 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimone Scardapane
Alice's Adventures in a Differentiable Wonderland -- Volume I, A Tour of the Land
Apr 26, 2024
This book is a self-contained introduction to the design of modern (deep) neural networks. Because the term "neural" comes with a lot of historical baggage, I prefer the simpler term "differentiable models" in the text. The focus of this 250-pages volume is on building efficient blocks for processing $n$D data, including convolutions, transformers, graph layers, and modern recurrent models (including linearized transformers and structured state-space models). Because the field is evolving quickly, I have tried to strike a good balance between theory and code, historical considerations and recent trends. I assume the reader has some exposure to machine learning and linear algebra, but I try to cover the preliminaries when necessary. The volume is a refined draft from a set of lecture notes for a course called Neural Networks for Data Science Applications that I teach in Sapienza. I do not cover many advanced topics (generative modeling, explainability, prompting, agents), which will be published over time in the companion website.
Adaptive Semantic Token Selection for AI-native Goal-oriented Communications
Apr 25, 2024In this paper, we propose a novel design for AI-native goal-oriented communications, exploiting transformer neural networks under dynamic inference constraints on bandwidth and computation. Transformers have become the standard architecture for pretraining large-scale vision and text models, and preliminary results have shown promising performance also in deep joint source-channel coding (JSCC). Here, we consider a dynamic model where communication happens over a channel with variable latency and bandwidth constraints. Leveraging recent works on conditional computation, we exploit the structure of the transformer blocks and the multihead attention operator to design a trainable semantic token selection mechanism that learns to select relevant tokens (e.g., image patches) from the input signal. This is done dynamically, on a per-input basis, with a rate that can be chosen as an additional input by the user. We show that our model improves over state-of-the-art token selection mechanisms, exhibiting high accuracy for a wide range of latency and bandwidth constraints, without the need for deploying multiple architectures tailored to each constraint. Last, but not least, the proposed token selection mechanism helps extract powerful semantics that are easy to understand and explain, paving the way for interpretable-by-design models for the next generation of AI-native communication systems.
Conditional computation in neural networks: principles and research trends
Mar 12, 2024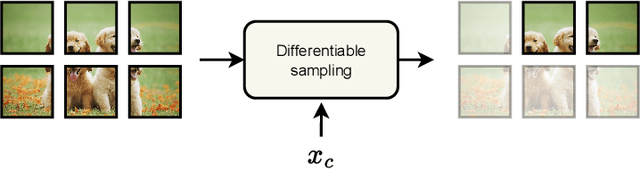
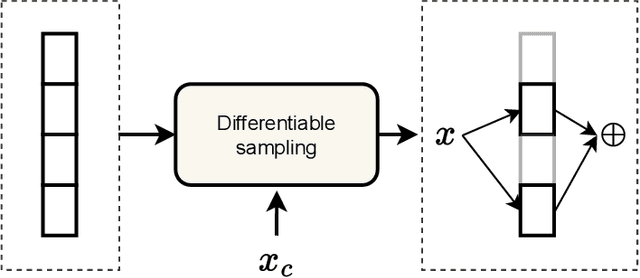
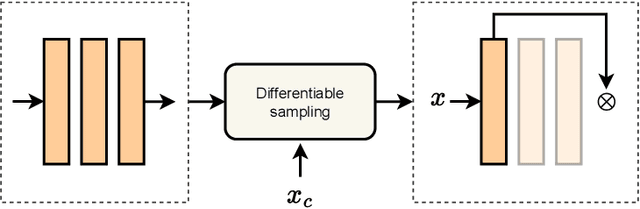
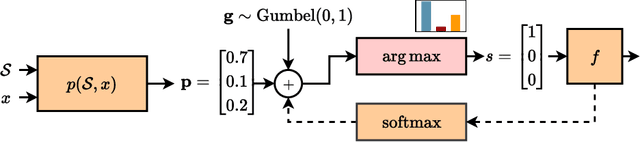
This article summarizes principles and ideas from the emerging area of applying \textit{conditional computation} methods to the design of neural networks. In particular, we focus on neural networks that can dynamically activate or de-activate parts of their computational graph conditionally on their input. Examples include the dynamic selection of, e.g., input tokens, layers (or sets of layers), and sub-modules inside each layer (e.g., channels in a convolutional filter). We first provide a general formalism to describe these techniques in an uniform way. Then, we introduce three notable implementations of these principles: mixture-of-experts (MoEs) networks, token selection mechanisms, and early-exit neural networks. The paper aims to provide a tutorial-like introduction to this growing field. To this end, we analyze the benefits of these modular designs in terms of efficiency, explainability, and transfer learning, with a focus on emerging applicative areas ranging from automated scientific discovery to semantic communication.
Position Paper: Challenges and Opportunities in Topological Deep Learning
Feb 14, 2024Topological deep learning (TDL) is a rapidly evolving field that uses topological features to understand and design deep learning models. This paper posits that TDL may complement graph representation learning and geometric deep learning by incorporating topological concepts, and can thus provide a natural choice for various machine learning settings. To this end, this paper discusses open problems in TDL, ranging from practical benefits to theoretical foundations. For each problem, it outlines potential solutions and future research opportunities. At the same time, this paper serves as an invitation to the scientific community to actively participate in TDL research to unlock the potential of this emerging field.
