 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdrian Riekert
Non-convergence to global minimizers for Adam and stochastic gradient descent optimization and constructions of local minimizers in the training of artificial neural networks
Feb 07, 2024
Stochastic gradient descent (SGD) optimization methods such as the plain vanilla SGD method and the popular Adam optimizer are nowadays the method of choice in the training of artificial neural networks (ANNs). Despite the remarkable success of SGD methods in the ANN training in numerical simulations, it remains in essentially all practical relevant scenarios an open problem to rigorously explain why SGD methods seem to succeed to train ANNs. In particular, in most practically relevant supervised learning problems, it seems that SGD methods do with high probability not converge to global minimizers in the optimization landscape of the ANN training problem. Nevertheless, it remains an open problem of research to disprove the convergence of SGD methods to global minimizers. In this work we solve this research problem in the situation of shallow ANNs with the rectified linear unit (ReLU) and related activations with the standard mean square error loss by disproving in the training of such ANNs that SGD methods (such as the plain vanilla SGD, the momentum SGD, the AdaGrad, the RMSprop, and the Adam optimizers) can find a global minimizer with high probability. Even stronger, we reveal in the training of such ANNs that SGD methods do with high probability fail to converge to global minimizers in the optimization landscape. The findings of this work do, however, not disprove that SGD methods succeed to train ANNs since they do not exclude the possibility that SGD methods find good local minimizers whose risk values are close to the risk values of the global minimizers. In this context, another key contribution of this work is to establish the existence of a hierarchical structure of local minimizers with distinct risk values in the optimization landscape of ANN training problems with ReLU and related activations.
Deep neural network approximation of composite functions without the curse of dimensionality
Apr 12, 2023In this article we identify a general class of high-dimensional continuous functions that can be approximated by deep neural networks (DNNs) with the rectified linear unit (ReLU) activation without the curse of dimensionality. In other words, the number of DNN parameters grows at most polynomially in the input dimension and the approximation error. The functions in our class can be expressed as a potentially unbounded number of compositions of special functions which include products, maxima, and certain parallelized Lipschitz continuous functions.
Algorithmically Designed Artificial Neural Networks (ADANNs): Higher order deep operator learning for parametric partial differential equations
Feb 07, 2023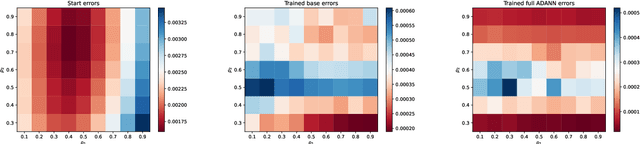
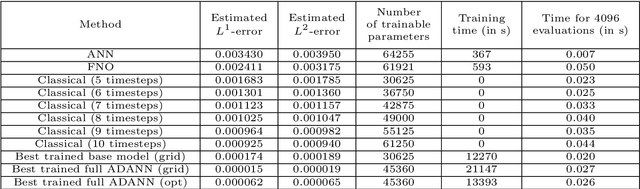
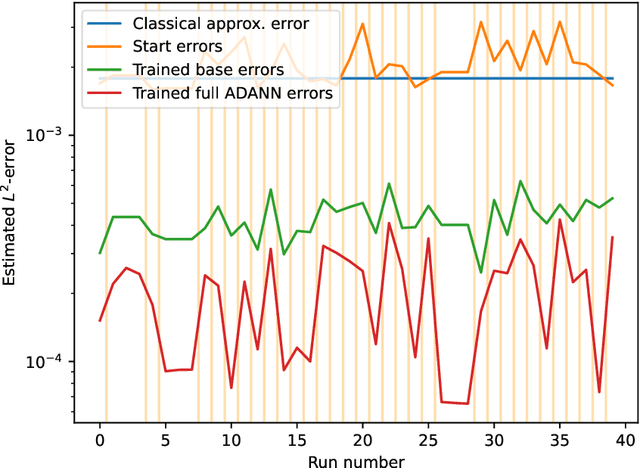
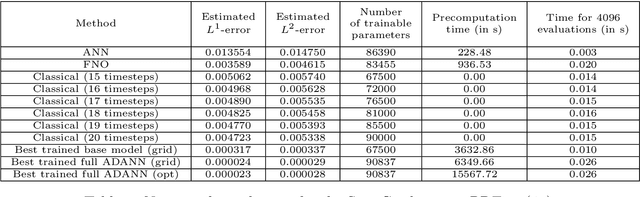
In this article we propose a new deep learning approach to solve parametric partial differential equations (PDEs) approximately. In particular, we introduce a new strategy to design specific artificial neural network (ANN) architectures in conjunction with specific ANN initialization schemes which are tailor-made for the particular scientific computing approximation problem under consideration. In the proposed approach we combine efficient classical numerical approximation techniques such as higher-order Runge-Kutta schemes with sophisticated deep (operator) learning methodologies such as the recently introduced Fourier neural operators (FNOs). Specifically, we introduce customized adaptions of existing standard ANN architectures together with specialized initializations for these ANN architectures so that at initialization we have that the ANNs closely mimic a chosen efficient classical numerical algorithm for the considered approximation problem. The obtained ANN architectures and their initialization schemes are thus strongly inspired by numerical algorithms as well as by popular deep learning methodologies from the literature and in that sense we refer to the introduced ANNs in conjunction with their tailor-made initialization schemes as Algorithmically Designed Artificial Neural Networks (ADANNs). We numerically test the proposed ADANN approach in the case of some parametric PDEs. In the tested numerical examples the ADANN approach significantly outperforms existing traditional approximation algorithms as well as existing deep learning methodologies from the literature.
