 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArnulf Jentzen
Non-convergence to global minimizers for Adam and stochastic gradient descent optimization and constructions of local minimizers in the training of artificial neural networks
Feb 07, 2024
Stochastic gradient descent (SGD) optimization methods such as the plain vanilla SGD method and the popular Adam optimizer are nowadays the method of choice in the training of artificial neural networks (ANNs). Despite the remarkable success of SGD methods in the ANN training in numerical simulations, it remains in essentially all practical relevant scenarios an open problem to rigorously explain why SGD methods seem to succeed to train ANNs. In particular, in most practically relevant supervised learning problems, it seems that SGD methods do with high probability not converge to global minimizers in the optimization landscape of the ANN training problem. Nevertheless, it remains an open problem of research to disprove the convergence of SGD methods to global minimizers. In this work we solve this research problem in the situation of shallow ANNs with the rectified linear unit (ReLU) and related activations with the standard mean square error loss by disproving in the training of such ANNs that SGD methods (such as the plain vanilla SGD, the momentum SGD, the AdaGrad, the RMSprop, and the Adam optimizers) can find a global minimizer with high probability. Even stronger, we reveal in the training of such ANNs that SGD methods do with high probability fail to converge to global minimizers in the optimization landscape. The findings of this work do, however, not disprove that SGD methods succeed to train ANNs since they do not exclude the possibility that SGD methods find good local minimizers whose risk values are close to the risk values of the global minimizers. In this context, another key contribution of this work is to establish the existence of a hierarchical structure of local minimizers with distinct risk values in the optimization landscape of ANN training problems with ReLU and related activations.
Mathematical Introduction to Deep Learning: Methods, Implementations, and Theory
Oct 31, 2023This book aims to provide an introduction to the topic of deep learning algorithms. We review essential components of deep learning algorithms in full mathematical detail including different artificial neural network (ANN) architectures (such as fully-connected feedforward ANNs, convolutional ANNs, recurrent ANNs, residual ANNs, and ANNs with batch normalization) and different optimization algorithms (such as the basic stochastic gradient descent (SGD) method, accelerated methods, and adaptive methods). We also cover several theoretical aspects of deep learning algorithms such as approximation capacities of ANNs (including a calculus for ANNs), optimization theory (including Kurdyka-{\L}ojasiewicz inequalities), and generalization errors. In the last part of the book some deep learning approximation methods for PDEs are reviewed including physics-informed neural networks (PINNs) and deep Galerkin methods. We hope that this book will be useful for students and scientists who do not yet have any background in deep learning at all and would like to gain a solid foundation as well as for practitioners who would like to obtain a firmer mathematical understanding of the objects and methods considered in deep learning.
Deep neural networks with ReLU, leaky ReLU, and softplus activation provably overcome the curse of dimensionality for Kolmogorov partial differential equations with Lipschitz nonlinearities in the $L^p$-sense
Sep 24, 2023Recently, several deep learning (DL) methods for approximating high-dimensional partial differential equations (PDEs) have been proposed. The interest that these methods have generated in the literature is in large part due to simulations which appear to demonstrate that such DL methods have the capacity to overcome the curse of dimensionality (COD) for PDEs in the sense that the number of computational operations they require to achieve a certain approximation accuracy $\varepsilon\in(0,\infty)$ grows at most polynomially in the PDE dimension $d\in\mathbb N$ and the reciprocal of $\varepsilon$. While there is thus far no mathematical result that proves that one of such methods is indeed capable of overcoming the COD, there are now a number of rigorous results in the literature that show that deep neural networks (DNNs) have the expressive power to approximate PDE solutions without the COD in the sense that the number of parameters used to describe the approximating DNN grows at most polynomially in both the PDE dimension $d\in\mathbb N$ and the reciprocal of the approximation accuracy $\varepsilon>0$. Roughly speaking, in the literature it is has been proved for every $T>0$ that solutions $u_d\colon [0,T]\times\mathbb R^d\to \mathbb R$, $d\in\mathbb N$, of semilinear heat PDEs with Lipschitz continuous nonlinearities can be approximated by DNNs with ReLU activation at the terminal time in the $L^2$-sense without the COD provided that the initial value functions $\mathbb R^d\ni x\mapsto u_d(0,x)\in\mathbb R$, $d\in\mathbb N$, can be approximated by ReLU DNNs without the COD. It is the key contribution of this work to generalize this result by establishing this statement in the $L^p$-sense with $p\in(0,\infty)$ and by allowing the activation function to be more general covering the ReLU, the leaky ReLU, and the softplus activation functions as special cases.
