 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdnane Boukhayma
Unsupervised Occupancy Learning from Sparse Point Cloud
Apr 03, 2024
Implicit Neural Representations have gained prominence as a powerful framework for capturing complex data modalities, encompassing a wide range from 3D shapes to images and audio. Within the realm of 3D shape representation, Neural Signed Distance Functions (SDF) have demonstrated remarkable potential in faithfully encoding intricate shape geometry. However, learning SDFs from 3D point clouds in the absence of ground truth supervision remains a very challenging task. In this paper, we propose a method to infer occupancy fields instead of SDFs as they are easier to learn from sparse inputs. We leverage a margin-based uncertainty measure to differentially sample from the decision boundary of the occupancy function and supervise the sampled boundary points using the input point cloud. We further stabilize the optimization process at the early stages of the training by biasing the occupancy function towards minimal entropy fields while maximizing its entropy at the input point cloud. Through extensive experiments and evaluations, we illustrate the efficacy of our proposed method, highlighting its capacity to improve implicit shape inference with respect to baselines and the state-of-the-art using synthetic and real data.
Robustifying Generalizable Implicit Shape Networks with a Tunable Non-Parametric Model
Nov 21, 2023Feedforward generalizable models for implicit shape reconstruction from unoriented point cloud present multiple advantages, including high performance and inference speed. However, they still suffer from generalization issues, ranging from underfitting the input point cloud, to misrepresenting samples outside of the training data distribution, or with toplogies unseen at training. We propose here an efficient mechanism to remedy some of these limitations at test time. We combine the inter-shape data prior of the network with an intra-shape regularization prior of a Nystr\"om Kernel Ridge Regression, that we further adapt by fitting its hyperprameters to the current shape. The resulting shape function defined in a shape specific Reproducing Kernel Hilbert Space benefits from desirable stability and efficiency properties and grants a shape adaptive expressiveness-robustness trade-off. We demonstrate the improvement obtained through our method with respect to baselines and the state-of-the-art using synthetic and real data.
Mixing-Denoising Generalizable Occupancy Networks
Nov 20, 2023While current state-of-the-art generalizable implicit neural shape models rely on the inductive bias of convolutions, it is still not entirely clear how properties emerging from such biases are compatible with the task of 3D reconstruction from point cloud. We explore an alternative approach to generalizability in this context. We relax the intrinsic model bias (i.e. using MLPs to encode local features as opposed to convolutions) and constrain the hypothesis space instead with an auxiliary regularization related to the reconstruction task, i.e. denoising. The resulting model is the first only-MLP locally conditioned implicit shape reconstruction from point cloud network with fast feed forward inference. Point cloud borne features and denoising offsets are predicted from an exclusively MLP-made network in a single forward pass. A decoder predicts occupancy probabilities for queries anywhere in space by pooling nearby features from the point cloud order-invariantly, guided by denoised relative positional encoding. We outperform the state-of-the-art convolutional method while using half the number of model parameters.
Neural Mesh-Based Graphics
Aug 23, 2022
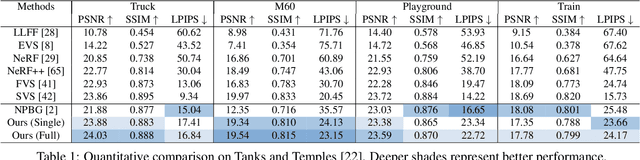


We revisit NPBG, the popular approach to novel view synthesis that introduced the ubiquitous point feature neural rendering paradigm. We are interested in particular in data-efficient learning with fast view synthesis. We achieve this through a view-dependent mesh-based denser point descriptor rasterization, in addition to a foreground/background scene rendering split, and an improved loss. By training solely on a single scene, we outperform NPBG, which has been trained on ScanNet and then scene finetuned. We also perform competitively with respect to the state-of-the-art method SVS, which has been trained on the full dataset (DTU and Tanks and Temples) and then scene finetuned, in spite of their deeper neural renderer.
