 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiddharth Singh
HarmPot: An Annotation Framework for Evaluating Offline Harm Potential of Social Media Text
Mar 17, 2024

In this paper, we discuss the development of an annotation schema to build datasets for evaluating the offline harm potential of social media texts. We define "harm potential" as the potential for an online public post to cause real-world physical harm (i.e., violence). Understanding that real-world violence is often spurred by a web of triggers, often combining several online tactics and pre-existing intersectional fissures in the social milieu, to result in targeted physical violence, we do not focus on any single divisive aspect (i.e., caste, gender, religion, or other identities of the victim and perpetrators) nor do we focus on just hate speech or mis/dis-information. Rather, our understanding of the intersectional causes of such triggers focuses our attempt at measuring the harm potential of online content, irrespective of whether it is hateful or not. In this paper, we discuss the development of a framework/annotation schema that allows annotating the data with different aspects of the text including its socio-political grounding and intent of the speaker (as expressed through mood and modality) that together contribute to it being a trigger for offline harm. We also give a comparative analysis and mapping of our framework with some of the existing frameworks.
A Framework for Realistic Simulation of Daily Human Activity
Nov 26, 2023
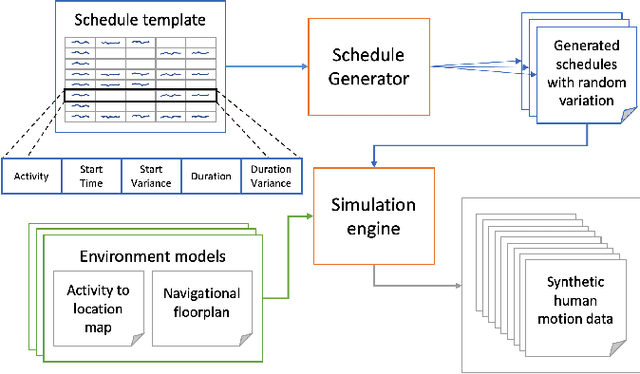
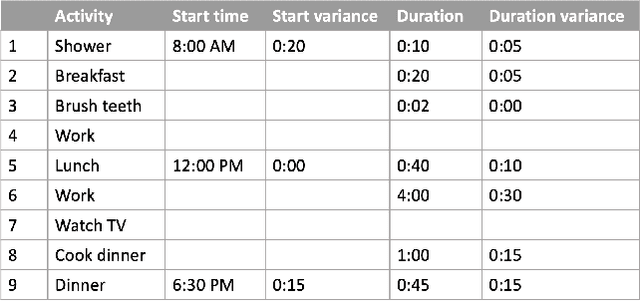
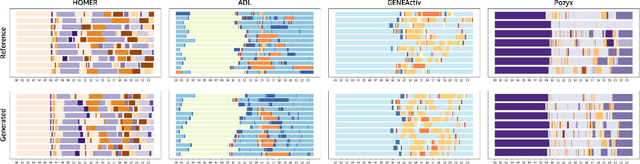
For social robots like Astro which interact with and adapt to the daily movements of users within the home, realistic simulation of human activity is needed for feature development and testing. This paper presents a framework for simulating daily human activity patterns in home environments at scale, supporting manual configurability of different personas or activity patterns, variation of activity timings, and testing on multiple home layouts. We introduce a method for specifying day-to-day variation in schedules and present a bidirectional constraint propagation algorithm for generating schedules from templates. We validate the expressive power of our framework through a use case scenario analysis and demonstrate that our method can be used to generate data closely resembling human behavior from three public datasets and a self-collected dataset. Our contribution supports systematic testing of social robot behaviors at scale, enables procedural generation of synthetic datasets of human movement in different households, and can help minimize bias in training data, leading to more robust and effective robots for home environments.
Jorge: Approximate Preconditioning for GPU-efficient Second-order Optimization
Oct 27, 2023Despite their better convergence properties compared to first-order optimizers, second-order optimizers for deep learning have been less popular due to their significant computational costs. The primary efficiency bottleneck in such optimizers is matrix inverse calculations in the preconditioning step, which are expensive to compute on GPUs. In this paper, we introduce Jorge, a second-order optimizer that promises the best of both worlds -- rapid convergence benefits of second-order methods, and high computational efficiency typical of first-order methods. We address the primary computational bottleneck of computing matrix inverses by completely eliminating them using an approximation of the preconditioner computation. This makes Jorge extremely efficient on GPUs in terms of wall-clock time. Further, we describe an approach to determine Jorge's hyperparameters directly from a well-tuned SGD baseline, thereby significantly minimizing tuning efforts. Our empirical evaluations demonstrate the distinct advantages of using Jorge, outperforming state-of-the-art optimizers such as SGD, AdamW, and Shampoo across multiple deep learning models, both in terms of sample efficiency and wall-clock time.
