 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlessandro Sperduti
A Neural Rewriting System to Solve Algorithmic Problems
Feb 27, 2024
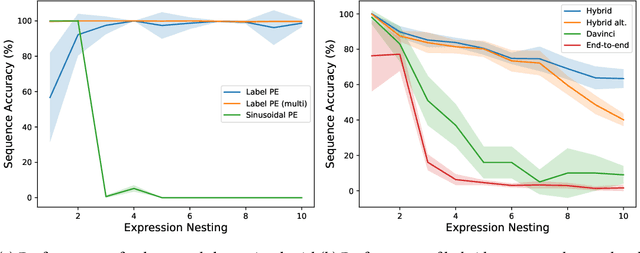
Modern neural network architectures still struggle to learn algorithmic procedures that require to systematically apply compositional rules to solve out-of-distribution problem instances. In this work, we propose an original approach to learn algorithmic tasks inspired by rewriting systems, a classic framework in symbolic artificial intelligence. We show that a rewriting system can be implemented as a neural architecture composed by specialized modules: the Selector identifies the target sub-expression to process, the Solver simplifies the sub-expression by computing the corresponding result, and the Combiner produces a new version of the original expression by replacing the sub-expression with the solution provided. We evaluate our model on three types of algorithmic tasks that require simplifying symbolic formulas involving lists, arithmetic, and algebraic expressions. We test the extrapolation capabilities of the proposed architecture using formulas involving a higher number of operands and nesting levels than those seen during training, and we benchmark its performance against the Neural Data Router, a recent model specialized for systematic generalization, and a state-of-the-art large language model (GPT-4) probed with advanced prompting strategies.
Benchmarking GPT-4 on Algorithmic Problems: A Systematic Evaluation of Prompting Strategies
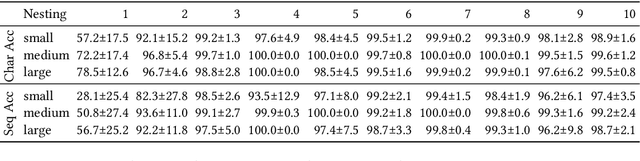
Feb 27, 2024Large Language Models (LLMs) have revolutionized the field of Natural Language Processing thanks to their ability to reuse knowledge acquired on massive text corpora on a wide variety of downstream tasks, with minimal (if any) tuning steps. At the same time, it has been repeatedly shown that LLMs lack systematic generalization, which allows to extrapolate the learned statistical regularities outside the training distribution. In this work, we offer a systematic benchmarking of GPT-4, one of the most advanced LLMs available, on three algorithmic tasks characterized by the possibility to control the problem difficulty with two parameters. We compare the performance of GPT-4 with that of its predecessor (GPT-3.5) and with a variant of the Transformer-Encoder architecture recently introduced to solve similar tasks, the Neural Data Router. We find that the deployment of advanced prompting techniques allows GPT-4 to reach superior accuracy on all tasks, demonstrating that state-of-the-art LLMs constitute a very strong baseline also in challenging tasks that require systematic generalization.
A Hybrid System for Systematic Generalization in Simple Arithmetic Problems
Jun 29, 2023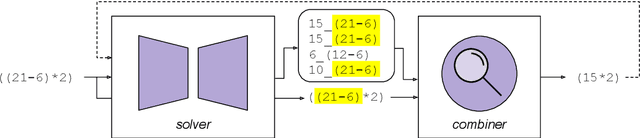

Solving symbolic reasoning problems that require compositionality and systematicity is considered one of the key ingredients of human intelligence. However, symbolic reasoning is still a great challenge for deep learning models, which often cannot generalize the reasoning pattern to out-of-distribution test cases. In this work, we propose a hybrid system capable of solving arithmetic problems that require compositional and systematic reasoning over sequences of symbols. The model acquires such a skill by learning appropriate substitution rules, which are applied iteratively to the input string until the expression is completely resolved. We show that the proposed system can accurately solve nested arithmetical expressions even when trained only on a subset including the simplest cases, significantly outperforming both a sequence-to-sequence model trained end-to-end and a state-of-the-art large language model.
