 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAhmad Rashid
Preventing Arbitrarily High Confidence on Far-Away Data in Point-Estimated Discriminative Neural Networks
Nov 07, 2023
Discriminatively trained, deterministic neural networks are the de facto choice for classification problems. However, even though they achieve state-of-the-art results on in-domain test sets, they tend to be overconfident on out-of-distribution (OOD) data. For instance, ReLU networks -- a popular class of neural network architectures -- have been shown to almost always yield high confidence predictions when the test data are far away from the training set, even when they are trained with OOD data. We overcome this problem by adding a term to the output of the neural network that corresponds to the logit of an extra class, that we design to dominate the logits of the original classes as we move away from the training data.This technique provably prevents arbitrarily high confidence on far-away test data while maintaining a simple discriminative point-estimate training. Evaluation on various benchmarks demonstrates strong performance against competitive baselines on both far-away and realistic OOD data.
Attribute Controlled Dialogue Prompting
Jul 11, 2023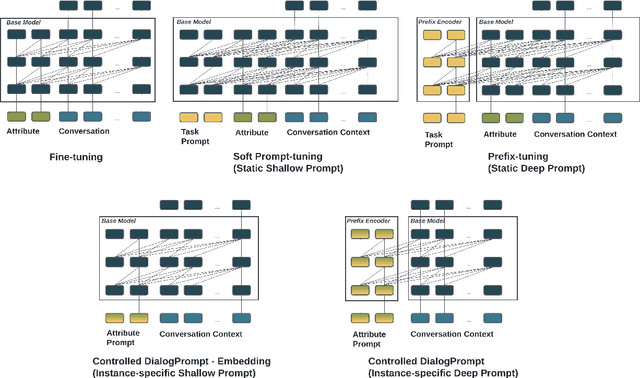


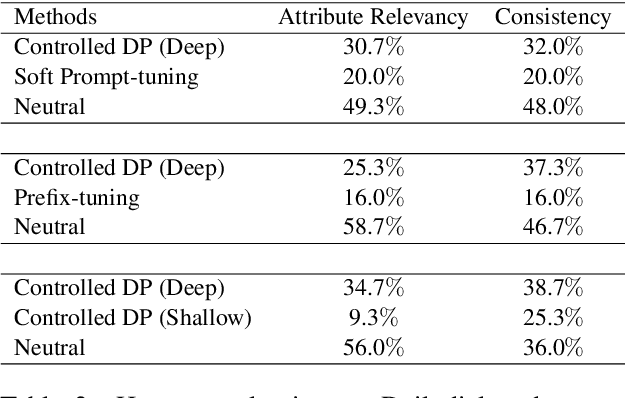
Prompt-tuning has become an increasingly popular parameter-efficient method for adapting large pretrained language models to downstream tasks. However, both discrete prompting and continuous prompting assume fixed prompts for all data samples within a task, neglecting the fact that inputs vary greatly in some tasks such as open-domain dialogue generation. In this paper, we present a novel, instance-specific prompt-tuning algorithm for dialogue generation. Specifically, we generate prompts based on instance-level control code, rather than the conversation history, to explore their impact on controlled dialogue generation. Experiments on popular open-domain dialogue datasets, evaluated on both automated metrics and human evaluation, demonstrate that our method is superior to prompting baselines and comparable to fine-tuning with only 5%-6% of total parameters.
