 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbhinav Bhatele
Performance-Aligned LLMs for Generating Fast Code
Apr 29, 2024
Optimizing scientific software is a difficult task because codebases are often large and complex, and performance can depend upon several factors including the algorithm, its implementation, and hardware among others. Causes of poor performance can originate from disparate sources and be difficult to diagnose. Recent years have seen a multitude of work that use large language models (LLMs) to assist in software development tasks. However, these tools are trained to model the distribution of code as text, and are not specifically designed to understand performance aspects of code. In this work, we introduce a reinforcement learning based methodology to align the outputs of code LLMs with performance. This allows us to build upon the current code modeling capabilities of LLMs and extend them to generate better performing code. We demonstrate that our fine-tuned model improves the expected speedup of generated code over base models for a set of benchmark tasks from 0.9 to 1.6 for serial code and 1.9 to 4.5 for OpenMP code.
Can Large Language Models Write Parallel Code?
Jan 23, 2024Large Language Models are becoming an increasingly popular tool for software development. Their ability to model and generate source code has been demonstrated in a variety of contexts, including code completion, summarization, translation, and lookup. However, they often struggle to generate code for more complex tasks. In this paper, we explore the ability of state-of-the-art language models to generate parallel code. We propose a benchmark, PCGBench, consisting of a set of 420 tasks for evaluating the ability of language models to generate parallel code, and we evaluate the performance of several state-of-the-art open- and closed-source language models on these tasks. We introduce novel metrics for comparing parallel code generation performance and use them to explore how well each LLM performs on various parallel programming models and computational problem types.
Jorge: Approximate Preconditioning for GPU-efficient Second-order Optimization
Oct 27, 2023Despite their better convergence properties compared to first-order optimizers, second-order optimizers for deep learning have been less popular due to their significant computational costs. The primary efficiency bottleneck in such optimizers is matrix inverse calculations in the preconditioning step, which are expensive to compute on GPUs. In this paper, we introduce Jorge, a second-order optimizer that promises the best of both worlds -- rapid convergence benefits of second-order methods, and high computational efficiency typical of first-order methods. We address the primary computational bottleneck of computing matrix inverses by completely eliminating them using an approximation of the preconditioner computation. This makes Jorge extremely efficient on GPUs in terms of wall-clock time. Further, we describe an approach to determine Jorge's hyperparameters directly from a well-tuned SGD baseline, thereby significantly minimizing tuning efforts. Our empirical evaluations demonstrate the distinct advantages of using Jorge, outperforming state-of-the-art optimizers such as SGD, AdamW, and Shampoo across multiple deep learning models, both in terms of sample efficiency and wall-clock time.
Modeling Parallel Programs using Large Language Models
Jun 29, 2023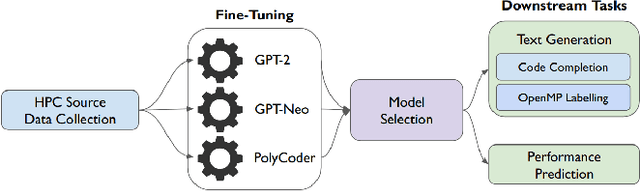
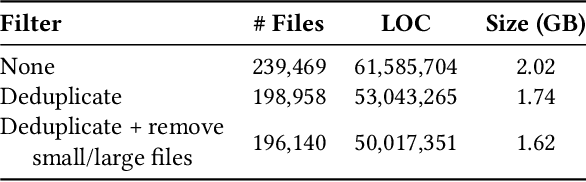
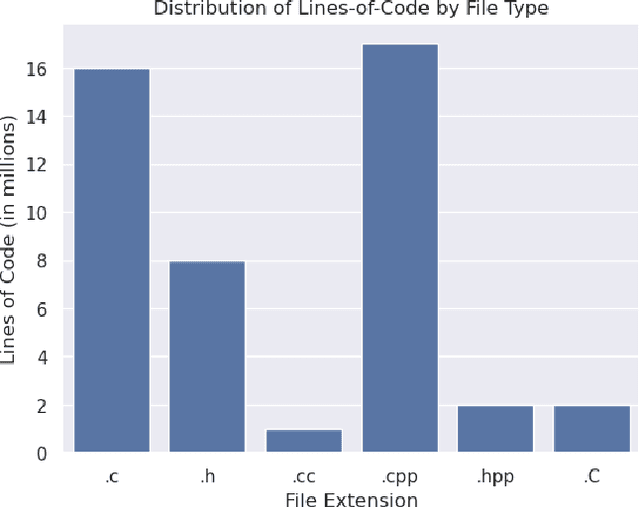

Parallel software codes in high performance computing (HPC) continue to grow in complexity and scale as we enter the exascale era. A diverse set of emerging hardware and programming paradigms make developing, optimizing, and maintaining parallel software burdensome for developers. One way to alleviate some of these burdens is with automated development and analysis tools. Such tools can perform complex and/or remedial tasks for developers that increase their productivity and decrease the chance for error. So far, such tools for code development and performance analysis have been limited in the complexity of tasks they can perform. However, with recent advancements in language modeling, and the wealth of code related data that is now available online, these tools have started to utilize predictive language models to automate more complex tasks. In this paper, we show how large language models (LLMs) can be applied to tasks specific to high performance and scientific codes. We train LLMs using code and performance data that is specific to parallel codes. We compare several recent LLMs on HPC related tasks and introduce a new model, HPC-Coder, trained on parallel code. In our experiments we show that this model can auto-complete HPC functions where general models cannot, decorate for loops with OpenMP pragmas, and model performance changes in two scientific application repositories.