On the existence of minimizers in shallow residual ReLU neural network optimization landscapes
Feb 28, 2023
Many mathematical convergence results for gradient descent (GD) based algorithms employ the assumption that the GD process is (almost surely) bounded and, also in concrete numerical simulations, divergence of the GD process may slow down, or even completely rule out, convergence of the error function. In practical relevant learning problems, it thus seems to be advisable to design the ANN architectures in a way so that GD optimization processes remain bounded. The property of the boundedness of GD processes for a given learning problem seems, however, to be closely related to the existence of minimizers in the optimization landscape and, in particular, GD trajectories may escape to infinity if the infimum of the error function (objective function) is not attained in the optimization landscape. This naturally raises the question of the existence of minimizers in the optimization landscape and, in the situation of shallow residual ANNs with multi-dimensional input layers and multi-dimensional hidden layers with the ReLU activation, the main result of this work answers this question affirmatively for a general class of loss functions and all continuous target functions. In our proof of this statement, we propose a kind of closure of the search space, where the limits are called generalized responses, and, thereafter, we provide sufficient criteria for the loss function and the underlying probability distribution which ensure that all additional artificial generalized responses are suboptimal which finally allows us to conclude the existence of minimizers in the optimization landscape.
Algorithmically Designed Artificial Neural Networks (ADANNs): Higher order deep operator learning for parametric partial differential equations
Feb 07, 2023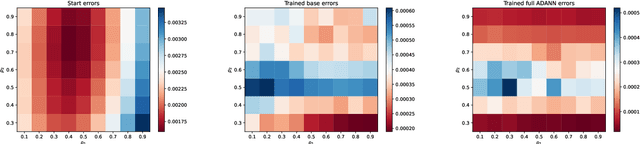
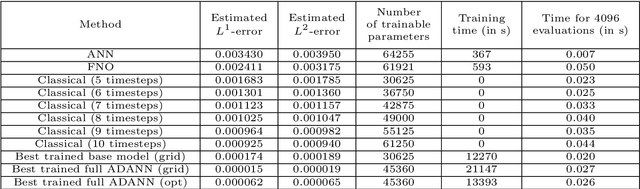
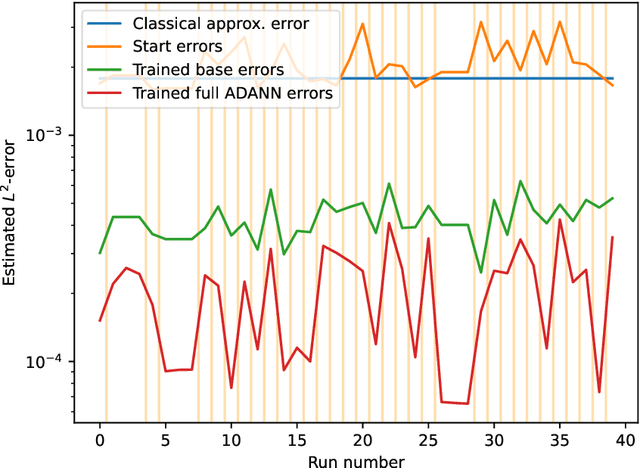
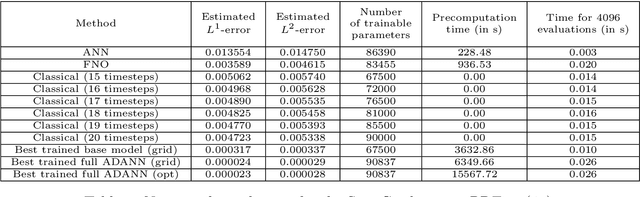
In this article we propose a new deep learning approach to solve parametric partial differential equations (PDEs) approximately. In particular, we introduce a new strategy to design specific artificial neural network (ANN) architectures in conjunction with specific ANN initialization schemes which are tailor-made for the particular scientific computing approximation problem under consideration. In the proposed approach we combine efficient classical numerical approximation techniques such as higher-order Runge-Kutta schemes with sophisticated deep (operator) learning methodologies such as the recently introduced Fourier neural operators (FNOs). Specifically, we introduce customized adaptions of existing standard ANN architectures together with specialized initializations for these ANN architectures so that at initialization we have that the ANNs closely mimic a chosen efficient classical numerical algorithm for the considered approximation problem. The obtained ANN architectures and their initialization schemes are thus strongly inspired by numerical algorithms as well as by popular deep learning methodologies from the literature and in that sense we refer to the introduced ANNs in conjunction with their tailor-made initialization schemes as Algorithmically Designed Artificial Neural Networks (ADANNs). We numerically test the proposed ADANN approach in the case of some parametric PDEs. In the tested numerical examples the ADANN approach significantly outperforms existing traditional approximation algorithms as well as existing deep learning methodologies from the literature.