Normalized gradient flow optimization in the training of ReLU artificial neural networks
Jul 13, 2022
The training of artificial neural networks (ANNs) is nowadays a highly relevant algorithmic procedure with many applications in science and industry. Roughly speaking, ANNs can be regarded as iterated compositions between affine linear functions and certain fixed nonlinear functions, which are usually multidimensional versions of a one-dimensional so-called activation function. The most popular choice of such a one-dimensional activation function is the rectified linear unit (ReLU) activation function which maps a real number to its positive part $ \mathbb{R} \ni x \mapsto \max\{ x, 0 \} \in \mathbb{R} $. In this article we propose and analyze a modified variant of the standard training procedure of such ReLU ANNs in the sense that we propose to restrict the negative gradient flow dynamics to a large submanifold of the ANN parameter space, which is a strict $ C^{ \infty } $-submanifold of the entire ANN parameter space that seems to enjoy better regularity properties than the entire ANN parameter space but which is also sufficiently large and sufficiently high dimensional so that it can represent all ANN realization functions that can be represented through the entire ANN parameter space. In the special situation of shallow ANNs with just one-dimensional ANN layers we also prove for every Lipschitz continuous target function that every gradient flow trajectory on this large submanifold of the ANN parameter space is globally bounded. For the standard gradient flow on the entire ANN parameter space with Lipschitz continuous target functions it remains an open problem of research to prove or disprove the global boundedness of gradient flow trajectories even in the situation of shallow ANNs with just one-dimensional ANN layers.
On the existence of global minima and convergence analyses for gradient descent methods in the training of deep neural networks
Dec 17, 2021

In this article we study fully-connected feedforward deep ReLU ANNs with an arbitrarily large number of hidden layers and we prove convergence of the risk of the GD optimization method with random initializations in the training of such ANNs under the assumption that the unnormalized probability density function of the probability distribution of the input data of the considered supervised learning problem is piecewise polynomial, under the assumption that the target function (describing the relationship between input data and the output data) is piecewise polynomial, and under the assumption that the risk function of the considered supervised learning problem admits at least one regular global minimum. In addition, in the special situation of shallow ANNs with just one hidden layer and one-dimensional input we also verify this assumption by proving in the training of such shallow ANNs that for every Lipschitz continuous target function there exists a global minimum in the risk landscape. Finally, in the training of deep ANNs with ReLU activation we also study solutions of gradient flow (GF) differential equations and we prove that every non-divergent GF trajectory converges with a polynomial rate of convergence to a critical point (in the sense of limiting Fr\'echet subdifferentiability). Our mathematical convergence analysis builds up on tools from real algebraic geometry such as the concept of semi-algebraic functions and generalized Kurdyka-Lojasiewicz inequalities, on tools from functional analysis such as the Arzel\`a-Ascoli theorem, on tools from nonsmooth analysis such as the concept of limiting Fr\'echet subgradients, as well as on the fact that the set of realization functions of shallow ReLU ANNs with fixed architecture forms a closed subset of the set of continuous functions revealed by Petersen et al.
Convergence proof for stochastic gradient descent in the training of deep neural networks with ReLU activation for constant target functions
Dec 13, 2021
In many numerical simulations stochastic gradient descent (SGD) type optimization methods perform very effectively in the training of deep neural networks (DNNs) but till this day it remains an open problem of research to provide a mathematical convergence analysis which rigorously explains the success of SGD type optimization methods in the training of DNNs. In this work we study SGD type optimization methods in the training of fully-connected feedforward DNNs with rectified linear unit (ReLU) activation. We first establish general regularity properties for the risk functions and their generalized gradient functions appearing in the training of such DNNs and, thereafter, we investigate the plain vanilla SGD optimization method in the training of such DNNs under the assumption that the target function under consideration is a constant function. Specifically, we prove under the assumption that the learning rates (the step sizes of the SGD optimization method) are sufficiently small but not $L^1$-summable and under the assumption that the target function is a constant function that the expectation of the riskof the considered SGD process converges in the training of such DNNs to zero as the number of SGD steps increases to infinity.