Learning Generalizable Light Field Networks from Few Images
Jul 24, 2022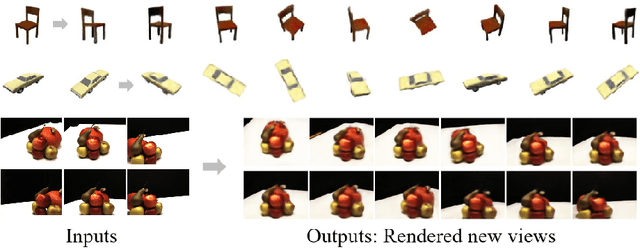
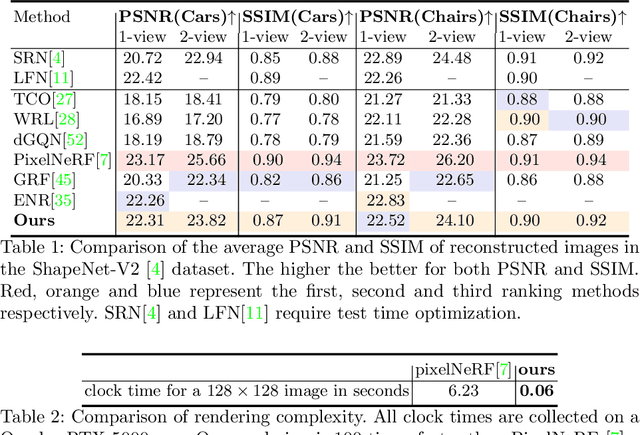
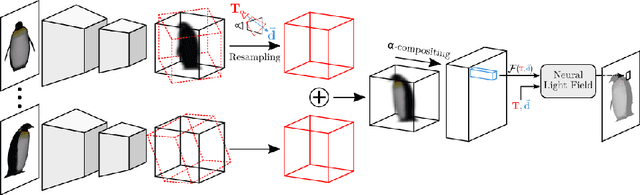
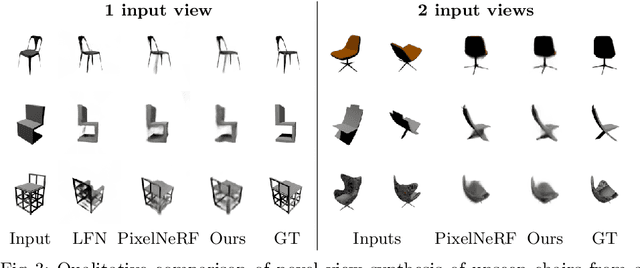
We explore a new strategy for few-shot novel view synthesis based on a neural light field representation. Given a target camera pose, an implicit neural network maps each ray to its target pixel's color directly. The network is conditioned on local ray features generated by coarse volumetric rendering from an explicit 3D feature volume. This volume is built from the input images using a 3D ConvNet. Our method achieves competitive performances on synthetic and real MVS data with respect to state-of-the-art neural radiance field based competition, while offering a 100 times faster rendering.
Few 'Zero Level Set'-Shot Learning of Shape Signed Distance Functions in Feature Space
Jul 09, 2022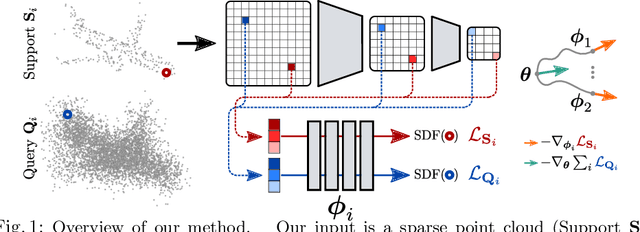



We explore a new idea for learning based shape reconstruction from a point cloud, based on the recently popularized implicit neural shape representations. We cast the problem as a few-shot learning of implicit neural signed distance functions in feature space, that we approach using gradient based meta-learning. We use a convolutional encoder to build a feature space given the input point cloud. An implicit decoder learns to predict signed distance values given points represented in this feature space. Setting the input point cloud, i.e. samples from the target shape function's zero level set, as the support (i.e. context) in few-shot learning terms, we train the decoder such that it can adapt its weights to the underlying shape of this context with a few (5) tuning steps. We thus combine two types of implicit neural network conditioning mechanisms simultaneously for the first time, namely feature encoding and meta-learning. Our numerical and qualitative evaluation shows that in the context of implicit reconstruction from a sparse point cloud, our proposed strategy, i.e. meta-learning in feature space, outperforms existing alternatives, namely standard supervised learning in feature space, and meta-learning in euclidean space, while still providing fast inference.