Communication-minimizing Asynchronous Tensor Parallelism
May 22, 2023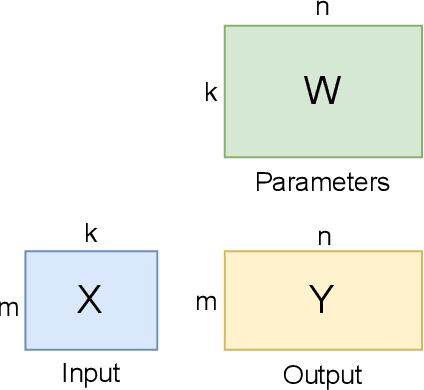
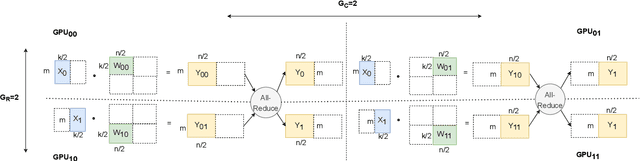
As state-of-the-art neural networks scale to billions of parameters, designing parallel algorithms that can train these networks efficiently on multi-GPU clusters has become critical. This paper presents Tensor3D, a novel three-dimensional (3D) approach to parallelize tensor computations, that strives to minimize the idle time incurred due to communication in parallel training of large multi-billion parameter models. First, we introduce an intelligent distribution of neural network parameters across GPUs that eliminates communication required for satisfying data dependencies of individual layers. Then, we propose a novel overdecomposition of the parallel training process, using which we achieve significant overlap of communication with computation, thereby reducing GPU idle time. Finally, we present a communication model, which helps users identify communication optimal decompositions of available hardware resources for a given neural network. For a 28B parameter CNN on 256 A100 GPUs, Tensor3D improves the training time by nearly 60% as compared to Megatron-LM.
A Novel Tensor-Expert Hybrid Parallelism Approach to Scale Mixture-of-Experts Training
Mar 11, 2023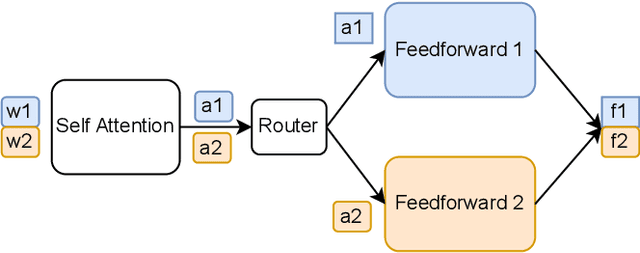
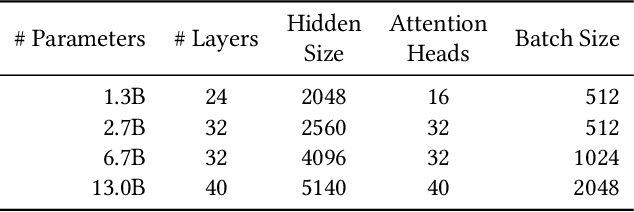
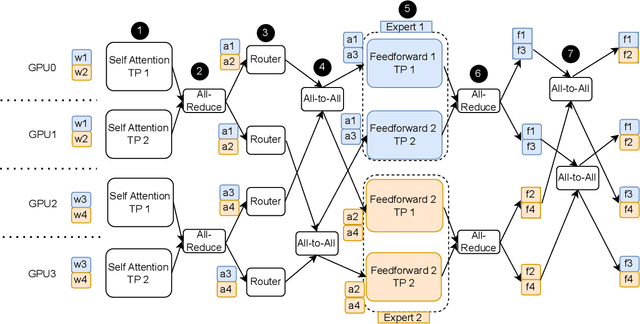
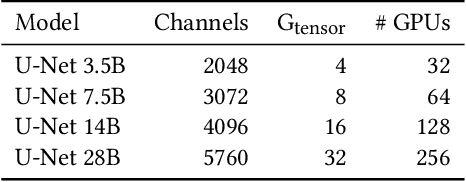
A new neural network architecture called Mixture-of-Experts (MoE) has been proposed recently that increases the parameters of a neural network (the base model) by adding sparsely activated expert blocks, without changing the total number of floating point operations for training or inference. In theory, this architecture allows us to train arbitrarily large models while keeping the computational costs same as that of the base model. However, beyond 64 to 128 experts blocks, prior work has observed diminishing returns in the test accuracies