LABO: Towards Learning Optimal Label Regularization via Bi-level Optimization
May 08, 2023



Regularization techniques are crucial to improving the generalization performance and training efficiency of deep neural networks. Many deep learning algorithms rely on weight decay, dropout, batch/layer normalization to converge faster and generalize. Label Smoothing (LS) is another simple, versatile and efficient regularization which can be applied to various supervised classification tasks. Conventional LS, however, regardless of the training instance assumes that each non-target class is equally likely. In this work, we present a general framework for training with label regularization, which includes conventional LS but can also model instance-specific variants. Based on this formulation, we propose an efficient way of learning LAbel regularization by devising a Bi-level Optimization (LABO) problem. We derive a deterministic and interpretable solution of the inner loop as the optimal label smoothing without the need to store the parameters or the output of a trained model. Finally, we conduct extensive experiments and demonstrate our LABO consistently yields improvement over conventional label regularization on various fields, including seven machine translation and three image classification tasks across various
Improving Generalization of Pre-trained Language Models via Stochastic Weight Averaging
Dec 16, 2022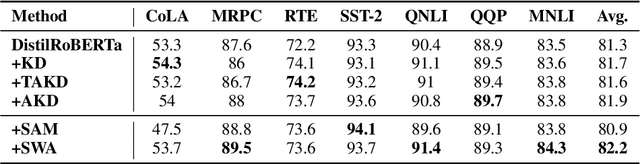
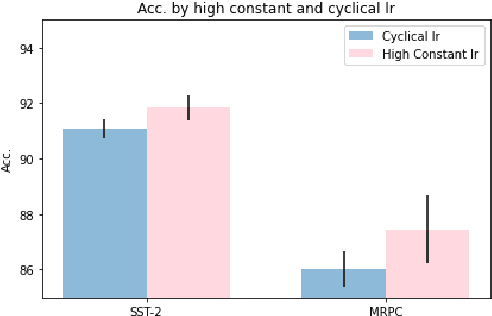
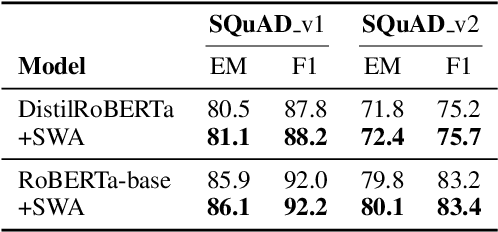
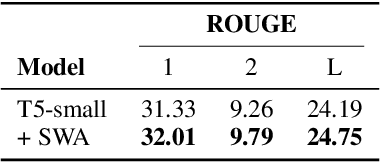
Knowledge Distillation (KD) is a commonly used technique for improving the generalization of compact Pre-trained Language Models (PLMs) on downstream tasks. However, such methods impose the additional burden of training a separate teacher model for every new dataset. Alternatively, one may directly work on the improvement of the optimization procedure of the compact model toward better generalization. Recent works observe that the flatness of the local minimum correlates well with better generalization. In this work, we adapt Stochastic Weight Averaging (SWA), a method encouraging convergence to a flatter minimum, to fine-tuning PLMs. We conduct extensive experiments on various NLP tasks (text classification, question answering, and generation) and different model architectures and demonstrate that our adaptation improves the generalization without extra computation cost. Moreover, we observe that this simple optimization technique is able to outperform the state-of-the-art KD methods for compact models.
