 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndro Spinelli
MoDiPO: text-to-motion alignment via AI-feedback-driven Direct Preference Optimization
May 06, 2024
Diffusion Models have revolutionized the field of human motion generation by offering exceptional generation quality and fine-grained controllability through natural language conditioning. Their inherent stochasticity, that is the ability to generate various outputs from a single input, is key to their success. However, this diversity should not be unrestricted, as it may lead to unlikely generations. Instead, it should be confined within the boundaries of text-aligned and realistic generations. To address this issue, we propose MoDiPO (Motion Diffusion DPO), a novel methodology that leverages Direct Preference Optimization (DPO) to align text-to-motion models. We streamline the laborious and expensive process of gathering human preferences needed in DPO by leveraging AI feedback instead. This enables us to experiment with novel DPO strategies, using both online and offline generated motion-preference pairs. To foster future research we contribute with a motion-preference dataset which we dub Pick-a-Move. We demonstrate, both qualitatively and quantitatively, that our proposed method yields significantly more realistic motions. In particular, MoDiPO substantially improves Frechet Inception Distance (FID) while retaining the same RPrecision and Multi-Modality performances.
Following the Human Thread in Social Navigation
Apr 17, 2024The success of collaboration between humans and robots in shared environments relies on the robot's real-time adaptation to human motion. Specifically, in Social Navigation, the agent should be close enough to assist but ready to back up to let the human move freely, avoiding collisions. Human trajectories emerge as crucial cues in Social Navigation, but they are partially observable from the robot's egocentric view and computationally complex to process. We propose the first Social Dynamics Adaptation model (SDA) based on the robot's state-action history to infer the social dynamics. We propose a two-stage Reinforcement Learning framework: the first learns to encode the human trajectories into social dynamics and learns a motion policy conditioned on this encoded information, the current status, and the previous action. Here, the trajectories are fully visible, i.e., assumed as privileged information. In the second stage, the trained policy operates without direct access to trajectories. Instead, the model infers the social dynamics solely from the history of previous actions and statuses in real-time. Tested on the novel Habitat 3.0 platform, SDA sets a novel state of the art (SoA) performance in finding and following humans.
TopoX: A Suite of Python Packages for Machine Learning on Topological Domains
Feb 07, 2024We introduce topox, a Python software suite that provides reliable and user-friendly building blocks for computing and machine learning on topological domains that extend graphs: hypergraphs, simplicial, cellular, path and combinatorial complexes. topox consists of three packages: toponetx facilitates constructing and computing on these domains, including working with nodes, edges and higher-order cells; topoembedx provides methods to embed topological domains into vector spaces, akin to popular graph-based embedding algorithms such as node2vec; topomodelx is built on top of PyTorch and offers a comprehensive toolbox of higher-order message passing functions for neural networks on topological domains. The extensively documented and unit-tested source code of topox is available under MIT license at https://github.com/pyt-team.
Adaptive Point Transformer
Jan 26, 2024The recent surge in 3D data acquisition has spurred the development of geometric deep learning models for point cloud processing, boosted by the remarkable success of transformers in natural language processing. While point cloud transformers (PTs) have achieved impressive results recently, their quadratic scaling with respect to the point cloud size poses a significant scalability challenge for real-world applications. To address this issue, we propose the Adaptive Point Cloud Transformer (AdaPT), a standard PT model augmented by an adaptive token selection mechanism. AdaPT dynamically reduces the number of tokens during inference, enabling efficient processing of large point clouds. Furthermore, we introduce a budget mechanism to flexibly adjust the computational cost of the model at inference time without the need for retraining or fine-tuning separate models. Our extensive experimental evaluation on point cloud classification tasks demonstrates that AdaPT significantly reduces computational complexity while maintaining competitive accuracy compared to standard PTs. The code for AdaPT is made publicly available.
