 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLamberto Ballan
Following the Human Thread in Social Navigation
Apr 17, 2024
The success of collaboration between humans and robots in shared environments relies on the robot's real-time adaptation to human motion. Specifically, in Social Navigation, the agent should be close enough to assist but ready to back up to let the human move freely, avoiding collisions. Human trajectories emerge as crucial cues in Social Navigation, but they are partially observable from the robot's egocentric view and computationally complex to process. We propose the first Social Dynamics Adaptation model (SDA) based on the robot's state-action history to infer the social dynamics. We propose a two-stage Reinforcement Learning framework: the first learns to encode the human trajectories into social dynamics and learns a motion policy conditioned on this encoded information, the current status, and the previous action. Here, the trajectories are fully visible, i.e., assumed as privileged information. In the second stage, the trained policy operates without direct access to trajectories. Instead, the model infers the social dynamics solely from the history of previous actions and statuses in real-time. Tested on the novel Habitat 3.0 platform, SDA sets a novel state of the art (SoA) performance in finding and following humans.
Weakly-Supervised Visual-Textual Grounding with Semantic Prior Refinement
May 18, 2023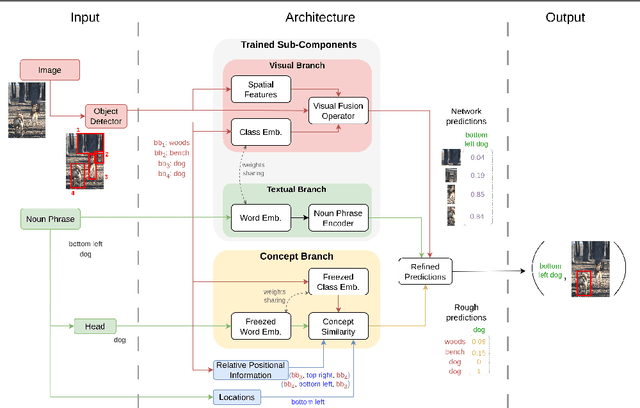
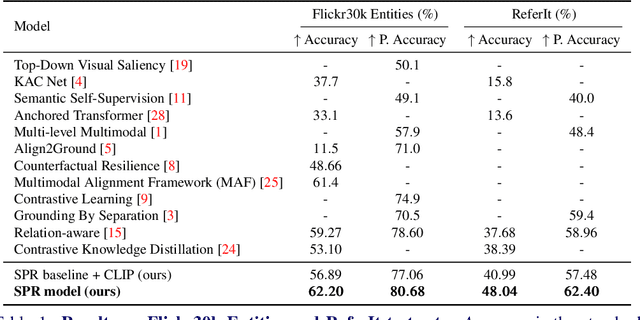
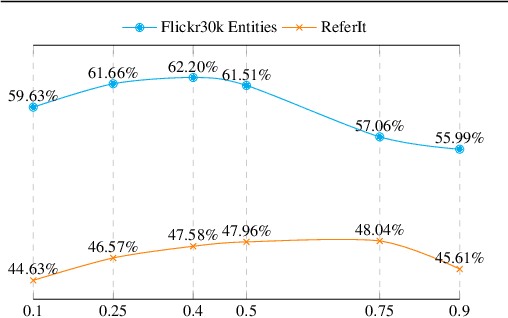
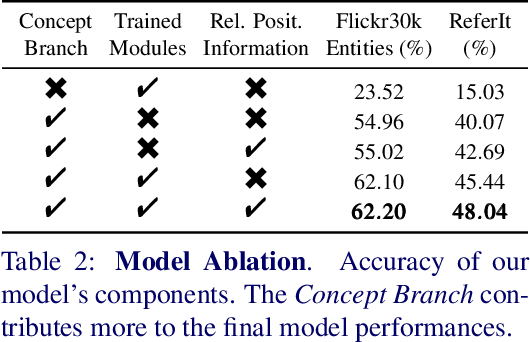
Using only image-sentence pairs, weakly-supervised visual-textual grounding aims to learn region-phrase correspondences of the respective entity mentions. Compared to the supervised approach, learning is more difficult since bounding boxes and textual phrases correspondences are unavailable. In light of this, we propose the Semantic Prior Refinement Model (SPRM), whose predictions are obtained by combining the output of two main modules. The first untrained module aims to return a rough alignment between textual phrases and bounding boxes. The second trained module is composed of two sub-components that refine the rough alignment to improve the accuracy of the final phrase-bounding box alignments. The model is trained to maximize the multimodal similarity between an image and a sentence, while minimizing the multimodal similarity of the same sentence and a new unrelated image, carefully selected to help the most during training. Our approach shows state-of-the-art results on two popular datasets, Flickr30k Entities and ReferIt, shining especially on ReferIt with a 9.6% absolute improvement. Moreover, thanks to the untrained component, it reaches competitive performances just using a small fraction of training examples.