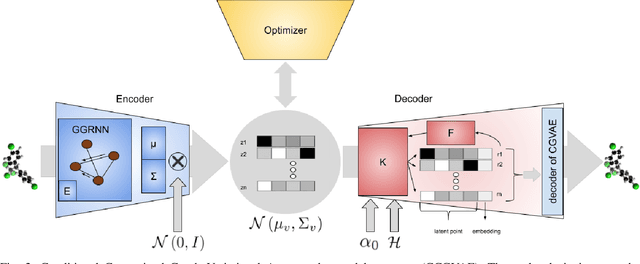
RGCVAE: Relational Graph Conditioned Variational Autoencoder for Molecule Design
May 19, 2023
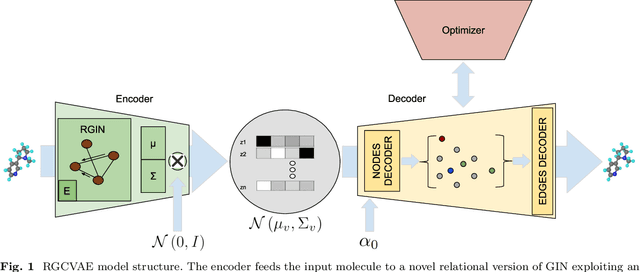
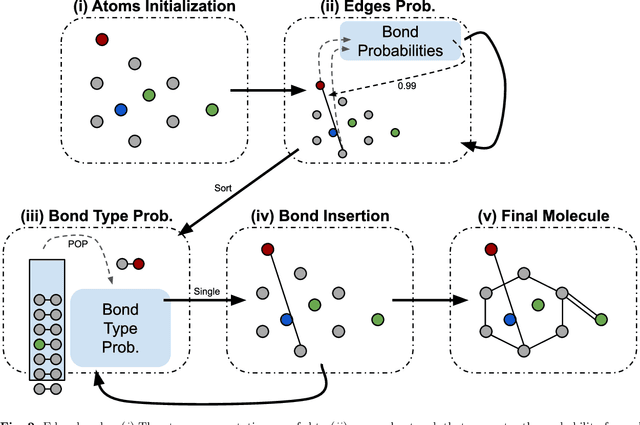
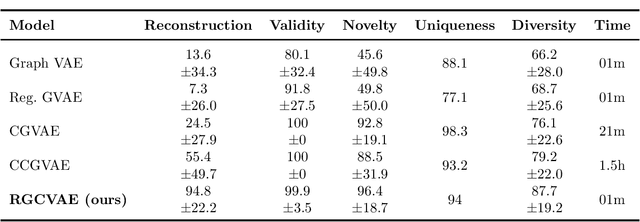
Identifying molecules that exhibit some pre-specified properties is a difficult problem to solve. In the last few years, deep generative models have been used for molecule generation. Deep Graph Variational Autoencoders are among the most powerful machine learning tools with which it is possible to address this problem. However, existing methods struggle in capturing the true data distribution and tend to be computationally expensive. In this work, we propose RGCVAE, an efficient and effective Graph Variational Autoencoder based on: (i) an encoding network exploiting a new powerful Relational Graph Isomorphism Network; (ii) a novel probabilistic decoding component. Compared to several state-of-the-art VAE methods on two widely adopted datasets, RGCVAE shows state-of-the-art molecule generation performance while being significantly faster to train.
