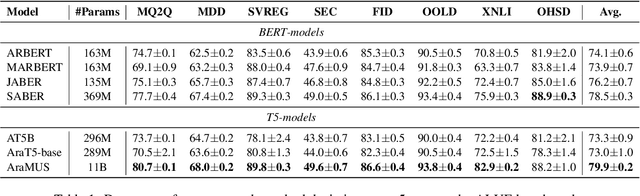
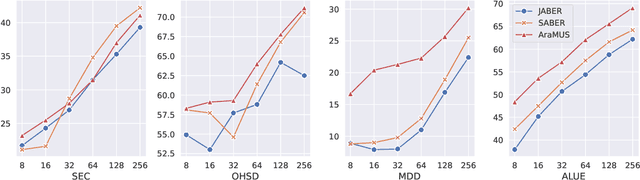
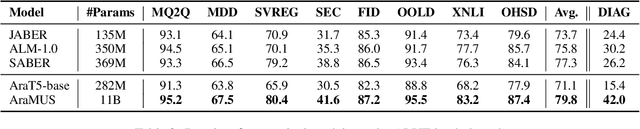

Developing monolingual large Pre-trained Language Models (PLMs) is shown to be very successful in handling different tasks in Natural Language Processing (NLP). In this work, we present AraMUS, the largest Arabic PLM with 11B parameters trained on 529GB of high-quality Arabic textual data. AraMUS achieves state-of-the-art performances on a diverse set of Arabic classification and generative tasks. Moreover, AraMUS shows impressive few-shot learning abilities compared with the best existing Arabic PLMs.
Revisiting Pre-trained Language Models and their Evaluation for Arabic Natural Language Understanding
May 21, 2022
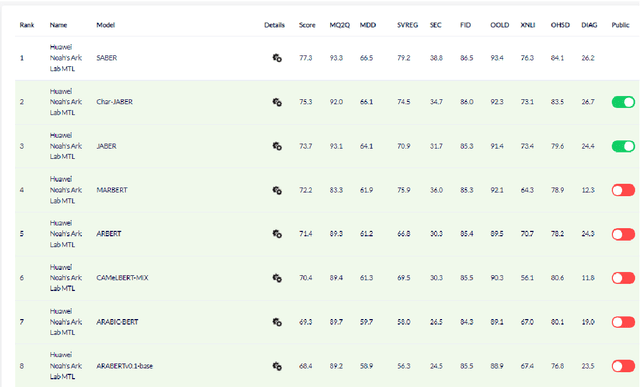
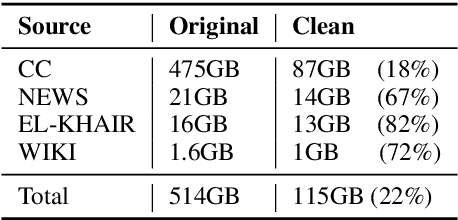
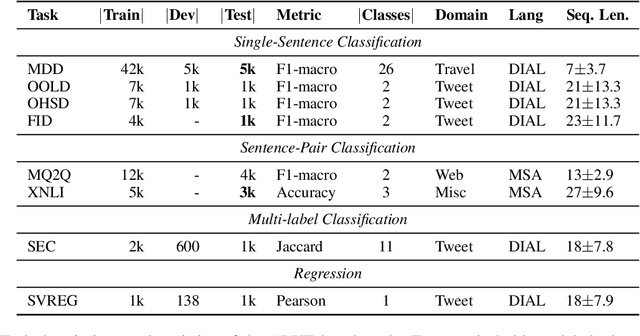
There is a growing body of work in recent years to develop pre-trained language models (PLMs) for the Arabic language. This work concerns addressing two major problems in existing Arabic PLMs which constraint progress of the Arabic NLU and NLG fields.First, existing Arabic PLMs are not well-explored and their pre-trainig can be improved significantly using a more methodical approach. Second, there is a lack of systematic and reproducible evaluation of these models in the literature. In this work, we revisit both the pre-training and evaluation of Arabic PLMs. In terms of pre-training, we explore improving Arabic LMs from three perspectives: quality of the pre-training data, size of the model, and incorporating character-level information. As a result, we release three new Arabic BERT-style models ( JABER, Char-JABER, and SABER), and two T5-style models (AT5S and AT5B). In terms of evaluation, we conduct a comprehensive empirical study to systematically evaluate the performance of existing state-of-the-art models on ALUE that is a leaderboard-powered benchmark for Arabic NLU tasks, and on a subset of the ARGEN benchmark for Arabic NLG tasks. We show that our models significantly outperform existing Arabic PLMs and achieve a new state-of-the-art performance on discriminative and generative Arabic NLU and NLG tasks. Our models and source code to reproduce of results will be made available shortly.
CILDA: Contrastive Data Augmentation using Intermediate Layer Knowledge Distillation
Apr 15, 2022