Distilling Knowledge for Short-to-Long Term Trajectory Prediction
May 15, 2023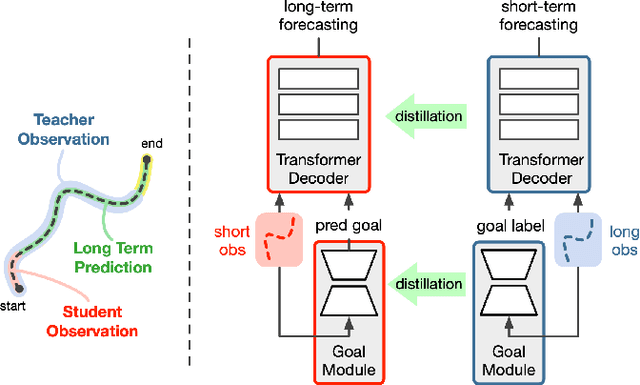
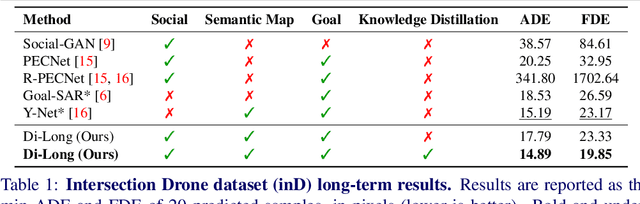
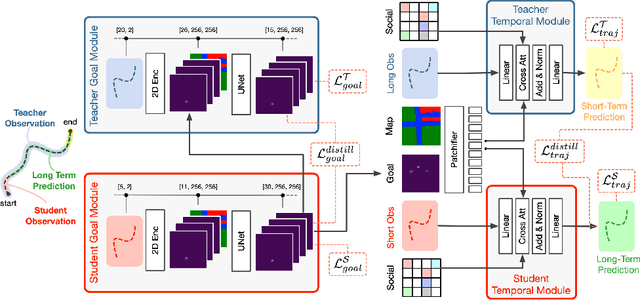
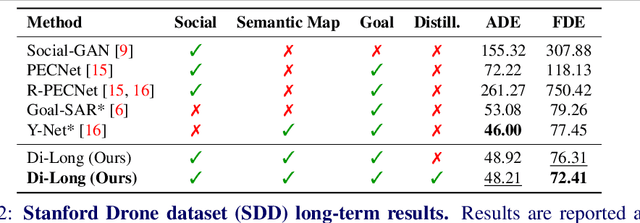
Long-term trajectory forecasting is a challenging problem in the field of computer vision and machine learning. In this paper, we propose a new method dubbed Di-Long ("Distillation for Long-Term trajectory") for long-term trajectory forecasting, which is based on knowledge distillation. Our approach involves training a student network to solve the long-term trajectory forecasting problem, whereas the teacher network from which the knowledge is distilled has a longer observation, and solves a short-term trajectory prediction problem by regularizing the student's predictions. Specifically, we use a teacher model to generate plausible trajectories for a shorter time horizon, and then distill the knowledge from the teacher model to a student model that solves the problem for a much higher time horizon. Our experiments show that the proposed Di-Long approach is beneficial for long-term forecasting, and our model achieves state-of-the-art performance on the Intersection Drone Dataset (inD) and the Stanford Drone Dataset (SDD).