Communication-minimizing Asynchronous Tensor Parallelism
May 22, 2023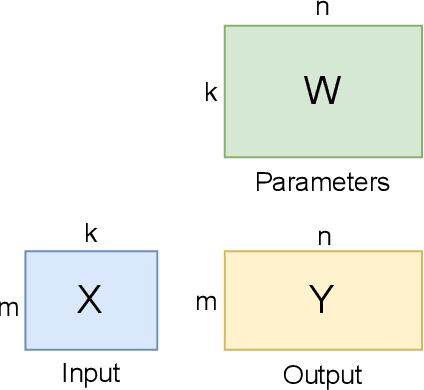
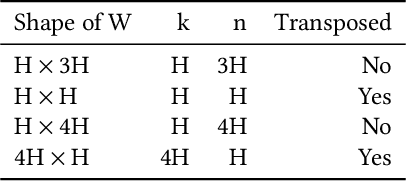
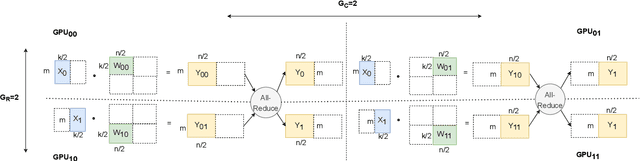
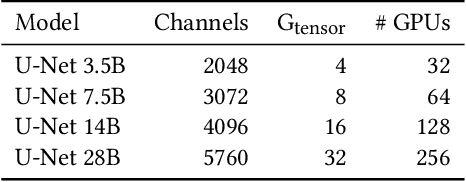
As state-of-the-art neural networks scale to billions of parameters, designing parallel algorithms that can train these networks efficiently on multi-GPU clusters has become critical. This paper presents Tensor3D, a novel three-dimensional (3D) approach to parallelize tensor computations, that strives to minimize the idle time incurred due to communication in parallel training of large multi-billion parameter models. First, we introduce an intelligent distribution of neural network parameters across GPUs that eliminates communication required for satisfying data dependencies of individual layers. Then, we propose a novel overdecomposition of the parallel training process, using which we achieve significant overlap of communication with computation, thereby reducing GPU idle time. Finally, we present a communication model, which helps users identify communication optimal decompositions of available hardware resources for a given neural network. For a 28B parameter CNN on 256 A100 GPUs, Tensor3D improves the training time by nearly 60% as compared to Megatron-LM.
A Novel Tensor-Expert Hybrid Parallelism Approach to Scale Mixture-of-Experts Training
Mar 11, 2023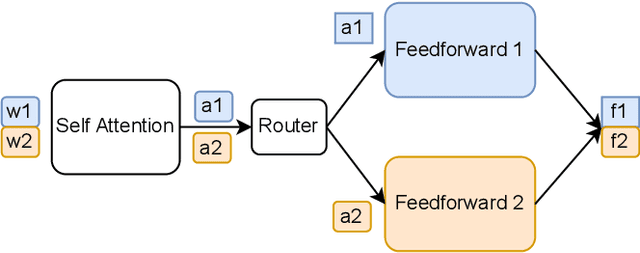
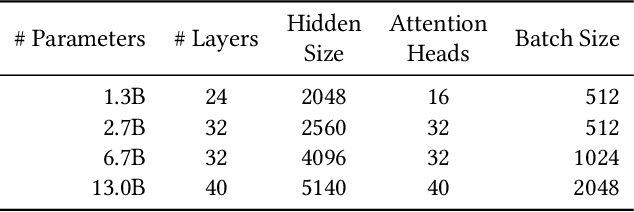
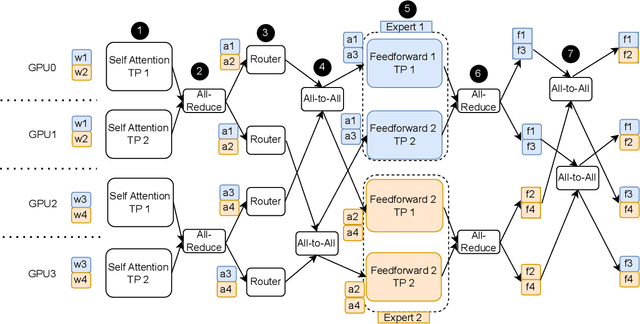
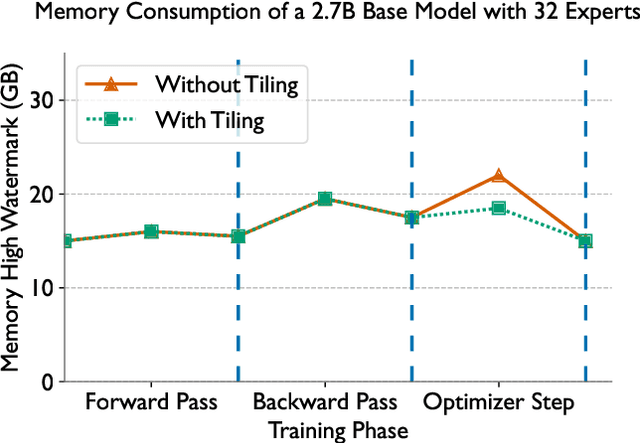
A new neural network architecture called Mixture-of-Experts (MoE) has been proposed recently that increases the parameters of a neural network (the base model) by adding sparsely activated expert blocks, without changing the total number of floating point operations for training or inference. In theory, this architecture allows us to train arbitrarily large models while keeping the computational costs same as that of the base model. However, beyond 64 to 128 experts blocks, prior work has observed diminishing returns in the test accuracies of these MoE models. Thus, training high quality MoE models requires us to scale the size of the base models, along with the number of expert blocks. In this work, we propose a novel, three-dimensional, hybrid parallel algorithm that combines tensor, expert, and data parallelism to enable the training of MoE models with 4-8x larger base models than the current state-of-the-art -- DeepSpeed-MoE. We propose memory optimizations in the optimizer step, and communication optimizations that eliminate redundant movement of data. Removing these redundancies provides a speedup of nearly 21%. When training a 40 billion parameter MoE model (6.7 billion base model with 16 experts) on 128 V100 GPUs, our optimizations significantly improve the peak half precision flop/s from 20% to 27%.