Learning Functions on Multiple Sets using Multi-Set Transformers
Jun 30, 2022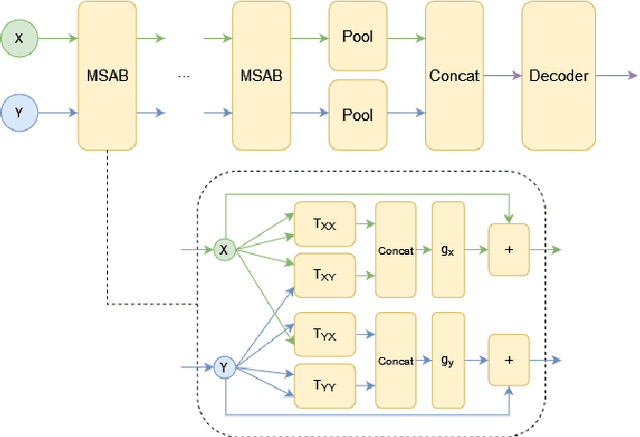
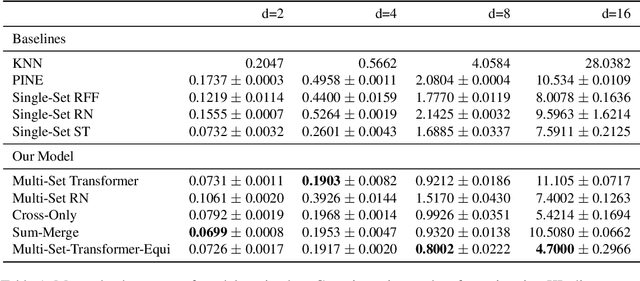

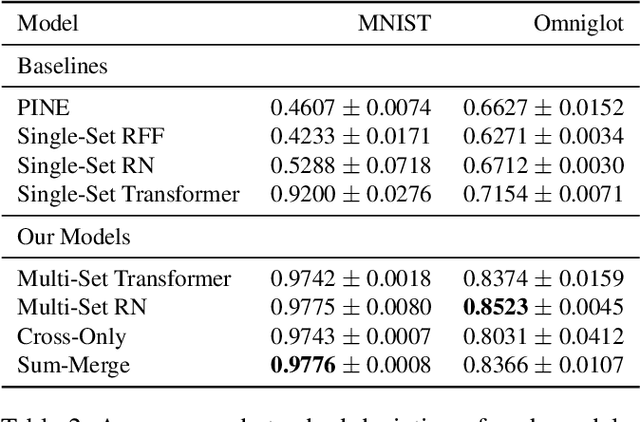
We propose a general deep architecture for learning functions on multiple permutation-invariant sets. We also show how to generalize this architecture to sets of elements of any dimension by dimension equivariance. We demonstrate that our architecture is a universal approximator of these functions, and show superior results to existing methods on a variety of tasks including counting tasks, alignment tasks, distinguishability tasks and statistical distance measurements. This last task is quite important in Machine Learning. Although our approach is quite general, we demonstrate that it can generate approximate estimates of KL divergence and mutual information that are more accurate than previous techniques that are specifically designed to approximate those statistical distances.
Revisiting Pre-trained Language Models and their Evaluation for Arabic Natural Language Understanding
May 21, 2022
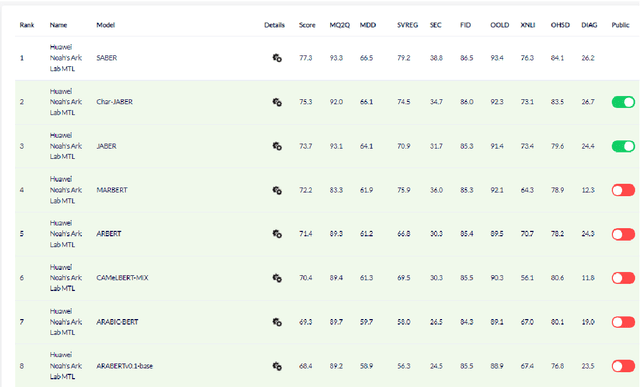
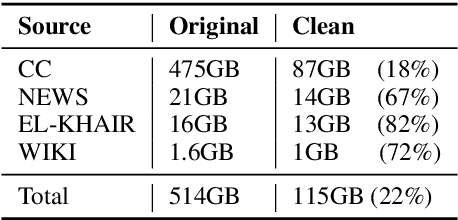
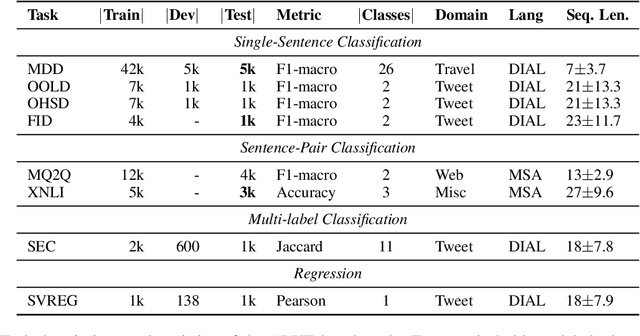
There is a growing body of work in recent years to develop pre-trained language models (PLMs) for the Arabic language. This work concerns addressing two major problems in existing Arabic PLMs which constraint progress of the Arabic NLU and NLG fields.First, existing Arabic PLMs are not well-explored and their pre-trainig can be improved significantly using a more methodical approach. Second, there is a lack of systematic and reproducible evaluation of these models in the literature. In this work, we revisit both the pre-training and evaluation of Arabic PLMs. In terms of pre-training, we explore improving Arabic LMs from three perspectives: quality of the pre-training data, size of the model, and incorporating character-level information. As a result, we release three new Arabic BERT-style models ( JABER, Char-JABER, and SABER), and two T5-style models (AT5S and AT5B). In terms of evaluation, we conduct a comprehensive empirical study to systematically evaluate the performance of existing state-of-the-art models on ALUE that is a leaderboard-powered benchmark for Arabic NLU tasks, and on a subset of the ARGEN benchmark for Arabic NLG tasks. We show that our models significantly outperform existing Arabic PLMs and achieve a new state-of-the-art performance on discriminative and generative Arabic NLU and NLG tasks. Our models and source code to reproduce of results will be made available shortly.