Exploiting Socially-Aware Tasks for Embodied Social Navigation
Dec 01, 2022
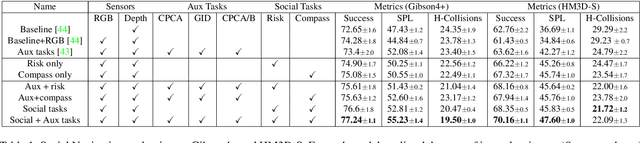

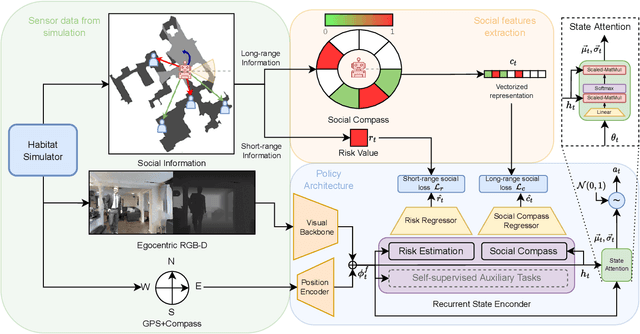
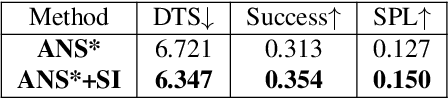
Learning how to navigate among humans in an occluded and spatially constrained indoor environment, is a key ability required to embodied agent to be integrated into our society. In this paper, we propose an end-to-end architecture that exploits Socially-Aware Tasks (referred as to Risk and Social Compass) to inject into a reinforcement learning navigation policy the ability to infer common-sense social behaviors. To this end, our tasks exploit the notion of immediate and future dangers of collision. Furthermore, we propose an evaluation protocol specifically designed for the Social Navigation Task in simulated environments. This is done to capture fine-grained features and characteristics of the policy by analyzing the minimal unit of human-robot spatial interaction, called Encounter. We validate our approach on Gibson4+ and Habitat-Matterport3D datasets.
TAMFormer: Multi-Modal Transformer with Learned Attention Mask for Early Intent Prediction
Oct 26, 2022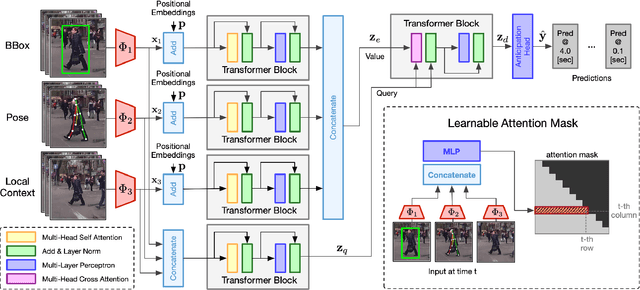

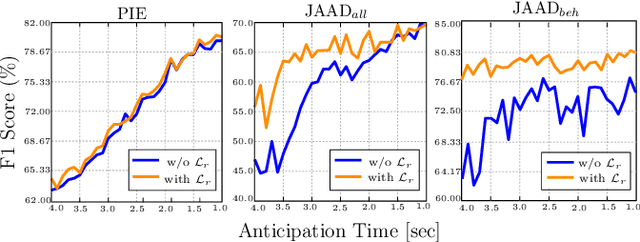
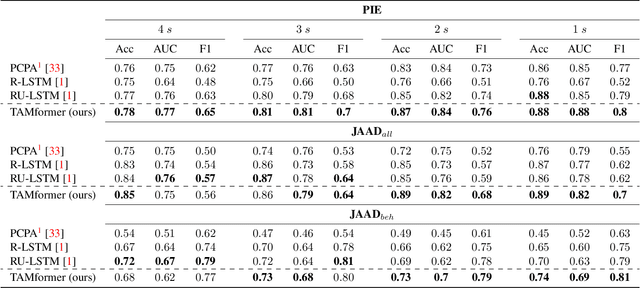
Human intention prediction is a growing area of research where an activity in a video has to be anticipated by a vision-based system. To this end, the model creates a representation of the past, and subsequently, it produces future hypotheses about upcoming scenarios. In this work, we focus on pedestrians' early intention prediction in which, from a current observation of an urban scene, the model predicts the future activity of pedestrians that approach the street. Our method is based on a multi-modal transformer that encodes past observations and produces multiple predictions at different anticipation times. Moreover, we propose to learn the attention masks of our transformer-based model (Temporal Adaptive Mask Transformer) in order to weigh differently present and past temporal dependencies. We investigate our method on several public benchmarks for early intention prediction, improving the prediction performances at different anticipation times compared to the previous works.