The necessity of depth for artificial neural networks to approximate certain classes of smooth and bounded functions without the curse of dimensionality
Jan 19, 2023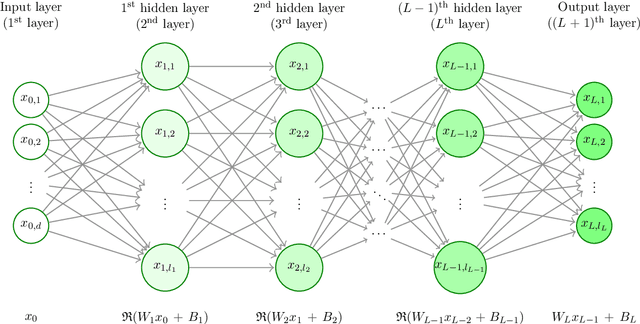
In this article we study high-dimensional approximation capacities of shallow and deep artificial neural networks (ANNs) with the rectified linear unit (ReLU) activation. In particular, it is a key contribution of this work to reveal that for all $a,b\in\mathbb{R}$ with $b-a\geq 7$ we have that the functions $[a,b]^d\ni x=(x_1,\dots,x_d)\mapsto\prod_{i=1}^d x_i\in\mathbb{R}$ for $d\in\mathbb{N}$ as well as the functions $[a,b]^d\ni x =(x_1,\dots, x_d)\mapsto\sin(\prod_{i=1}^d x_i) \in \mathbb{R} $ for $ d \in \mathbb{N} $ can neither be approximated without the curse of dimensionality by means of shallow ANNs nor insufficiently deep ANNs with ReLU activation but can be approximated without the curse of dimensionality by sufficiently deep ANNs with ReLU activation. We show that the product functions and the sine of the product functions are polynomially tractable approximation problems among the approximating class of deep ReLU ANNs with the number of hidden layers being allowed to grow in the dimension $ d \in \mathbb{N} $. We establish the above outlined statements not only for the product functions and the sine of the product functions but also for other classes of target functions, in particular, for classes of uniformly globally bounded $ C^{ \infty } $-functions with compact support on any $[a,b]^d$ with $a\in\mathbb{R}$, $b\in(a,\infty)$. Roughly speaking, in this work we lay open that simple approximation problems such as approximating the sine or cosine of products cannot be solved in standard implementation frameworks by shallow or insufficiently deep ANNs with ReLU activation in polynomial time, but can be approximated by sufficiently deep ReLU ANNs with the number of parameters growing at most polynomially.
Gradient descent provably escapes saddle points in the training of shallow ReLU networks
Aug 03, 2022Dynamical systems theory has recently been applied in optimization to prove that gradient descent algorithms avoid so-called strict saddle points of the loss function. However, in many modern machine learning applications, the required regularity conditions are not satisfied. In particular, this is the case for rectified linear unit (ReLU) networks. In this paper, we prove a variant of the relevant dynamical systems result, a center-stable manifold theorem, in which we relax some of the regularity requirements. Then, we verify that shallow ReLU networks fit into the new framework. Building on a classification of critical points of the square integral loss of shallow ReLU networks measured against an affine target function, we deduce that gradient descent avoids most saddle points. We proceed to prove convergence to global minima if the initialization is sufficiently good, which is expressed by an explicit threshold on the limiting loss.
Normalized gradient flow optimization in the training of ReLU artificial neural networks
Jul 13, 2022
The training of artificial neural networks (ANNs) is nowadays a highly relevant algorithmic procedure with many applications in science and industry. Roughly speaking, ANNs can be regarded as iterated compositions between affine linear functions and certain fixed nonlinear functions, which are usually multidimensional versions of a one-dimensional so-called activation function. The most popular choice of such a one-dimensional activation function is the rectified linear unit (ReLU) activation function which maps a real number to its positive part $ \mathbb{R} \ni x \mapsto \max\{ x, 0 \} \in \mathbb{R} $. In this article we propose and analyze a modified variant of the standard training procedure of such ReLU ANNs in the sense that we propose to restrict the negative gradient flow dynamics to a large submanifold of the ANN parameter space, which is a strict $ C^{ \infty } $-submanifold of the entire ANN parameter space that seems to enjoy better regularity properties than the entire ANN parameter space but which is also sufficiently large and sufficiently high dimensional so that it can represent all ANN realization functions that can be represented through the entire ANN parameter space. In the special situation of shallow ANNs with just one-dimensional ANN layers we also prove for every Lipschitz continuous target function that every gradient flow trajectory on this large submanifold of the ANN parameter space is globally bounded. For the standard gradient flow on the entire ANN parameter space with Lipschitz continuous target functions it remains an open problem of research to prove or disprove the global boundedness of gradient flow trajectories even in the situation of shallow ANNs with just one-dimensional ANN layers.