Weakly-Supervised Visual-Textual Grounding with Semantic Prior Refinement
May 18, 2023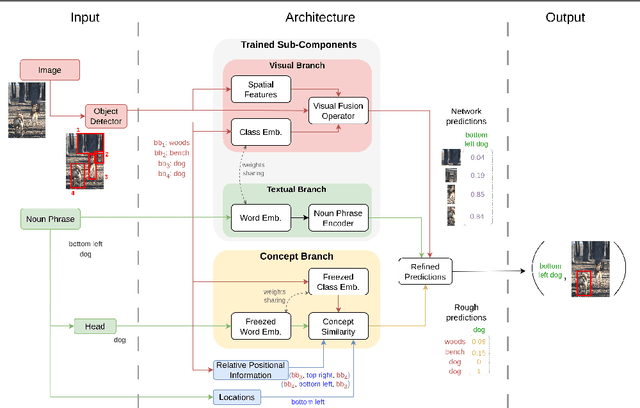
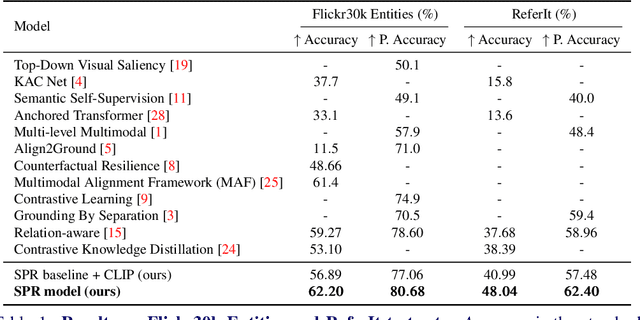
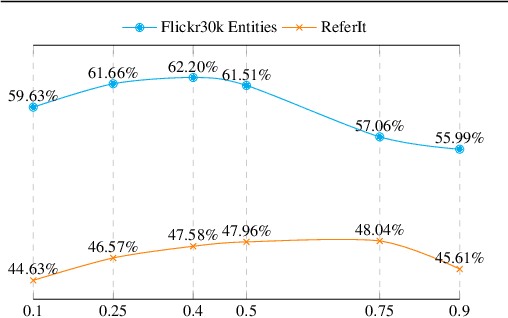
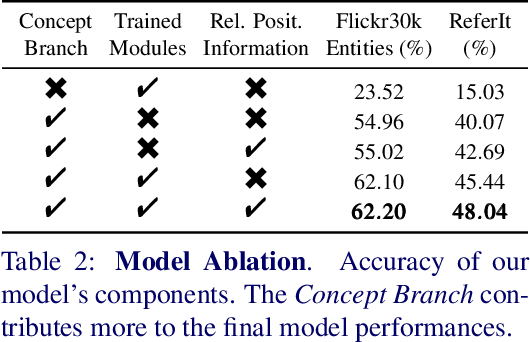
Using only image-sentence pairs, weakly-supervised visual-textual grounding aims to learn region-phrase correspondences of the respective entity mentions. Compared to the supervised approach, learning is more difficult since bounding boxes and textual phrases correspondences are unavailable. In light of this, we propose the Semantic Prior Refinement Model (SPRM), whose predictions are obtained by combining the output of two main modules. The first untrained module aims to return a rough alignment between textual phrases and bounding boxes. The second trained module is composed of two sub-components that refine the rough alignment to improve the accuracy of the final phrase-bounding box alignments. The model is trained to maximize the multimodal similarity between an image and a sentence, while minimizing the multimodal similarity of the same sentence and a new unrelated image, carefully selected to help the most during training. Our approach shows state-of-the-art results on two popular datasets, Flickr30k Entities and ReferIt, shining especially on ReferIt with a 9.6% absolute improvement. Moreover, thanks to the untrained component, it reaches competitive performances just using a small fraction of training examples.
A Better Loss for Visual-Textual Grounding
Aug 11, 2021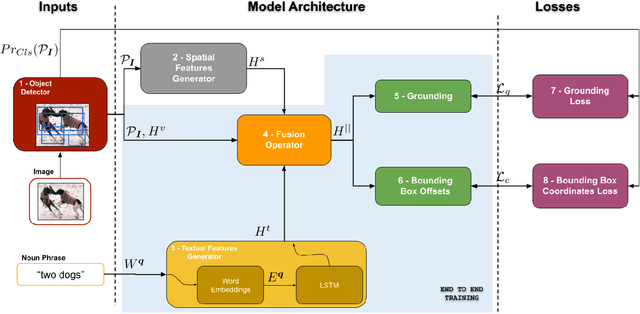
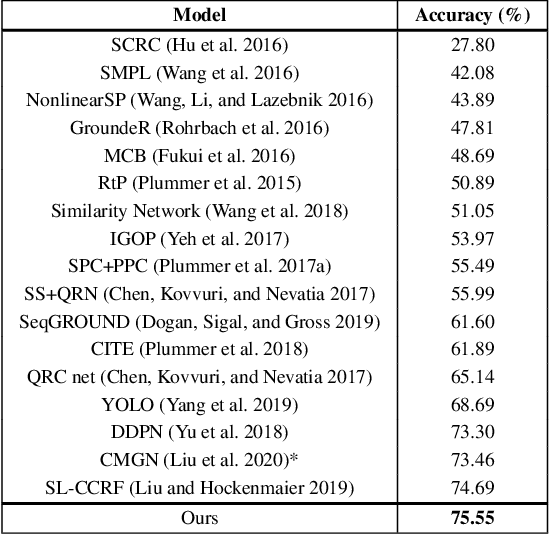

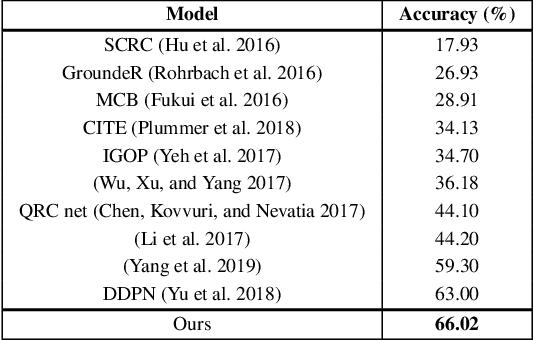