of these MoE models. Thus, training high quality MoE models requires us to scale the size of the base models, along with the number of expert blocks. In this work, we propose a novel, three-dimensional, hybrid parallel algorithm that combines tensor, expert, and data parallelism to enable the training of MoE models with 4-8x larger base models than the current state-of-the-art -- DeepSpeed-MoE. We propose memory optimizations in the optimizer step, and communication optimizations that eliminate redundant movement of data. Removing these redundancies provides a speedup of nearly 21%. When training a 40 billion parameter MoE model (6.7 billion base model with 16 experts) on 128 V100 GPUs, our optimizations significantly improve the peak half precision flop/s from 20% to 27%.
Exploiting Sparsity in Pruned Neural Networks to Optimize Large Model Training
Feb 10, 2023


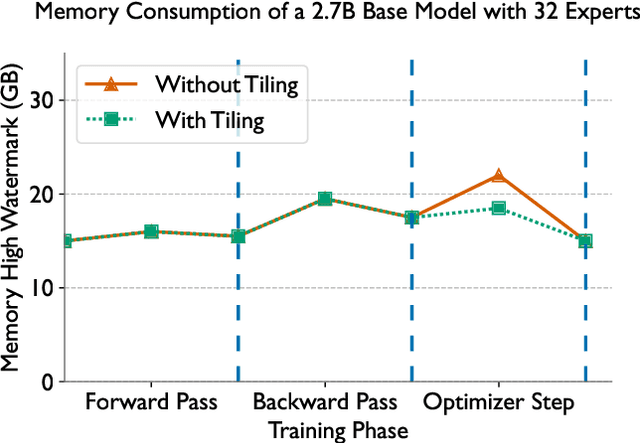
Parallel training of neural networks at scale is challenging due to significant overheads arising from communication. Recently, deep learning researchers have developed a variety of pruning algorithms that are capable of pruning (i.e. setting to zero) 80-90% of the parameters in a neural network to yield sparse subnetworks that equal the accuracy of the unpruned parent network. In this work, we propose a novel approach that exploits these sparse subnetworks to optimize the memory utilization and communication in two popular algorithms for parallel deep learning namely -- data and inter-layer parallelism. We integrate our approach into AxoNN, a highly scalable framework for parallel deep learning that relies on data and inter-layer parallelism, and demonstrate the reduction in communication times and memory utilization. On 512 NVIDIA V100 GPUs, our optimizations reduce the memory consumption of a 2.7 billion parameter model by 74%, and the total communication times by 40%, thus providing an overall speedup of 34% over AxoNN, 32% over DeepSpeed-3D and 46% over Sputnik, a sparse matrix computation baseline.