JABER and SABER: Junior and Senior Arabic BERt
Jan 09, 2022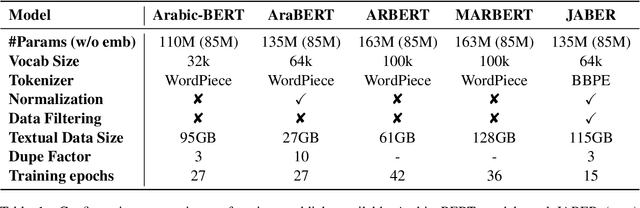
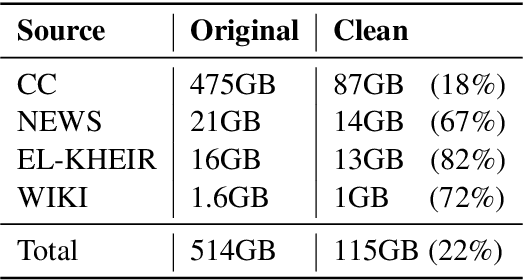
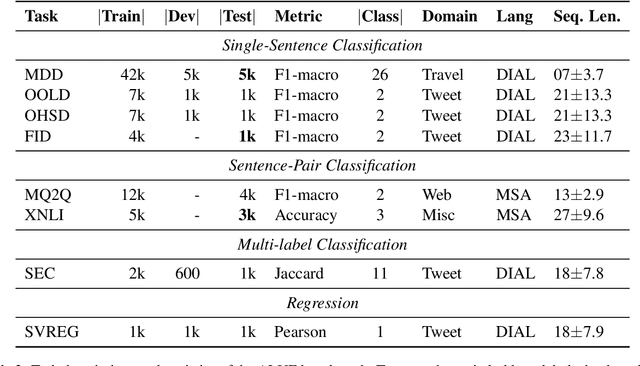
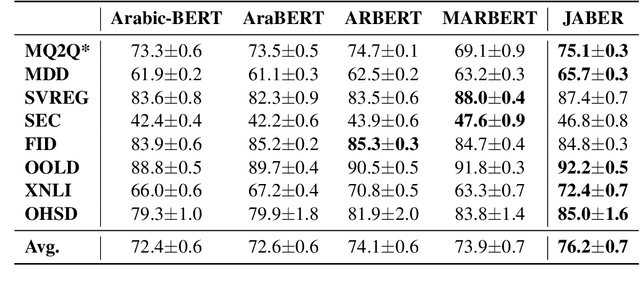
Language-specific pre-trained models have proven to be more accurate than multilingual ones in a monolingual evaluation setting, Arabic is no exception. However, we found that previously released Arabic BERT models were significantly under-trained. In this technical report, we present JABER and SABER, Junior and Senior Arabic BERt respectively, our pre-trained language model prototypes dedicated for Arabic. We conduct an empirical study to systematically evaluate the performance of models across a diverse set of existing Arabic NLU tasks. Experimental results show that JABER and SABER achieve state-of-the-art performances on ALUE, a new benchmark for Arabic Language Understanding Evaluation, as well as on a well-established NER benchmark.