Where are my Neighbors? Exploiting Patches Relations in Self-Supervised Vision Transformer
Jun 01, 2022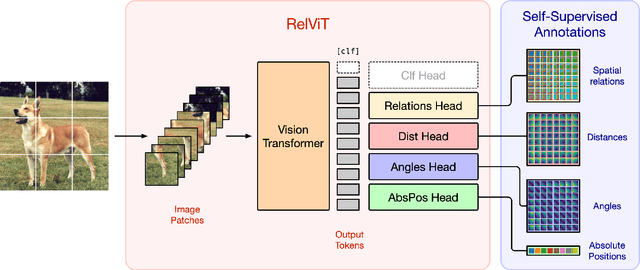
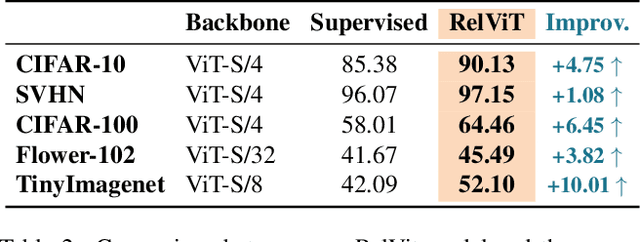
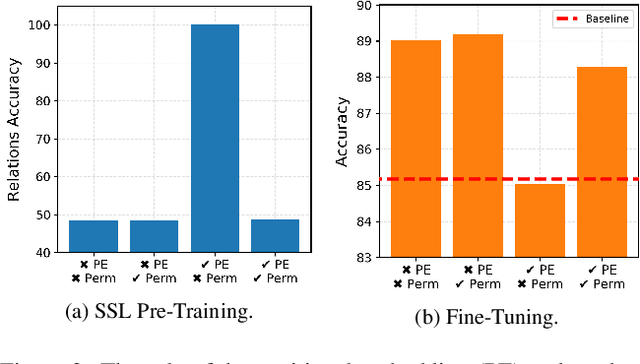
Vision Transformers (ViTs) enabled the use of transformer architecture on vision tasks showing impressive performances when trained on big datasets. However, on relatively small datasets, ViTs are less accurate given their lack of inductive bias. To this end, we propose a simple but still effective self-supervised learning (SSL) strategy to train ViTs, that without any external annotation, can significantly improve the results. Specifically, we define a set of SSL tasks based on relations of image patches that the model has to solve before or jointly during the downstream training. Differently from ViT, our RelViT model optimizes all the output tokens of the transformer encoder that are related to the image patches, thus exploiting more training signal at each training step. We investigated our proposed methods on several image benchmarks finding that RelViT improves the SSL state-of-the-art methods by a large margin, especially on small datasets.
Goal-driven Self-Attentive Recurrent Networks for Trajectory Prediction
Apr 25, 2022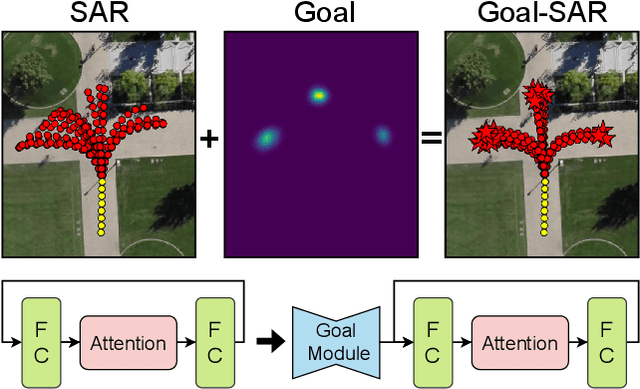
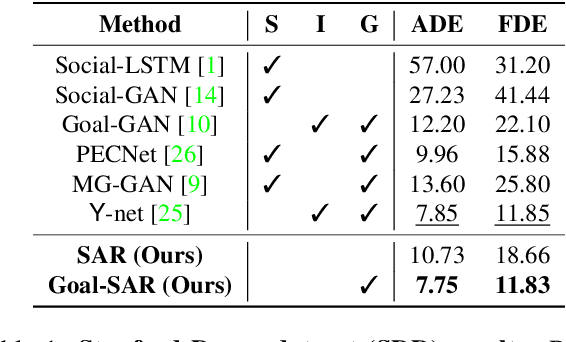
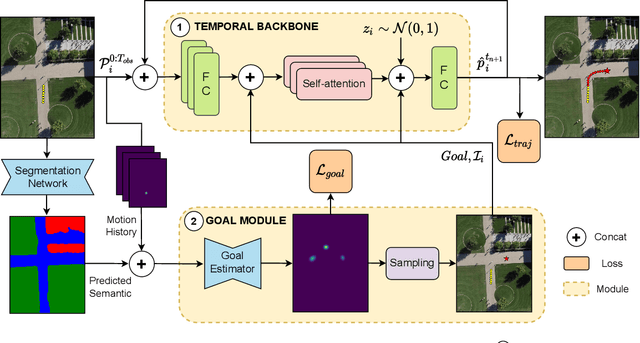
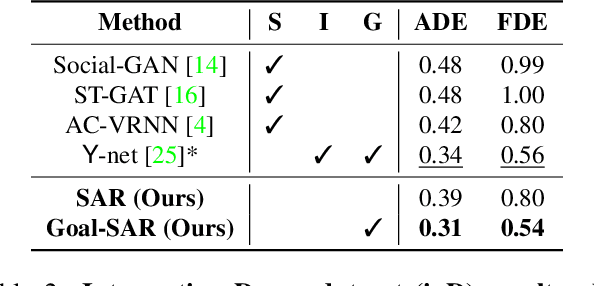
Human trajectory forecasting is a key component of autonomous vehicles, social-aware robots and advanced video-surveillance applications. This challenging task typically requires knowledge about past motion, the environment and likely destination areas. In this context, multi-modality is a fundamental aspect and its effective modeling can be beneficial to any architecture. Inferring accurate trajectories is nevertheless challenging, due to the inherently