On bounds for norms of reparameterized ReLU artificial neural network parameters: sums of fractional powers of the Lipschitz norm control the network parameter vector
Jun 27, 2022
It is an elementary fact in the scientific literature that the Lipschitz norm of the realization function of a feedforward fully-connected rectified linear unit (ReLU) artificial neural network (ANN) can, up to a multiplicative constant, be bounded from above by sums of powers of the norm of the ANN parameter vector. Roughly speaking, in this work we reveal in the case of shallow ANNs that the converse inequality is also true. More formally, we prove that the norm of the equivalence class of ANN parameter vectors with the same realization function is, up to a multiplicative constant, bounded from above by the sum of powers of the Lipschitz norm of the ANN realization function (with the exponents $ 1/2 $ and $ 1 $). Moreover, we prove that this upper bound only holds when employing the Lipschitz norm but does neither hold for H\"older norms nor for Sobolev-Slobodeckij norms. Furthermore, we prove that this upper bound only holds for sums of powers of the Lipschitz norm with the exponents $ 1/2 $ and $ 1 $ but does not hold for the Lipschitz norm alone.
Deep learning approximations for non-local nonlinear PDEs with Neumann boundary conditions
May 07, 2022

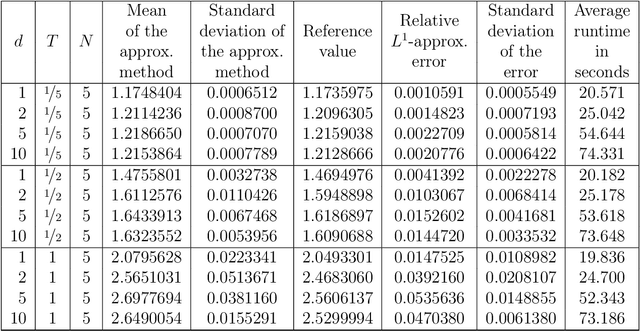
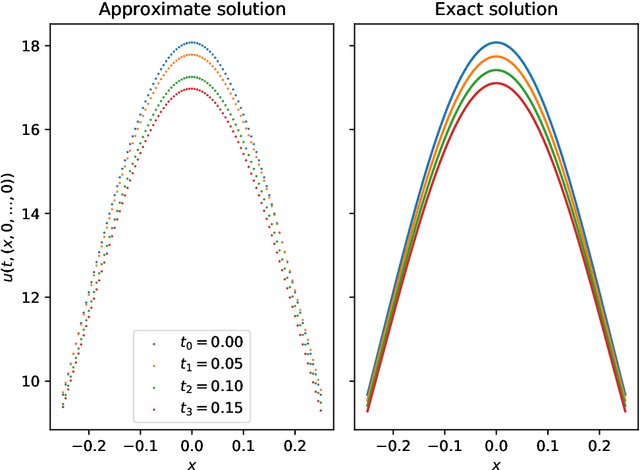
Nonlinear partial differential equations (PDEs) are used to model dynamical processes in a large number of scientific fields, ranging from finance to biology. In many applications standard local models are not sufficient to accurately account for certain non-local phenomena such as, e.g., interactions at a distance. In order to properly capture these phenomena non-local nonlinear PDE models are frequently employed in the literature. In this article we propose two numerical methods based on machine learning and on Picard iterations, respectively, to approximately solve non-local nonlinear PDEs. The proposed machine learning-based method is an extended variant of a deep learning-based splitting-up type approximation method previously introduced in the literature and utilizes neural networks to provide approximate solutions on a subset of the spatial domain of the solution. The Picard iterations-based method is an extended variant of the so-called full history recursive multilevel Picard approximation scheme previously introduced in the literature and provides an approximate solution for a single point of the domain. Both methods are mesh-free and allow non-local nonlinear PDEs with Neumann boundary conditions to be solved in high dimensions. In the two methods, the numerical difficulties arising due to the dimensionality of the PDEs are avoided by (i) using the correspondence between the expected trajectory of reflected stochastic processes and the solution of PDEs (given by the Feynman-Kac formula) and by (ii) using a plain vanilla Monte Carlo integration to handle the non-local term. We evaluate the performance of the two methods on five different PDEs arising in physics and biology. In all cases, the methods yield good results in up to 10 dimensions with short run times. Our work extends recently developed methods to overcome the curse of dimensionality in solving PDEs.