GATSY: Graph Attention Network for Music Artist Similarity
Nov 01, 2023The artist similarity quest has become a crucial subject in social and scientific contexts. Modern research solutions facilitate music discovery according to user tastes. However, defining similarity among artists may involve several aspects, even related to a subjective perspective, and it often affects a recommendation. This paper presents GATSY, a recommendation system built upon graph attention networks and driven by a clusterized embedding of artists. The proposed framework takes advantage of a graph topology of the input data to achieve outstanding performance results without relying heavily on hand-crafted features. This flexibility allows us to introduce fictitious artists in a music dataset, create bridges to previously unrelated artists, and get recommendations conditioned by possibly heterogeneous sources. Experimental results prove the effectiveness of the proposed method with respect to state-of-the-art solutions.
ICML 2023 Topological Deep Learning Challenge : Design and Results
Oct 02, 2023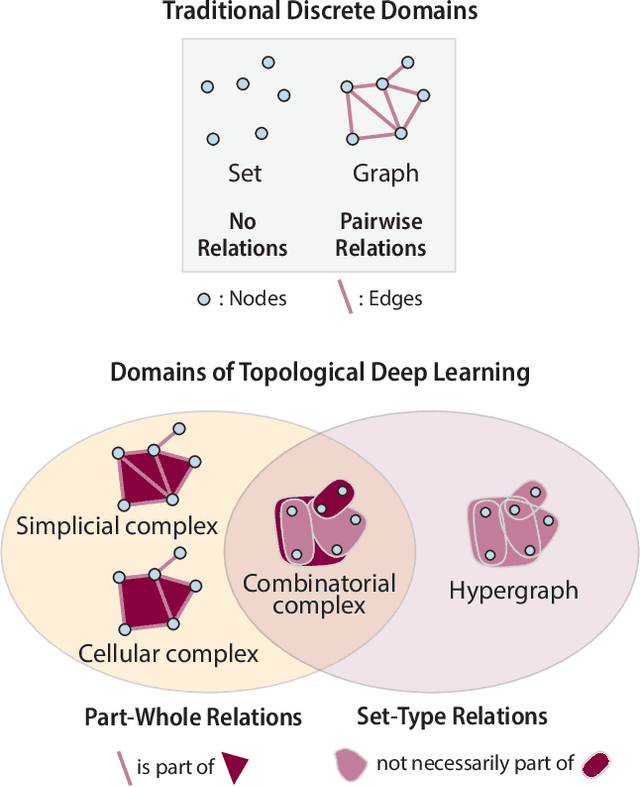
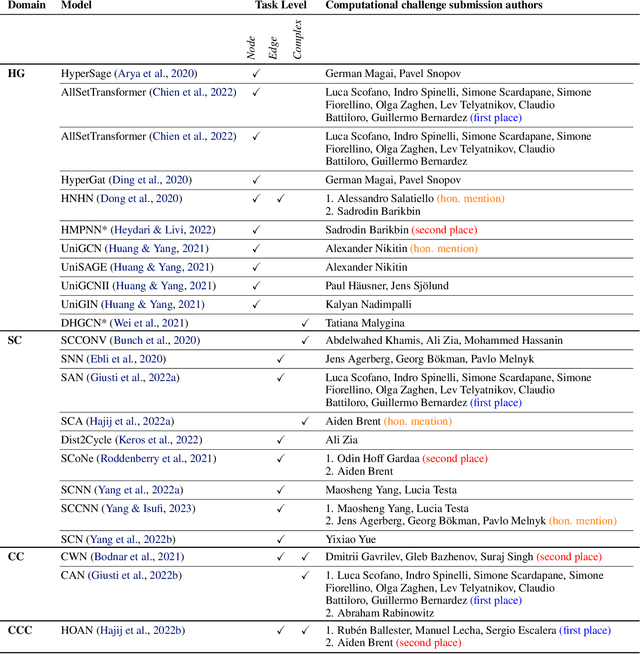
This paper presents the computational challenge on topological deep learning that was hosted within the ICML 2023 Workshop on Topology and Geometry in Machine Learning. The competition asked participants to provide open-source implementations of topological neural networks from the literature by contributing to the python packages TopoNetX (data processing) and TopoModelX (deep learning). The challenge attracted twenty-eight qualifying submissions in its two-month duration. This paper describes the design of the challenge and summarizes its main findings.