uncertain nature of the future. To overcome these difficulties, recent models use different inputs and propose to model human intentions using complex fusion mechanisms. In this respect, we propose a lightweight attention-based recurrent backbone that acts solely on past observed positions. Although this backbone already provides promising results, we demonstrate that its prediction accuracy can be improved considerably when combined with a scene-aware goal-estimation module. To this end, we employ a common goal module, based on a U-Net architecture, which additionally extracts semantic information to predict scene-compliant destinations. We conduct extensive experiments on publicly-available datasets (i.e. SDD, inD, ETH/UCY) and show that our approach performs on par with state-of-the-art techniques while reducing model complexity.
How many Observations are Enough? Knowledge Distillation for Trajectory Forecasting
Mar 09, 2022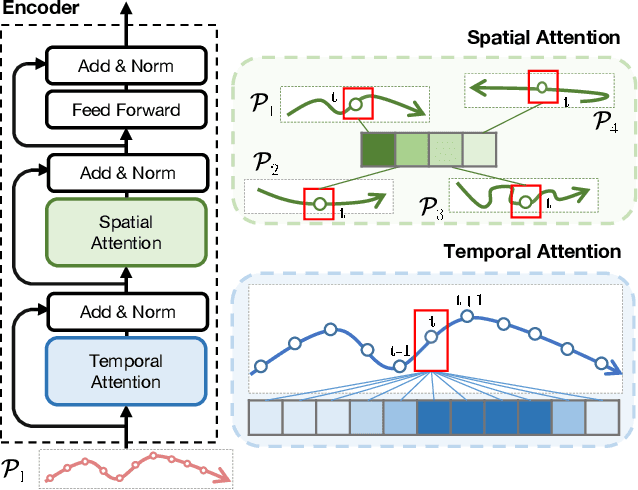
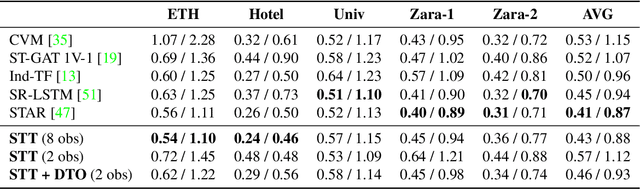
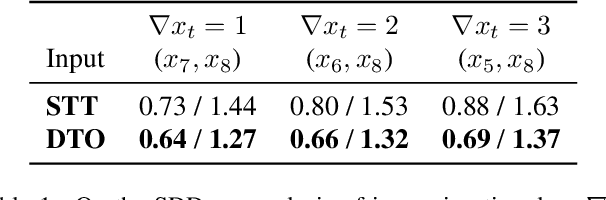
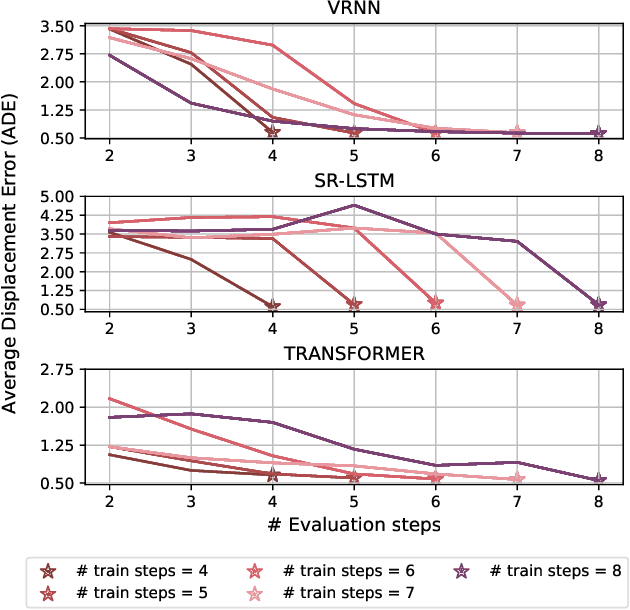
Accurate prediction of future human positions is an essential task for modern video-surveillance systems. Current state-of-the-art models usually rely on a "history" of past tracked locations (e.g., 3 to 5 seconds) to predict a plausible sequence of future locations (e.g., up to the next 5 seconds). We feel that this common schema neglects critical traits of realistic applications: as the collection of input trajectories involves machine perception (i.e., detection and tracking), incorrect detection and fragmentation errors may accumulate in crowded scenes, leading to tracking drifts. On this account, the model would be fed with corrupted and noisy input data, thus fatally affecting its prediction performance. In this regard, we focus on delivering accurate predictions when only few input