How to Train Your Neural Network: A Comparative Evaluation
Nov 09, 2021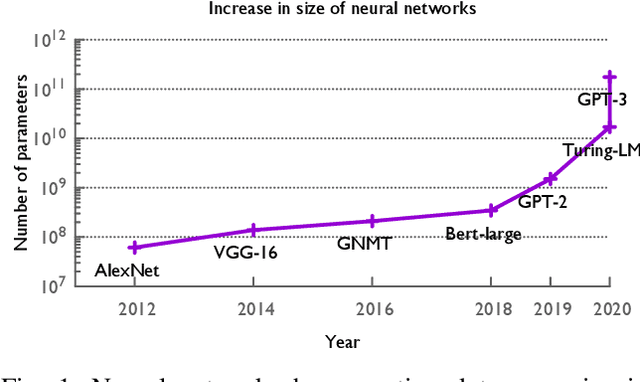
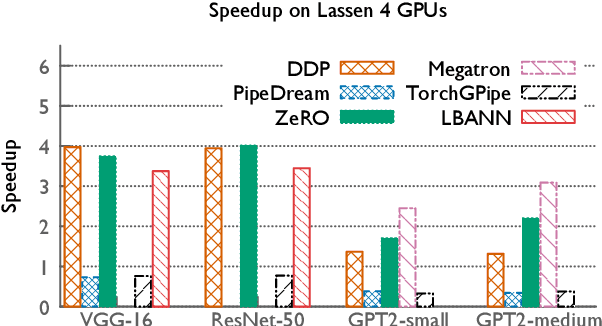
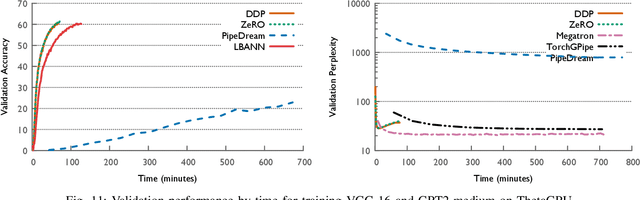
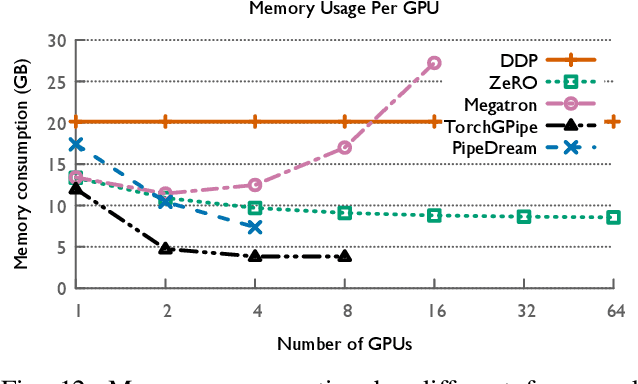
The field of deep learning has witnessed a remarkable shift towards extremely compute- and memory-intensive neural networks. These newer larger models have enabled researchers to advance state-of-the-art tools across a variety of fields. This phenomenon has spurred the development of algorithms for distributed training of neural networks over a larger number of hardware accelerators. In this paper, we discuss and compare current state-of-the-art frameworks for large scale distributed deep learning. First, we survey current practices in distributed learning and identify the different types of parallelism used. Then, we present empirical results comparing their performance on large image and language training tasks. Additionally, we address their statistical efficiency and memory consumption behavior. Based on our results, we discuss algorithmic and implementation portions of each framework which hinder performance.
Myelin: An asynchronous, message-driven parallel framework for extreme-scale deep learning
Oct 26, 2021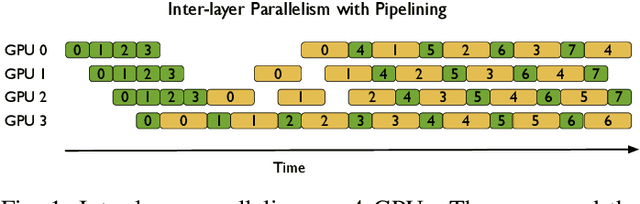
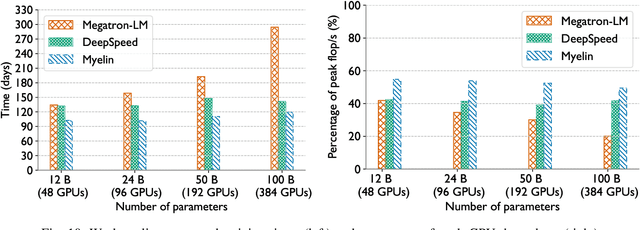
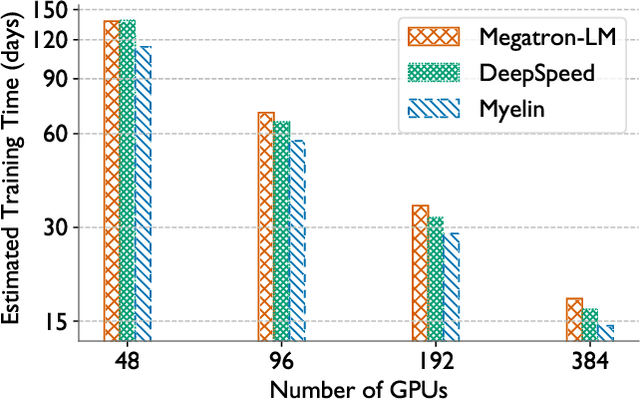
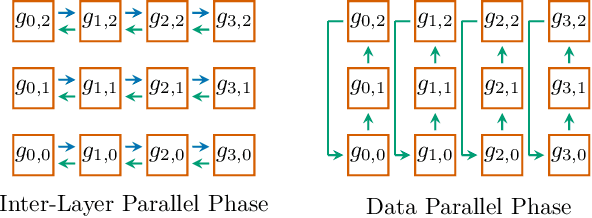
In the last few years, the memory requirements to train state-of-the-art neural networks have far exceeded the DRAM capacities of modern hardware accelerators. This has necessitated the development of efficient algorithms to train these neural networks in parallel on large-scale GPU-based clusters. Since computation is relatively inexpensive on modern GPUs, designing and implementing extremely efficient communication in these parallel training algorithms is critical for extracting the maximum performance. This paper presents Myelin, a parallel deep