Existence, uniqueness, and convergence rates for gradient flows in the training of artificial neural networks with ReLU activation
Aug 18, 2021The training of artificial neural networks (ANNs) with rectified linear unit (ReLU) activation via gradient descent (GD) type optimization schemes is nowadays a common industrially relevant procedure. Till this day in the scientific literature there is in general no mathematical convergence analysis which explains the numerical success of GD type optimization schemes in the training of ANNs with ReLU activation. GD type optimization schemes can be regarded as temporal discretization methods for the gradient flow (GF) differential equations associated to the considered optimization problem and, in view of this, it seems to be a natural direction of research to first aim to develop a mathematical convergence theory for time-continuous GF differential equations and, thereafter, to aim to extend such a time-continuous convergence theory to implementable time-discrete GD type optimization methods. In this article we establish two basic results for GF differential equations in the training of fully-connected feedforward ANNs with one hidden layer and ReLU activation. In the first main result of this article we establish in the training of such ANNs under the assumption that the probability distribution of the input data of the considered supervised learning problem is absolutely continuous with a bounded density function that every GF differential equation admits for every initial value a solution which is also unique among a suitable class of solutions. In the second main result of this article we prove in the training of such ANNs under the assumption that the target function and the density function of the probability distribution of the input data are piecewise polynomial that every non-divergent GF trajectory converges with an appropriate rate of convergence to a critical point and that the risk of the non-divergent GF trajectory converges with rate 1 to the risk of the critical point.
A proof of convergence for the gradient descent optimization method with random initializations in the training of neural networks with ReLU activation for piecewise linear target functions
Aug 10, 2021Gradient descent (GD) type optimization methods are the standard instrument to train artificial neural networks (ANNs) with rectified linear unit (ReLU) activation. Despite the great success of GD type optimization methods in numerical simulations for the training of ANNs with ReLU activation, it remains - even in the simplest situation of the plain vanilla GD optimization method with random initializations and ANNs with one hidden layer - an open problem to prove (or disprove) the conjecture that the risk of the GD optimization method converges in the training of such ANNs to zero as the width of the ANNs, the number of independent random initializations, and the number of GD steps increase to infinity. In this article we prove this conjecture in the situation where the probability distribution of the input data is equivalent to the continuous uniform distribution on a compact interval, where the probability distributions for the random initializations of the ANN parameters are standard normal distributions, and where the target function under consideration is continuous and piecewise affine linear. Roughly speaking, the key ingredients in our mathematical convergence analysis are (i) to prove that suitable sets of global minima of the risk functions are \emph{twice continuously differentiable submanifolds of the ANN parameter spaces}, (ii) to prove that the Hessians of the risk functions on these sets of global minima satisfy an appropriate \emph{maximal rank condition}, and, thereafter, (iii) to apply the machinery in [Fehrman, B., Gess, B., Jentzen, A., Convergence rates for the stochastic gradient descent method for non-convex objective functions. J. Mach. Learn. Res. 21(136): 1--48, 2020] to establish convergence of the GD optimization method with random initializations.
Convergence analysis for gradient flows in the training of artificial neural networks with ReLU activation
Jul 09, 2021Gradient descent (GD) type optimization schemes are the standard methods to train artificial neural networks (ANNs) with rectified linear unit (ReLU) activation. Such schemes can be considered as discretizations of gradient flows (GFs) associated to the training of ANNs with ReLU activation and most of the key difficulties in the mathematical convergence analysis of GD type optimization schemes in the training of ANNs with ReLU activation seem to be already present in the dynamics of the corresponding GF differential equations. It is the key subject of this work to analyze such GF differential equations in the training of ANNs with ReLU activation and three layers (one input layer, one hidden layer, and one output layer). In particular, in this article we prove in the case where the target function is possibly multi-dimensional and continuous and in the case where the probability distribution of the input data is absolutely continuous with respect to the Lebesgue measure that the risk of every bounded GF trajectory converges to the risk of a critical point. In addition, in this article we show in the case of a 1-dimensional affine linear target function and in the case where the probability distribution of the input data coincides with the standard uniform distribution that the risk of every bounded GF trajectory converges to zero if the initial risk is sufficiently small. Finally, in the special situation where there is only one neuron on the hidden layer (1-dimensional hidden layer) we strengthen the above named result for affine linear target functions by proving that that the risk of every (not necessarily bounded) GF trajectory converges to zero if the initial risk is sufficiently small.
A proof of convergence for stochastic gradient descent in the training of artificial neural networks with ReLU activation for constant target functions
Apr 01, 2021In this article we study the stochastic gradient descent (SGD) optimization method in the training of fully-connected feedforward artificial neural networks with ReLU activation. The main result of this work proves that the risk of the SGD process converges to zero if the target function under consideration is constant. In the established convergence result the considered artificial neural networks consist of one input layer, one hidden layer, and one output layer (with $d \in \mathbb{N}$ neurons on the input layer, $H \in \mathbb{N}$ neurons on the hidden layer, and one neuron on the output layer). The learning rates of the SGD process are assumed to be sufficiently small and the input data used in the SGD process to train the artificial neural networks is assumed to be independent and identically distributed.