Monocular Human Shape and Pose with Dense Mesh-borne Local Image Features
Nov 11, 2021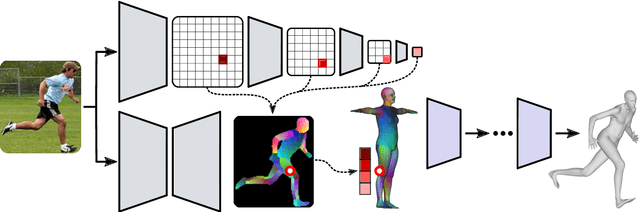

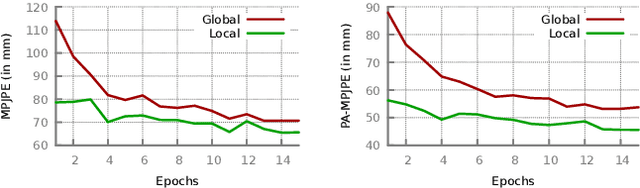
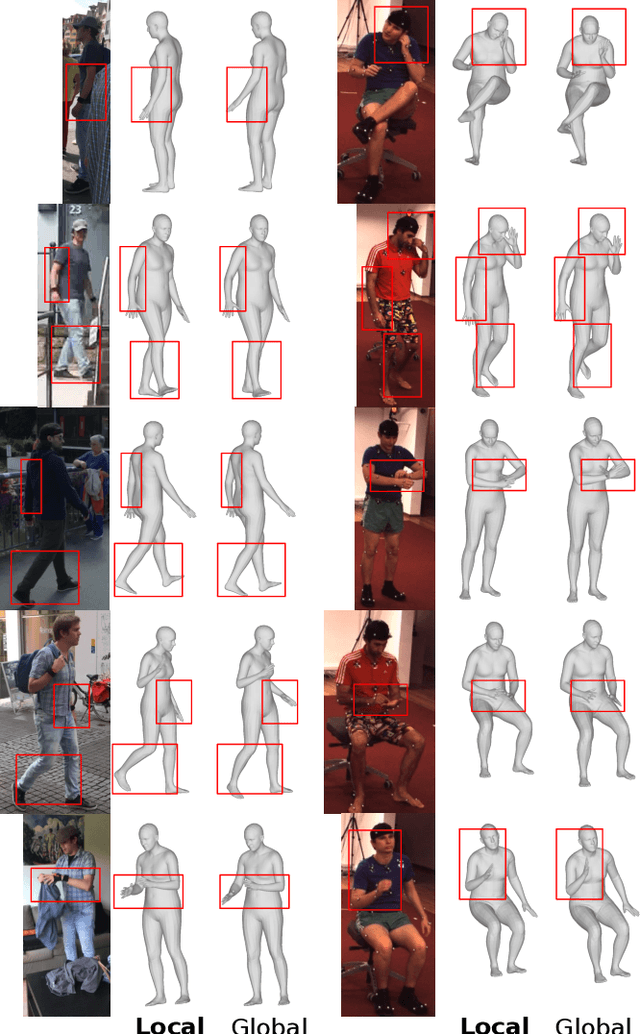
We propose to improve on graph convolution based approaches for human shape and pose estimation from monocular input, using pixel-aligned local image features. Given a single input color image, existing graph convolutional network (GCN) based techniques for human shape and pose estimation use a single convolutional neural network (CNN) generated global image feature appended to all mesh vertices equally to initialize the GCN stage, which transforms a template T-posed mesh into the target pose. In contrast, we propose for the first time the idea of using local image features per vertex. These features are sampled from the CNN image feature maps by utilizing pixel-to-mesh correspondences generated with DensePose. Our quantitative and qualitative results on standard benchmarks show that using local features improves on global ones and leads to competitive performances with respect to the state-of-the-art.