learning framework that exploits asynchrony and message-driven execution to schedule neural network operations on each GPU, thereby reducing GPU idle time and maximizing hardware efficiency. By using the CPU memory as a scratch space for offloading data periodically during training, Myelin is able to reduce GPU memory consumption by four times. This allows us to increase the number of parameters per GPU by four times, thus reducing the amount of communication and increasing performance by over 13%. When tested against large transformer models with 12-100 billion parameters on 48-384 NVIDIA Tesla V100 GPUs, Myelin achieves a per-GPU throughput of 49.4-54.78% of theoretical peak and reduces the training time by 22-37 days (15-25% speedup) as compared to the state-of-the-art.
Analytics of Longitudinal System Monitoring Data for Performance Prediction
Jul 07, 2020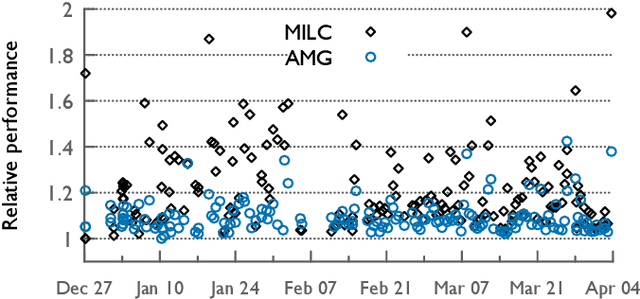
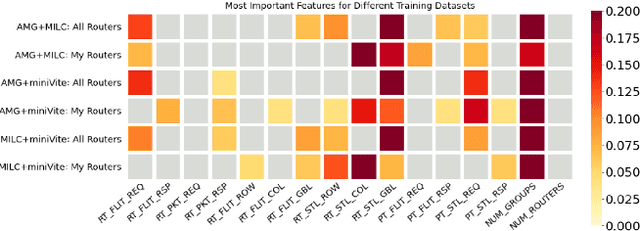
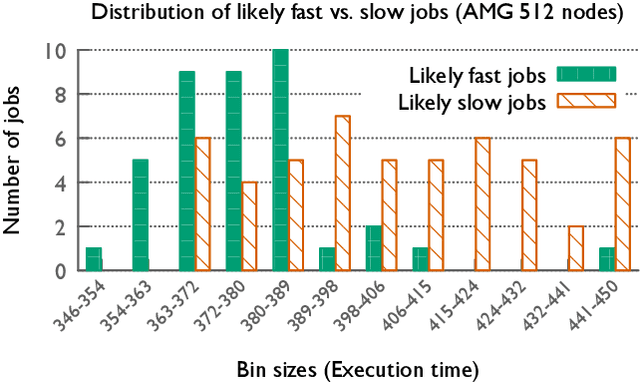
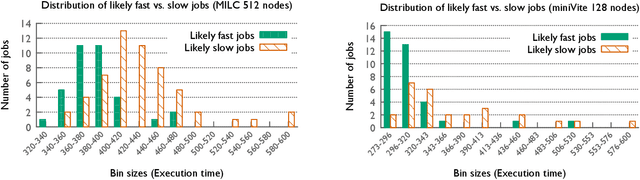
In recent years, several HPC facilities have started continuous monitoring of their systems and jobs to collect performance-related data for understanding performance and operational efficiency. Such data can be used to optimize the performance of individual jobs and the overall system by creating data-driven models that can predict the performance of pending jobs. In this paper, we model the performance of representative control jobs using longitudinal system-wide monitoring data to explore the causes of performance variability. Using machine learning, we are able to predict the performance of unseen jobs before they are executed based on the current system state. We analyze these prediction models in great detail to identify the features that are dominant predictors of performance. We demonstrate that such models can be application-agnostic and can be used for predicting performance of applications that are not included in training.