From Latent Graph to Latent Topology Inference: Differentiable Cell Complex Module
May 25, 2023
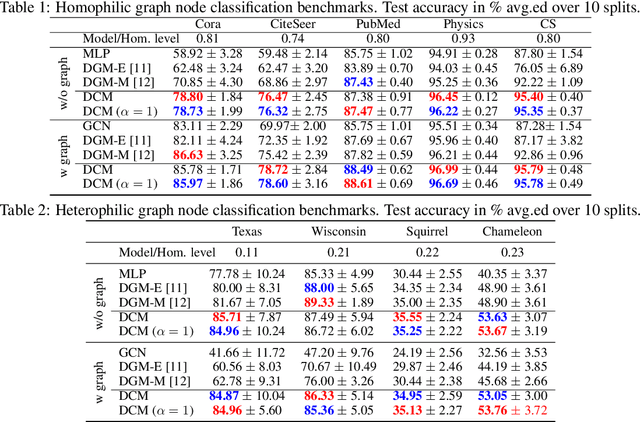
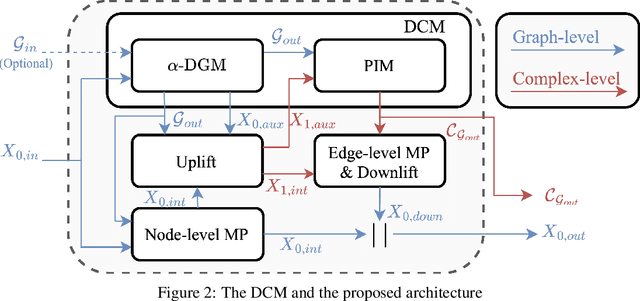

Latent Graph Inference (LGI) relaxed the reliance of Graph Neural Networks (GNNs) on a given graph topology by dynamically learning it. However, most of LGI methods assume to have a (noisy, incomplete, improvable, ...) input graph to rewire and can solely learn regular graph topologies. In the wake of the success of Topological Deep Learning (TDL), we study Latent Topology Inference (LTI) for learning higher-order cell complexes (with sparse and not regular topology) describing multi-way interactions between data points. To this aim, we introduce the Differentiable Cell Complex Module (DCM), a novel learnable function that computes cell probabilities in the complex to improve the downstream task. We show how to integrate DCM with cell complex message passing networks layers and train it in a end-to-end fashion, thanks to a two-step inference procedure that avoids an exhaustive search across all possible cells in the input, thus maintaining scalability. Our model is tested on several homophilic and heterophilic graph datasets and it is shown to outperform other state-of-the-art techniques, offering significant improvements especially in cases where an input graph is not provided.
Combining Stochastic Explainers and Subgraph Neural Networks can Increase Expressivity and Interpretability
Apr 14, 2023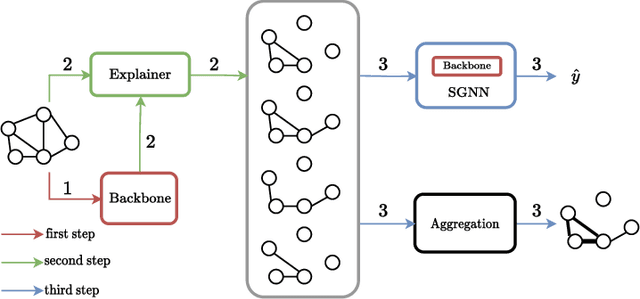


Subgraph-enhanced graph neural networks (SGNN) can increase the expressive power of the standard message-passing framework. This model family represents each graph as a collection of subgraphs, generally extracted by random sampling or with hand-crafted heuristics. Our key observation is that by selecting "meaningful" subgraphs, besides improving the expressivity of a GNN, it is also possible to obtain interpretable results. For this purpose, we introduce a novel framework that jointly predicts the class of the graph and a set of explanatory sparse subgraphs, which can be analyzed to understand the decision process of the classifier. We compare the performance of our framework against standard subgraph extraction policies, like random node/edge deletion strategies. The subgraphs produced by our framework allow to achieve comparable performance in terms of accuracy, with the additional benefit of providing explanations.