observations are used, thus potentially lowering the risks associated with automatic perception. To this end, we conceive a novel distillation strategy that allows a knowledge transfer from a teacher network to a student one, the latter fed with fewer observations (just two ones). We show that a properly defined teacher supervision allows a student network to perform comparably to state-of-the-art approaches that demand more observations. Besides, extensive experiments on common trajectory forecasting datasets highlight that our student network better generalizes to unseen scenarios.
Online Learning of Reusable Abstract Models for Object Goal Navigation
Mar 04, 2022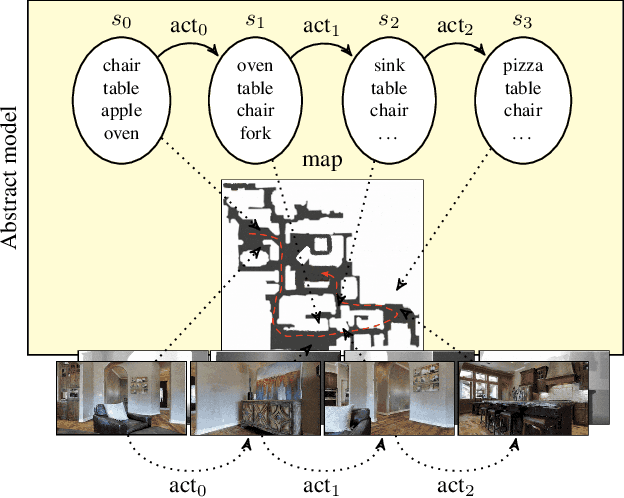
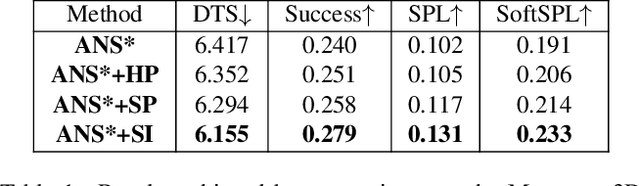
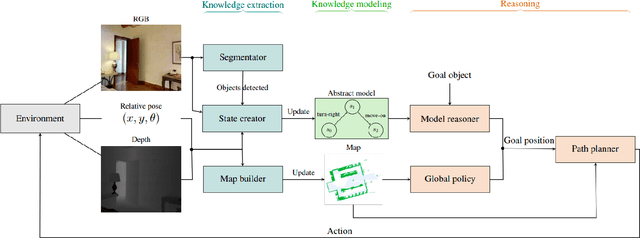
In this paper, we present a novel approach to incrementally learn an Abstract Model of an unknown environment, and show how an agent can reuse the learned model for tackling the Object Goal Navigation task. The Abstract Model is a finite state machine in which each state is an abstraction of a state of the environment, as perceived by the agent in a certain position and orientation. The perceptions are high-dimensional sensory data (e.g., RGB-D images), and the abstraction is reached by exploiting image segmentation and the Taskonomy model bank. The learning of the Abstract Model is accomplished by executing actions, observing the reached state, and updating the Abstract Model with the acquired information. The learned models are memorized by the agent, and they are reused whenever it recognizes to be in an environment that corresponds to the stored model. We investigate the effectiveness of the proposed approach for the Object Goal Navigation task, relying on public benchmarks. Our results show that the reuse of learned Abstract Models can boost performance on Object Goal Navigation.