Given a textual phrase and an image, the visual grounding problem is defined as the task of locating the content of the image referenced by the sentence. It is a challenging task that has several real-world applications in human-computer interaction, image-text reference resolution, and video-text reference resolution. In the last years, several works have addressed this problem with heavy and complex models that try to capture visual-textual dependencies better than before. These models are typically constituted by two main components that focus on how to learn useful multi-modal features for grounding and how to improve the predicted bounding box of the visual mention, respectively. Finding the right learning balance between these two sub-tasks is not easy, and the current models are not necessarily optimal with respect to this issue. In this work, we propose a model that, although using a simple multi-modal feature fusion component, is able to achieve a higher accuracy than state-of-the-art models thanks to the adoption of a more effective loss function, based on the classes probabilities, that reach, in the considered datasets, a better learning balance between the two sub-tasks mentioned above.
Simple Graph Convolutional Networks
Jun 10, 2021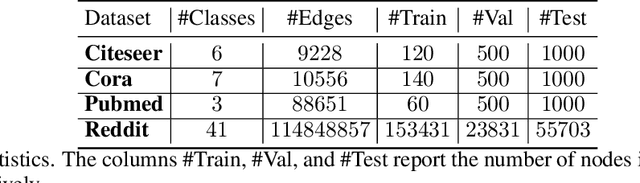
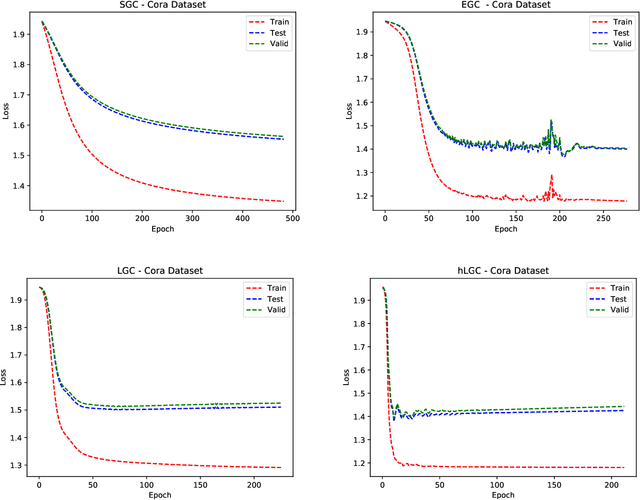

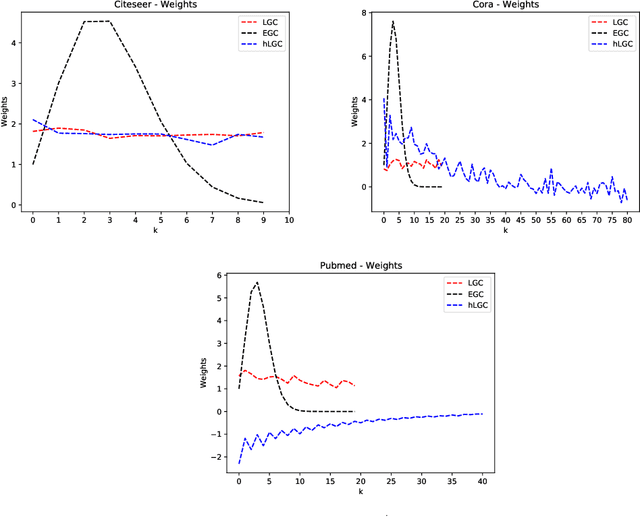
Many neural networks for graphs are based on the graph convolution operator, proposed more than a decade ago. Since then, many alternative definitions have been proposed, that tend to add complexity (and non-linearity) to the model. In this paper, we follow the opposite direction by proposing simple graph convolution operators, that can be implemented in single-layer graph convolutional networks. We show that our convolution operators are more theoretically grounded than many proposals in literature, and exhibit state-of-the-art predictive performance on the considered benchmark datasets.