Exploiting Sparsity in Pruned Neural Networks to Optimize Large Model Training
Feb 10, 2023


Parallel training of neural networks at scale is challenging due to significant overheads arising from communication. Recently, deep learning researchers have developed a variety of pruning algorithms that are capable of pruning (i.e. setting to zero) 80-90% of the parameters in a neural network to yield sparse subnetworks that equal the accuracy of the unpruned parent network. In this work, we propose a novel approach that exploits these sparse subnetworks to optimize the memory utilization and communication in two popular algorithms for parallel deep learning namely -- data and inter-layer parallelism. We integrate our approach into AxoNN, a highly scalable framework for parallel deep learning that relies on data and inter-layer parallelism, and demonstrate the reduction in communication times and memory utilization. On 512 NVIDIA V100 GPUs, our optimizations reduce the memory consumption of a 2.7 billion parameter model by 74%, and the total communication times by 40%, thus providing an overall speedup of 34% over AxoNN, 32% over DeepSpeed-3D and 46% over Sputnik, a sparse matrix computation baseline.
Annotated Speech Corpus for Low Resource Indian Languages: Awadhi, Bhojpuri, Braj and Magahi
Jun 26, 2022
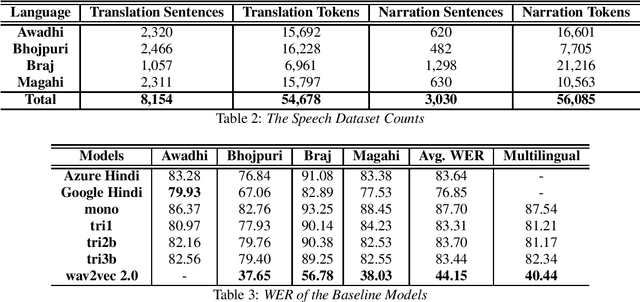
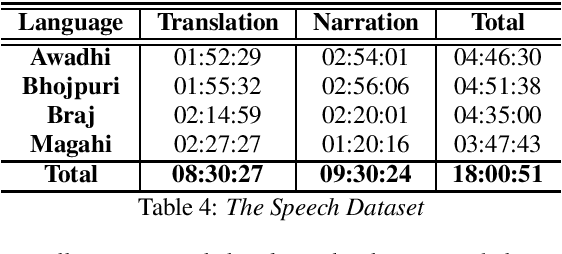
In this paper we discuss an in-progress work on the development of a speech corpus for four low-resource Indo-Aryan languages -- Awadhi, Bhojpuri, Braj and Magahi using the field methods of linguistic data collection. The total size of the corpus currently stands at approximately 18 hours (approx. 4-5 hours each language) and it is transcribed and annotated with grammatical information such as part-of-speech tags, morphological features and Universal dependency relationships. We discuss our methodology for data collection in these languages, most of which was done in the middle of the COVID-19 pandemic, with one of the aims being to generate some additional income for low-income groups speaking these languages. In the paper, we also discuss the results of the baseline experiments for automatic speech recognition system in these languages.