Knowledge distillation (KD) is an efficient framework for compressing large-scale pre-trained language models. Recent years have seen a surge of research aiming to improve KD by leveraging Contrastive Learning, Intermediate Layer Distillation, Data Augmentation, and Adversarial Training. In this work, we propose a learning based data augmentation technique tailored for knowledge distillation, called CILDA. To the best of our knowledge, this is the first time that intermediate layer representations of the main task are used in improving the quality of augmented samples. More precisely, we introduce an augmentation technique for KD based on intermediate layer matching using contrastive loss to improve masked adversarial data augmentation. CILDA outperforms existing state-of-the-art KD approaches on the GLUE benchmark, as well as in an out-of-domain evaluation.
JABER and SABER: Junior and Senior Arabic BERt
Jan 09, 2022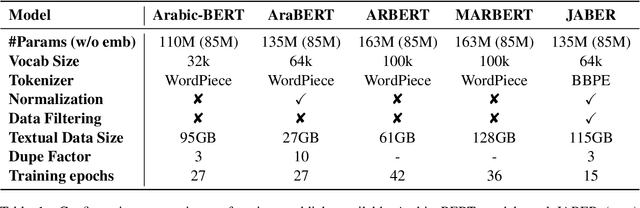
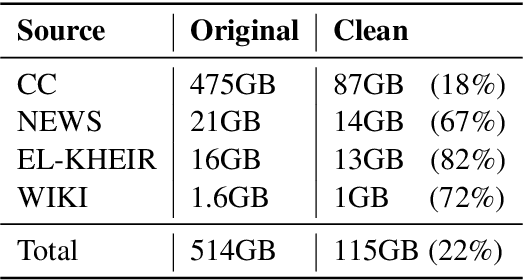
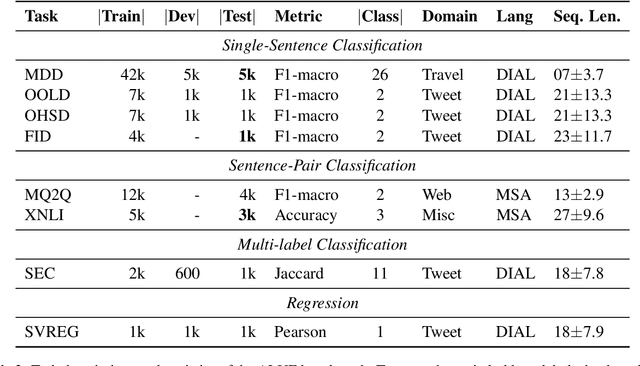
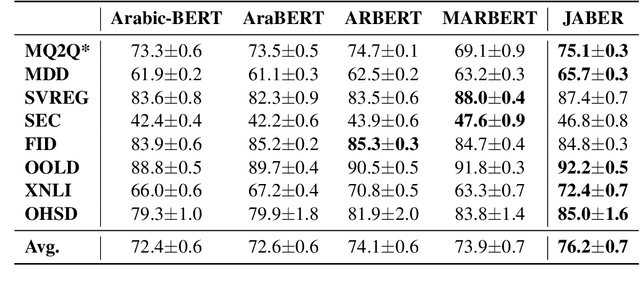
Language-specific pre-trained models have proven to be more accurate than multilingual ones in a monolingual evaluation setting, Arabic is no exception. However, we found that previously released Arabic BERT models were significantly under-trained. In this technical report, we present JABER and SABER, Junior and Senior Arabic BERt respectively, our pre-trained language model prototypes dedicated for Arabic. We conduct an empirical study to systematically evaluate the performance of models across a diverse set of existing Arabic NLU tasks. Experimental results show that JABER and SABER achieve state-of-the-art performances on ALUE, a new benchmark for Arabic Language Understanding Evaluation, as well as on a well-established NER benchmark.
NATURE: Natural Auxiliary Text Utterances for Realistic Spoken Language Evaluation
Nov 09, 2021