Neural Human Deformation Transfer
Oct 01, 2021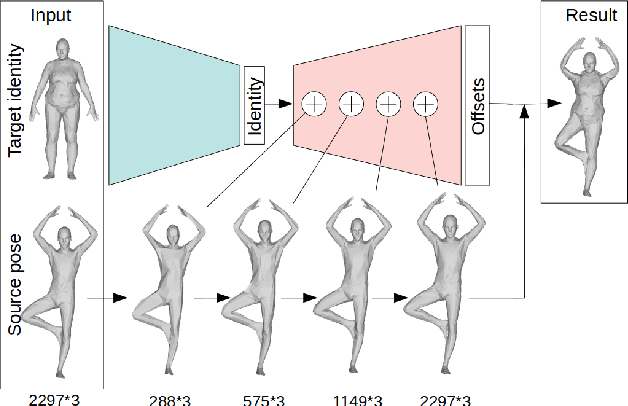

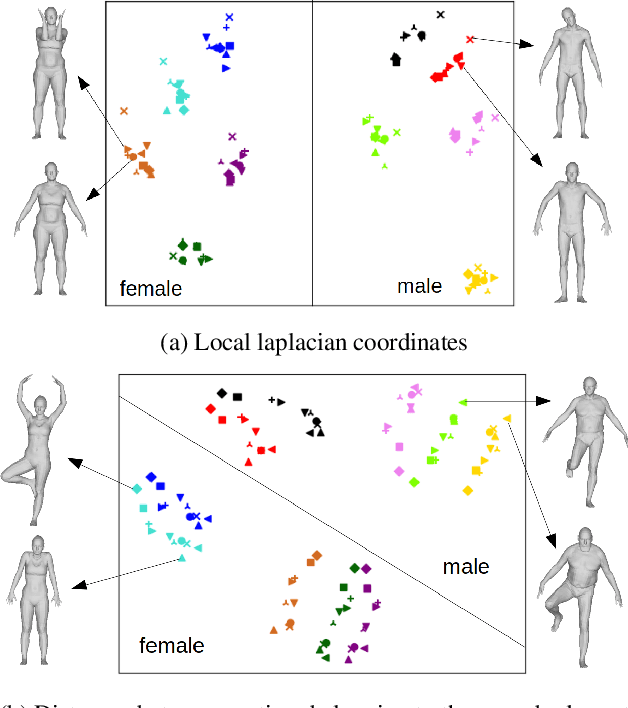
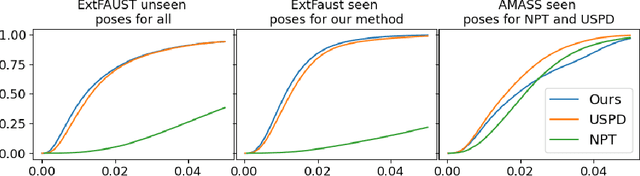
We consider the problem of human deformation transfer, where the goal is to retarget poses between different characters. Traditional methods that tackle this problem require a clear definition of the pose, and use this definition to transfer poses between characters. In this work, we take a different approach and transform the identity of a character into a new identity without modifying the character's pose. This offers the advantage of not having to define equivalences between 3D human poses, which is not straightforward as poses tend to change depending on the identity of the character performing them, and as their meaning is highly contextual. To achieve the deformation transfer, we propose a neural encoder-decoder architecture where only identity information is encoded and where the decoder is conditioned on the pose. We use pose independent representations, such as isometry-invariant shape characteristics, to represent identity features. Our model uses these features to supervise the prediction of offsets from the deformed pose to the result of the transfer. We show experimentally that our method outperforms state-of-the-art methods both quantitatively and qualitatively, and generalises better to poses not seen during training. We also introduce a fine-tuning step that allows to obtain competitive results for extreme identities, and allows to transfer simple clothing.