Conditional Variational Capsule Network for Open Set Recognition
Apr 19, 2021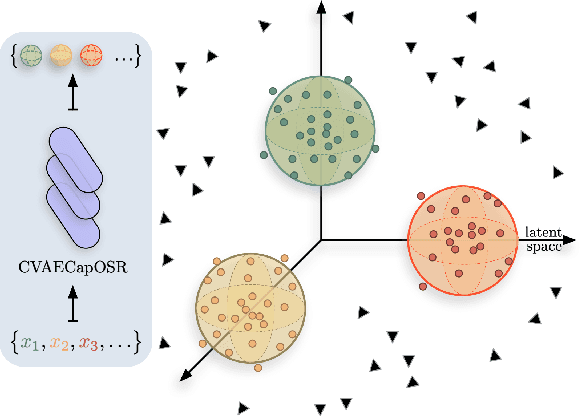
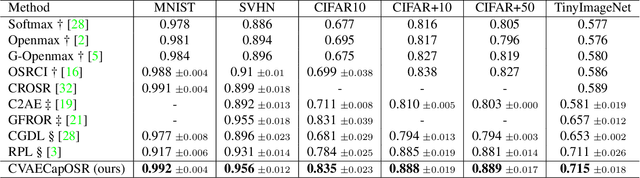
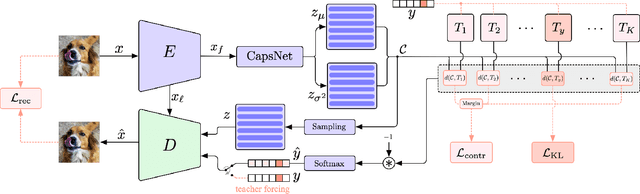

In open set recognition, a classifier has to detect unknown classes that are not known at training time. In order to recognize new classes, the classifier has to project the input samples of known classes in very compact and separated regions of the features space in order to discriminate outlier samples of unknown classes. Recently proposed Capsule Networks have shown to outperform alternatives in many fields, particularly in image recognition, however they have not been fully applied yet to open-set recognition. In capsule networks, scalar neurons are replaced by capsule vectors or matrices, whose entries represent different properties of objects. In our proposal, during training, capsules features of the same known class are encouraged to match a pre-defined gaussian, one for each class. To this end, we use the variational autoencoder framework, with a set of gaussian prior as the approximation for the posterior distribution. In this way, we are able to control the compactness of the features of the same class around the center of the gaussians, thus controlling the ability of the classifier in detecting samples from unknown classes. We conducted several experiments and ablation of our model, obtaining state of the art results on different datasets in the open set recognition and unknown detection tasks.
Short-Term Memory Optimization in Recurrent Neural Networks by Autoencoder-based Initialization
Nov 05, 2020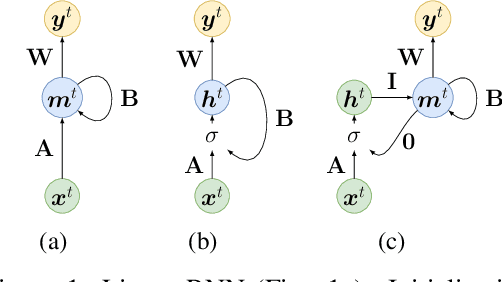
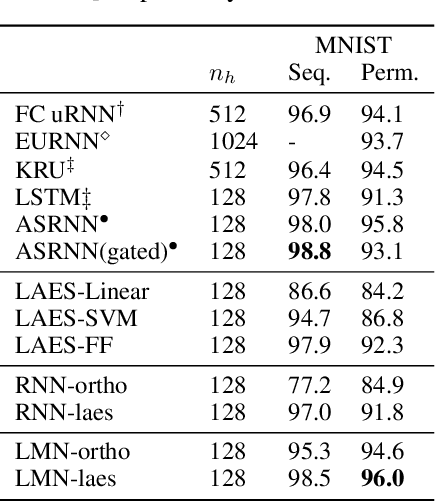