Demo of the Linguistic Field Data Management and Analysis System -- LiFE
Mar 22, 2022In the proposed demo, we will present a new software - Linguistic Field Data Management and Analysis System - LiFE (https://github.com/kmi-linguistics/life) - an open-source, web-based linguistic data management and analysis application that allows for systematic storage, management, sharing and usage of linguistic data collected from the field. The application allows users to store lexical items, sentences, paragraphs, audio-visual content with rich glossing / annotation; generate interactive and print dictionaries; and also train and use natural language processing tools and models for various purposes using this data. Since its a web-based application, it also allows for seamless collaboration among multiple persons and sharing the data, models, etc with each other. The system uses the Python-based Flask framework and MongoDB in the backend and HTML, CSS and Javascript at the frontend. The interface allows creation of multiple projects that could be shared with the other users. At the backend, the application stores the data in RDF format so as to allow its release as Linked Data over the web using semantic web technologies - as of now it makes use of the OntoLex-Lemon for storing the lexical data and Ligt for storing the interlinear glossed text and then internally linking it to the other linked lexicons and databases such as DBpedia and WordNet. Furthermore it provides support for training the NLP systems using scikit-learn and HuggingFace Transformers libraries as well as make use of any model trained using these libraries - while the user interface itself provides limited options for tuning the system, an externally-trained model could be easily incorporated within the application; similarly the dataset itself could be easily exported into a standard machine-readable format like JSON or CSV that could be consumed by other programs and pipelines.