DualConv: Dual Mesh Convolutional Networks for Shape Correspondence
Mar 23, 2021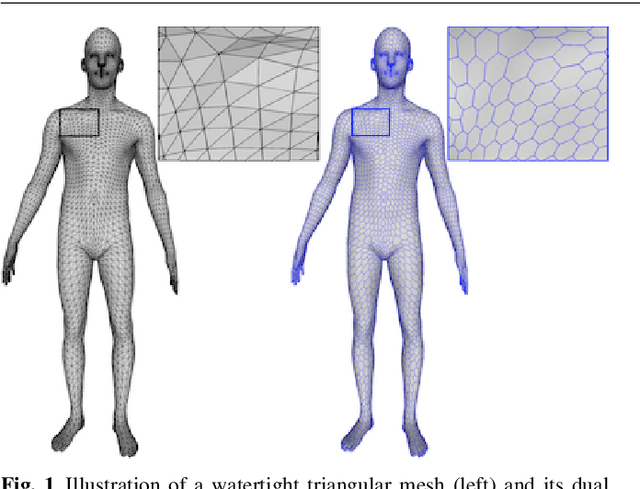
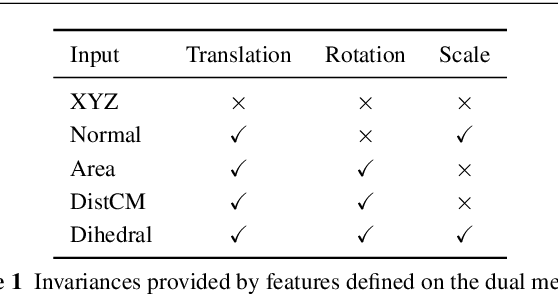
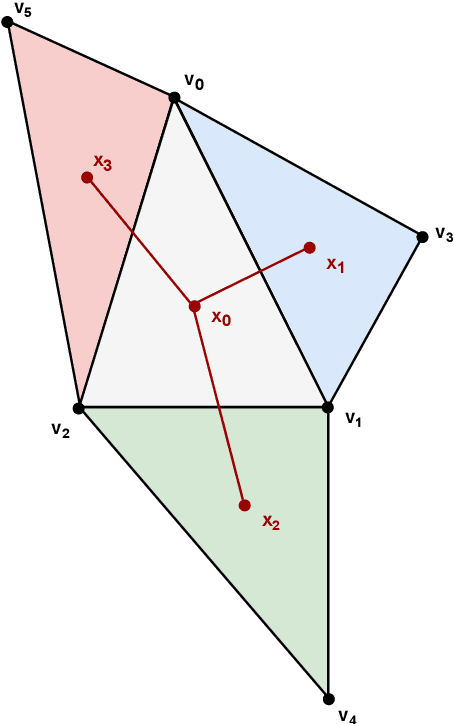
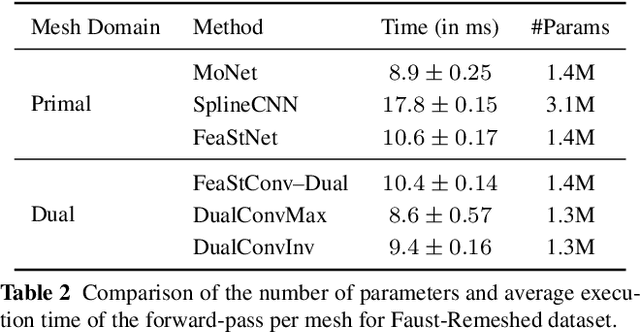
Convolutional neural networks have been extremely successful for 2D images and are readily extended to handle 3D voxel data. Meshes are a more common 3D shape representation that quantize the shape surface instead of the ambient space as with voxels, hence giving access to surface properties such as normals or appearances. The formulation of deep neural networks on meshes is, however, more complex since they are irregular data structures where the number of neighbors varies across vertices. While graph convolutional networks have previously been proposed over mesh vertex data, in this paper we explore how these networks can be extended to the dual face-based representation of triangular meshes, where nodes represent triangular faces in place of vertices. In comparison to the primal vertex mesh, its face dual offers several advantages, including, importantly, that the dual mesh is regular in the sense that each triangular face has exactly three neighbors. Moreover, the dual mesh suggests the use of a number of input features that are naturally defined over faces, such as surface normals and face areas. We evaluate the dual approach on the shape correspondence task on the FAUST human shape dataset and other versions of it with varying mesh topology. While applying generic graph convolutions to the dual mesh shows already improvements over primal mesh inputs, our experiments demonstrate that building additionally convolutional models that explicitly leverage the neighborhood size regularity of dual meshes enables learning shape representations that perform on par or better than previous approaches in terms of correspondence accuracy and mean geodesic error, while being more robust to topological changes in the meshes between training and testing shapes.