NATURE: Natural Auxiliary Text Utterances for Realistic Spoken Language Evaluation
Nov 09, 2021



Slot-filling and intent detection are the backbone of conversational agents such as voice assistants, and are active areas of research. Even though state-of-the-art techniques on publicly available benchmarks show impressive performance, their ability to generalize to realistic scenarios is yet to be demonstrated. In this work, we present NATURE, a set of simple spoken-language oriented transformations, applied to the evaluation set of datasets, to introduce human spoken language variations while preserving the semantics of an utterance. We apply NATURE to common slot-filling and intent detection benchmarks and demonstrate that simple perturbations from the standard evaluation set by NATURE can deteriorate model performance significantly. Through our experiments we demonstrate that when NATURE operators are applied to evaluation set of popular benchmarks the model accuracy can drop by up to 40%.
A Short Study on Compressing Decoder-Based Language Models
Oct 16, 2021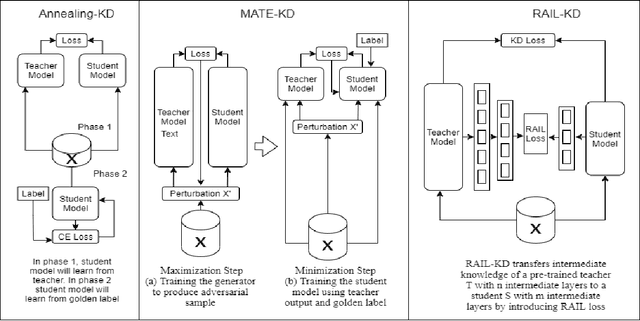
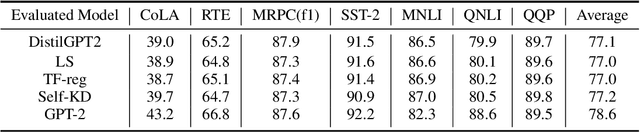


Pre-trained Language Models (PLMs) have been successful for a wide range of natural language processing (NLP) tasks. The state-of-the-art of PLMs, however, are extremely large to be used on edge devices. As a result, the topic of model compression has attracted increasing attention in the NLP community. Most of the existing works focus on compressing encoder-based models (tiny-BERT, distilBERT, distilRoBERTa, etc), however, to the best of our knowledge, the compression of decoder-based models (such as GPT-2) has not been investigated much. Our paper aims to fill this gap. Specifically, we explore two directions: 1) we employ current state-of-the-art knowledge distillation techniques to improve fine-tuning of DistilGPT-2. 2) we pre-train a compressed GPT-2 model using layer truncation and compare it against the distillation-based method (DistilGPT2). The training time of our compressed model is significantly less than DistilGPT-2, but it can achieve better performance when fine-tuned on downstream tasks. We also demonstrate the impact of data cleaning on model performance.
Kronecker Decomposition for GPT Compression
Oct 15, 2021



GPT is an auto-regressive Transformer-based pre-trained language model which has attracted a lot of attention in the natural language processing (NLP) domain due to its state-of-the-art performance in several downstream tasks. The success of GPT is mostly attributed to its pre-training on huge amount of data and its large number of parameters (from ~100M to billions of parameters). Despite the superior performance of GPT (especially in few-shot or zero-shot setup), this overparameterized nature of GPT can be very prohibitive for deploying this model on devices with limited computational power or memory. This problem can be mitigated using model compression techniques; however, compressing GPT models has not been investigated much in the literature. In this work, we use Kronecker decomposition to compress the linear mappings of the GPT-22 model. Our Kronecker GPT-2 model (KnGPT2) is initialized based on the Kronecker decomposed version of the GPT-2 model and then is undergone a very light pre-training on only a small portion of the training data with intermediate layer knowledge distillation (ILKD). Finally, our KnGPT2 is fine-tuned on down-stream tasks using ILKD as well. We evaluate our model on both language modeling and General Language Understanding Evaluation benchmark tasks and show that with more efficient pre-training and similar number of parameters, our KnGPT2 outperforms the existing DistilGPT2 model significantly.