The ComMA Dataset V0.2: Annotating Aggression and Bias in Multilingual Social Media Discourse
Nov 19, 2021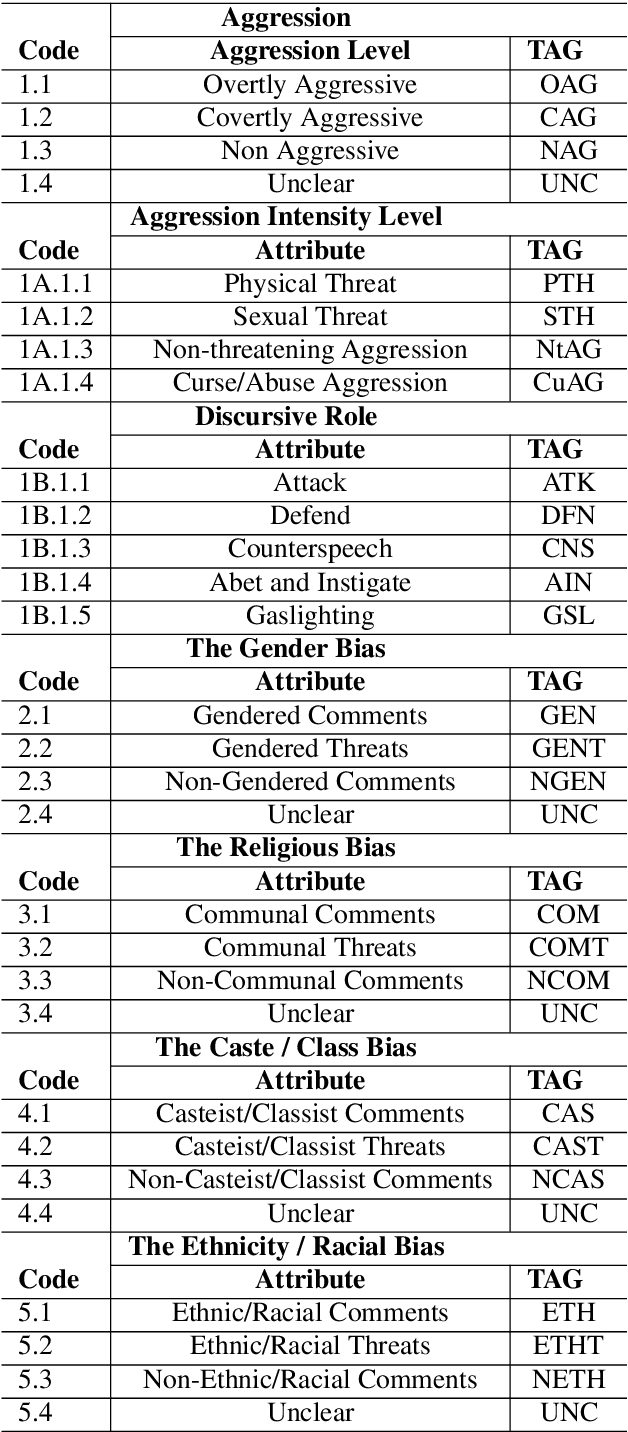
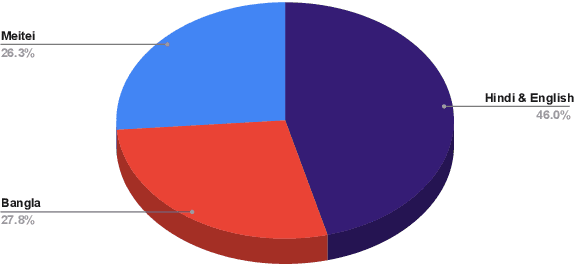
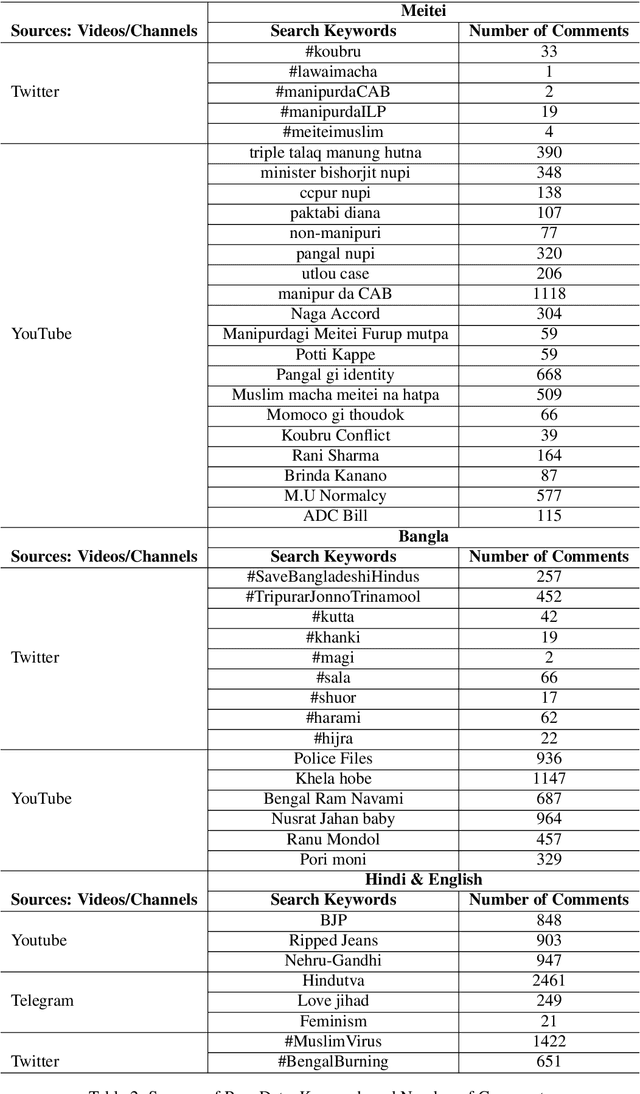
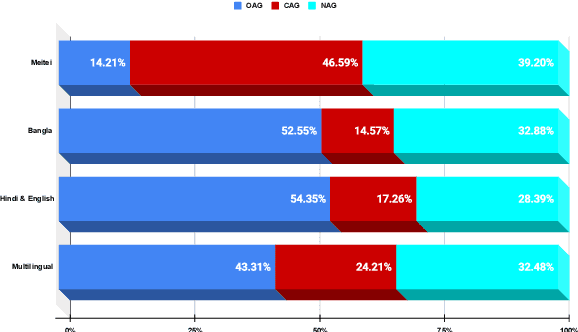
In this paper, we discuss the development of a multilingual dataset annotated with a hierarchical, fine-grained tagset marking different types of aggression and the "context" in which they occur. The context, here, is defined by the conversational thread in which a specific comment occurs and also the "type" of discursive role that the comment is performing with respect to the previous comment. The initial dataset, being discussed here (and made available as part of the ComMA@ICON shared task), consists of a total 15,000 annotated comments in four languages - Meitei, Bangla, Hindi, and Indian English - collected from various social media platforms such as YouTube, Facebook, Twitter and Telegram. As is usual on social media websites, a large number of these comments are multilingual, mostly code-mixed with English. The paper gives a detailed description of the tagset being used for annotation and also the process of developing a multi-label, fine-grained tagset that can be used for marking comments with aggression and bias of various kinds including gender bias, religious intolerance (called communal bias in the tagset), class/caste bias and ethnic/racial bias. We also define and discuss the tags that have been used for marking different the discursive role being performed through the comments, such as attack, defend, etc. We also present a statistical analysis of the dataset as well as results of our baseline experiments with developing an automatic aggression identification system using the dataset developed.