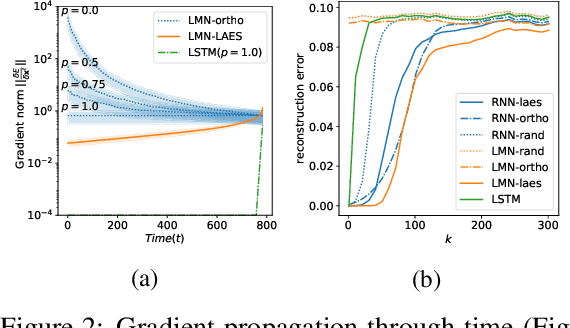
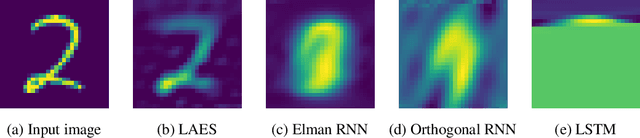
Training RNNs to learn long-term dependencies is difficult due to vanishing gradients. We explore an alternative solution based on explicit memorization using linear autoencoders for sequences, which allows to maximize the short-term memory and that can be solved with a closed-form solution without backpropagation. We introduce an initialization schema that pretrains the weights of a recurrent neural network to approximate the linear autoencoder of the input sequences and we show how such pretraining can better support solving hard classification tasks with long sequences. We test our approach on sequential and permuted MNIST. We show that the proposed approach achieves a much lower reconstruction error for long sequences and a better gradient propagation during the finetuning phase.
Conditional Constrained Graph Variational Autoencoders for Molecule Design
Sep 01, 2020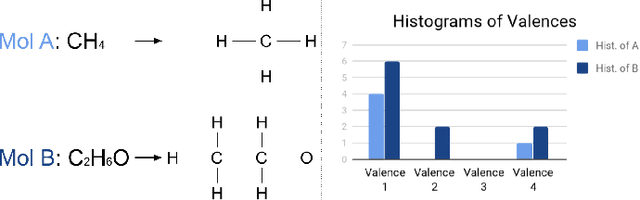
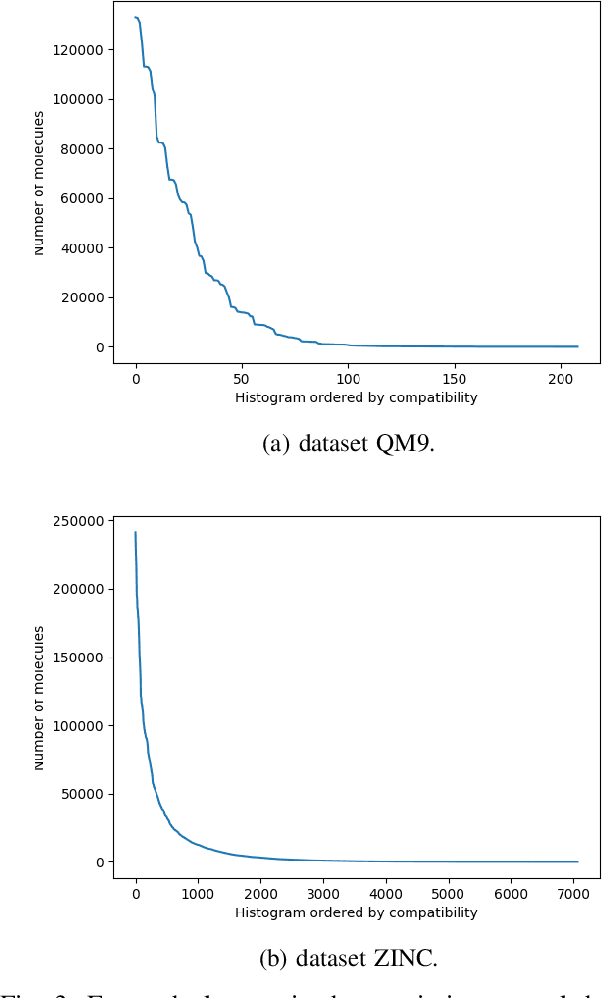

In recent years, deep generative models for graphs have been used to generate new molecules. These models have produced good results, leading to several proposals in the literature. However, these models may have troubles learning some of the complex laws governing the chemical world. In this work, we explore the usage of the histogram of atom valences to drive the generation of molecules in such models. We present Conditional Constrained Graph Variational Autoencoder (CCGVAE), a model that implements this key-idea in a state-of-the-art model, and shows improved results on several evaluation metrics on two commonly adopted datasets for molecule generation.