Drop Edges and Adapt: a Fairness Enforcing Fine-tuning for Graph Neural Networks
Feb 22, 2023

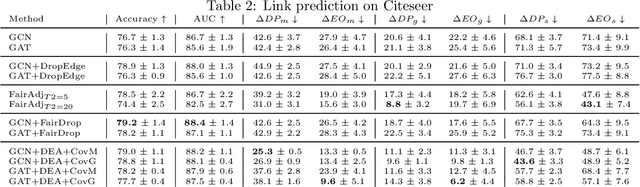

The rise of graph representation learning as the primary solution for many different network science tasks led to a surge of interest in the fairness of this family of methods. Link prediction, in particular, has a substantial social impact. However, link prediction algorithms tend to increase the segregation in social networks by disfavoring the links between individuals in specific demographic groups. This paper proposes a novel way to enforce fairness on graph neural networks with a fine-tuning strategy. We Drop the unfair Edges and, simultaneously, we Adapt the model's parameters to those modifications, DEA in short. We introduce two covariance-based constraints designed explicitly for the link prediction task. We use these constraints to guide the optimization process responsible for learning the new "fair" adjacency matrix. One novelty of DEA is that we can use a discrete yet learnable adjacency matrix in our fine-tuning. We demonstrate the effectiveness of our approach on five real-world datasets and show that we can improve both the accuracy and the fairness of the link prediction tasks. In addition, we present an in-depth ablation study demonstrating that our training algorithm for the adjacency matrix can be used to improve link prediction performances during training. Finally, we compute the relevance of each component of our framework to show that the combination of both the constraints and the training of the adjacency matrix leads to optimal performances.
Explainability in subgraphs-enhanced Graph Neural Networks
Sep 16, 2022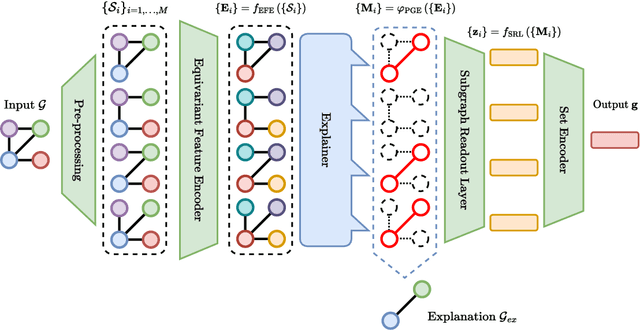



Recently, subgraphs-enhanced Graph Neural Networks (SGNNs) have been introduced to enhance the expressive power of Graph Neural Networks (GNNs), which was proved to be not higher than the 1-dimensional Weisfeiler-Leman isomorphism test. The new paradigm suggests using subgraphs extracted from the input graph to improve the model's expressiveness, but the additional complexity exacerbates an already challenging problem in GNNs: explaining their predictions. In this work, we adapt PGExplainer, one of the most recent explainers for GNNs, to SGNNs. The proposed explainer accounts for the contribution of all the different subgraphs and can produce a meaningful explanation that humans can interpret. The experiments that we performed both on real and synthetic datasets show that our framework is successful in explaining the decision process of an SGNN on graph classification tasks.