How to Train Your Neural Network: A Comparative Evaluation
Nov 09, 2021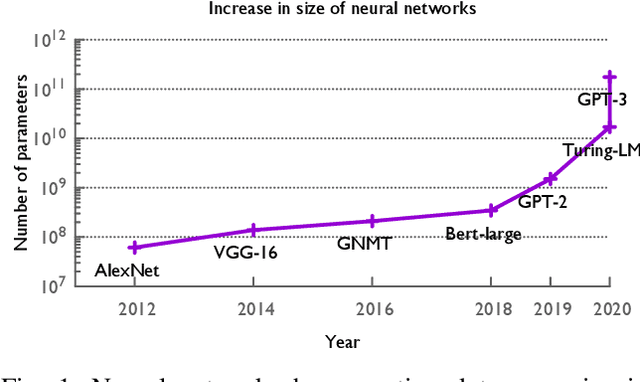
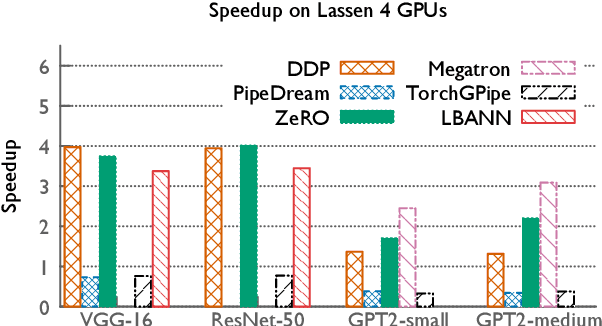
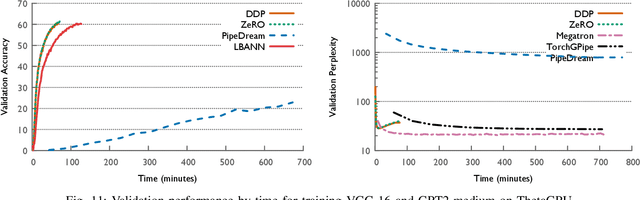
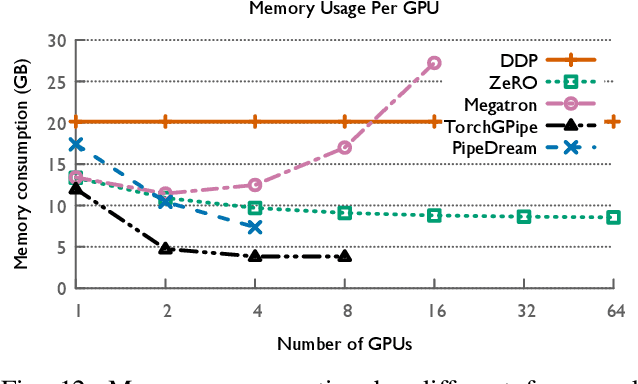
The field of deep learning has witnessed a remarkable shift towards extremely compute- and memory-intensive neural networks. These newer larger models have enabled researchers to advance state-of-the-art tools across a variety of fields. This phenomenon has spurred the development of algorithms for distributed training of neural networks over a larger number of hardware accelerators. In this paper, we discuss and compare current state-of-the-art frameworks for large scale distributed deep learning. First, we survey current practices in distributed learning and identify the different types of parallelism used. Then, we present empirical results comparing their performance on large image and language training tasks. Additionally, we address their statistical efficiency and memory consumption behavior. Based on our results, we discuss algorithmic and implementation portions of each framework which hinder performance.