Slot-filling and intent detection are the backbone of conversational agents such as voice assistants, and are active areas of research. Even though state-of-the-art techniques on publicly available benchmarks show impressive performance, their ability to generalize to realistic scenarios is yet to be demonstrated. In this work, we present NATURE, a set of simple spoken-language oriented transformations, applied to the evaluation set of datasets, to introduce human spoken language variations while preserving the semantics of an utterance. We apply NATURE to common slot-filling and intent detection benchmarks and demonstrate that simple perturbations from the standard evaluation set by NATURE can deteriorate model performance significantly. Through our experiments we demonstrate that when NATURE operators are applied to evaluation set of popular benchmarks the model accuracy can drop by up to 40%.
RAIL-KD: RAndom Intermediate Layer Mapping for Knowledge Distillation
Oct 01, 2021



Intermediate layer knowledge distillation (KD) can improve the standard KD technique (which only targets the output of teacher and student models) especially over large pre-trained language models. However, intermediate layer distillation suffers from excessive computational burdens and engineering efforts required for setting up a proper layer mapping. To address these problems, we propose a RAndom Intermediate Layer Knowledge Distillation (RAIL-KD) approach in which, intermediate layers from the teacher model are selected randomly to be distilled into the intermediate layers of the student model. This randomized selection enforce that: all teacher layers are taken into account in the training process, while reducing the computational cost of intermediate layer distillation. Also, we show that it act as a regularizer for improving the generalizability of the student model. We perform extensive experiments on GLUE tasks as well as on out-of-domain test sets. We show that our proposed RAIL-KD approach outperforms other state-of-the-art intermediate layer KD methods considerably in both performance and training-time.
Knowledge Distillation with Noisy Labels for Natural Language Understanding
Sep 21, 2021


Knowledge Distillation (KD) is extensively used to compress and deploy large pre-trained language models on edge devices for real-world applications. However, one neglected area of research is the impact of noisy (corrupted) labels on KD. We present, to the best of our knowledge, the first study on KD with noisy labels in Natural Language Understanding (NLU). We document the scope of the problem and present two methods to mitigate the impact of label noise. Experiments on the GLUE benchmark show that our methods are effective even under high noise levels. Nevertheless, our results indicate that more research is necessary to cope with label noise under the KD.
End-to-End Self-Debiasing Framework for Robust NLU Training
Sep 05, 2021


Existing Natural Language Understanding (NLU) models have been shown to incorporate dataset biases leading to strong performance on in-distribution (ID) test sets but poor performance on out-of-distribution (OOD) ones. We introduce a simple yet effective debiasing framework whereby the shallow representations of the main model are used to derive a bias model and both models are trained simultaneously. We demonstrate on three well studied NLU tasks that despite its simplicity, our method leads to competitive OOD results. It significantly outperforms other debiasing approaches on two tasks, while still delivering high in-distribution performance.
* Findings ACL 2021
Context-aware Adversarial Training for Name Regularity Bias in Named Entity Recognition
Jul 24, 2021In this work, we examine the ability of NER models to use contextual information when predicting the type of an ambiguous entity. We introduce NRB, a new testbed carefully designed to diagnose Name Regularity Bias of NER models. Our results indicate that all state-of-the-art models we tested show such a bias; BERT fine-tuned models significantly outperforming feature-based (LSTM-CRF) ones on NRB, despite having comparable (sometimes lower) performance on standard benchmarks. To mitigate this bias, we propose a novel model-agnostic training method that adds learnable adversarial noise to some entity mentions, thus enforcing models to focus more strongly on the contextual signal, leading to significant gains on NRB. Combining it with two other training strategies, data augmentation and parameter freezing, leads to further gains.
* MIT Press\TACL 2021\Presented at ACL 2021 This is the exact same content of the TACL version, except the figures and tables are better aligned