Cross-modal Deep Face Normals with Deactivable Skip Connections
Mar 30, 2020
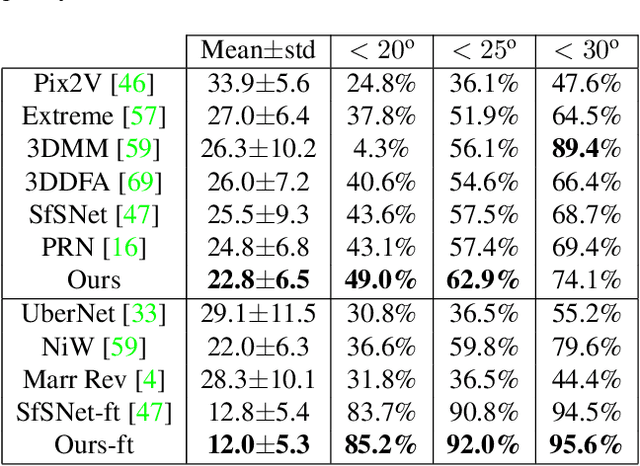
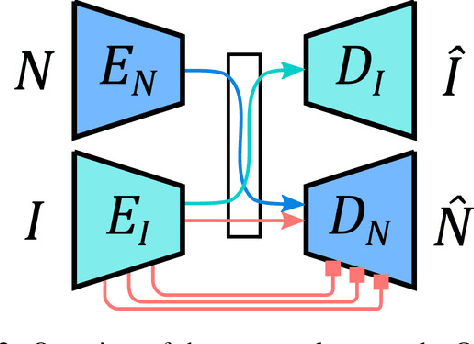
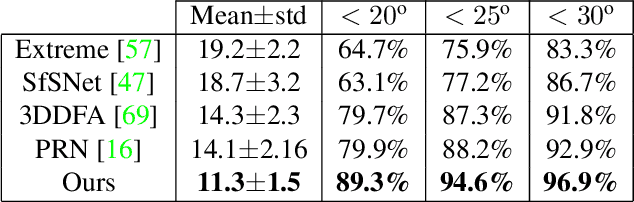
We present an approach for estimating surface normals from in-the-wild color images of faces. While data-driven strategies have been proposed for single face images, limited available ground truth data makes this problem difficult. To alleviate this issue, we propose a method that can leverage all available image and normal data, whether paired or not, thanks to a novel cross-modal learning architecture. In particular, we enable additional training with single modality data, either color or normal, by using two encoder-decoder networks with a shared latent space. The proposed architecture also enables face details to be transferred between the image and normal domains, given paired data, through skip connections between the image encoder and normal decoder. Core to our approach is a novel module that we call deactivable skip connections, which allows integrating both the auto-encoded and image-to-normal branches within the same architecture that can be trained end-to-end. This allows learning of a rich latent space that can accurately capture the normal information. We compare against state-of-the-art methods and show that our approach can achieve significant improvements, both quantitative and qualitative, with natural face images.