SlowFast Rolling-Unrolling LSTMs for Action Anticipation in Egocentric Videos
Sep 02, 2021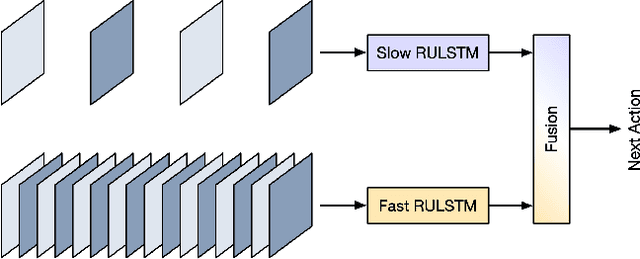
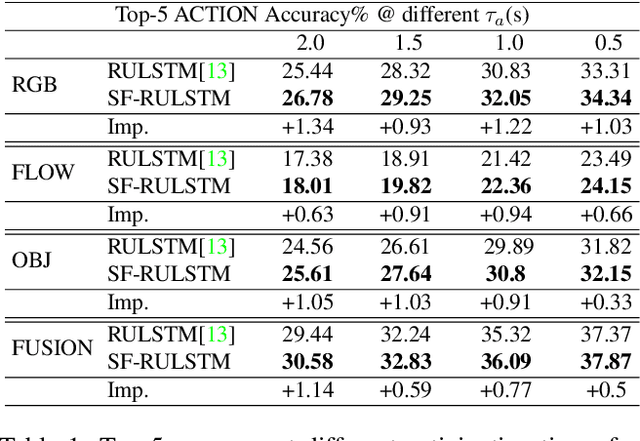
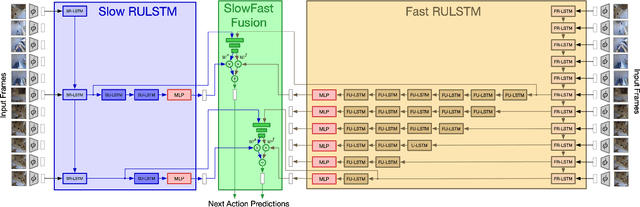
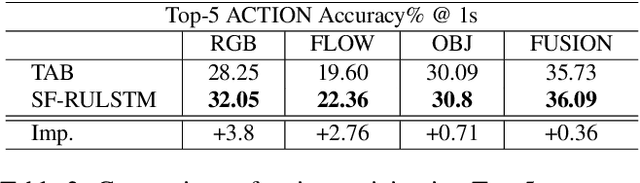
Action anticipation in egocentric videos is a difficult task due to the inherently multi-modal nature of human actions. Additionally, some actions happen faster or slower than others depending on the actor or surrounding context which could vary each time and lead to different predictions. Based on this idea, we build upon RULSTM architecture, which is specifically designed for anticipating human actions, and propose a novel attention-based technique to evaluate, simultaneously, slow and fast features extracted from three different modalities, namely RGB, optical flow, and extracted objects. Two branches process information at different time scales, i.e., frame-rates, and several fusion schemes are considered to improve prediction accuracy. We perform extensive experiments on EpicKitchens-55 and EGTEA Gaze+ datasets, and demonstrate that our technique systematically improves the results of RULSTM architecture for Top-5 accuracy metric at different anticipation times.