Goal-Oriented and Semantic Communication in 6G AI-Native Networks: The 6G-GOALS Approach
Feb 12, 2024Recent advances in AI technologies have notably expanded device intelligence, fostering federation and cooperation among distributed AI agents. These advancements impose new requirements on future 6G mobile network architectures. To meet these demands, it is essential to transcend classical boundaries and integrate communication, computation, control, and intelligence. This paper presents the 6G-GOALS approach to goal-oriented and semantic communications for AI-Native 6G Networks. The proposed approach incorporates semantic, pragmatic, and goal-oriented communication into AI-native technologies, aiming to facilitate information exchange between intelligent agents in a more relevant, effective, and timely manner, thereby optimizing bandwidth, latency, energy, and electromagnetic field (EMF) radiation. The focus is on distilling data to its most relevant form and terse representation, aligning with the source's intent or the destination's objectives and context, or serving a specific goal. 6G-GOALS builds on three fundamental pillars: i) AI-enhanced semantic data representation, sensing, compression, and communication, ii) foundational AI reasoning and causal semantic data representation, contextual relevance, and value for goal-oriented effectiveness, and iii) sustainability enabled by more efficient wireless services. Finally, we illustrate two proof-of-concepts implementing semantic, goal-oriented, and pragmatic communication principles in near-future use cases. Our study covers the project's vision, methodologies, and potential impact.
TopoX: A Suite of Python Packages for Machine Learning on Topological Domains
Feb 07, 2024We introduce topox, a Python software suite that provides reliable and user-friendly building blocks for computing and machine learning on topological domains that extend graphs: hypergraphs, simplicial, cellular, path and combinatorial complexes. topox consists of three packages: toponetx facilitates constructing and computing on these domains, including working with nodes, edges and higher-order cells; topoembedx provides methods to embed topological domains into vector spaces, akin to popular graph-based embedding algorithms such as node2vec; topomodelx is built on top of PyTorch and offers a comprehensive toolbox of higher-order message passing functions for neural networks on topological domains. The extensively documented and unit-tested source code of topox is available under MIT license at https://github.com/pyt-team.
Cascaded Scaling Classifier: class incremental learning with probability scaling
Feb 05, 2024Humans are capable of acquiring new knowledge and transferring learned knowledge into different domains, incurring a small forgetting. The same ability, called Continual Learning, is challenging to achieve when operating with neural networks due to the forgetting affecting past learned tasks when learning new ones. This forgetting can be mitigated by replaying stored samples from past tasks, but a large memory size may be needed for long sequences of tasks; moreover, this could lead to overfitting on saved samples. In this paper, we propose a novel regularisation approach and a novel incremental classifier called, respectively, Margin Dampening and Cascaded Scaling Classifier. The first combines a soft constraint and a knowledge distillation approach to preserve past learned knowledge while allowing the model to learn new patterns effectively. The latter is a gated incremental classifier, helping the model modify past predictions without directly interfering with them. This is achieved by modifying the output of the model with auxiliary scaling functions. We empirically show that our approach performs well on multiple benchmarks against well-established baselines, and we also study each component of our proposal and how the combinations of such components affect the final results.
Adaptive Point Transformer
Jan 26, 2024The recent surge in 3D data acquisition has spurred the development of geometric deep learning models for point cloud processing, boosted by the remarkable success of transformers in natural language processing. While point cloud transformers (PTs) have achieved impressive results recently, their quadratic scaling with respect to the point cloud size poses a significant scalability challenge for real-world applications. To address this issue, we propose the Adaptive Point Cloud Transformer (AdaPT), a standard PT model augmented by an adaptive token selection mechanism. AdaPT dynamically reduces the number of tokens during inference, enabling efficient processing of large point clouds. Furthermore, we introduce a budget mechanism to flexibly adjust the computational cost of the model at inference time without the need for retraining or fine-tuning separate models. Our extensive experimental evaluation on point cloud classification tasks demonstrates that AdaPT significantly reduces computational complexity while maintaining competitive accuracy compared to standard PTs. The code for AdaPT is made publicly available.
NACHOS: Neural Architecture Search for Hardware Constrained Early Exit Neural Networks
Jan 24, 2024Early Exit Neural Networks (EENNs) endow astandard Deep Neural Network (DNN) with Early Exit Classifiers (EECs), to provide predictions at intermediate points of the processing when enough confidence in classification is achieved. This leads to many benefits in terms of effectiveness and efficiency. Currently, the design of EENNs is carried out manually by experts, a complex and time-consuming task that requires accounting for many aspects, including the correct placement, the thresholding, and the computational overhead of the EECs. For this reason, the research is exploring the use of Neural Architecture Search (NAS) to automatize the design of EENNs. Currently, few comprehensive NAS solutions for EENNs have been proposed in the literature, and a fully automated, joint design strategy taking into consideration both the backbone and the EECs remains an open problem. To this end, this work presents Neural Architecture Search for Hardware Constrained Early Exit Neural Networks (NACHOS), the first NAS framework for the design of optimal EENNs satisfying constraints on the accuracy and the number of Multiply and Accumulate (MAC) operations performed by the EENNs at inference time. In particular, this provides the joint design of backbone and EECs to select a set of admissible (i.e., respecting the constraints) Pareto Optimal Solutions in terms of best tradeoff between the accuracy and number of MACs. The results show that the models designed by NACHOS are competitive with the state-of-the-art EENNs. Additionally, this work investigates the effectiveness of two novel regularization terms designed for the optimization of the auxiliary classifiers of the EENN
Adaptive Computation Modules: Granular Conditional Computation For Efficient Inference
Dec 15, 2023The computational cost of transformer models makes them inefficient in low-latency or low-power applications. While techniques such as quantization or linear attention can reduce the computational load, they may incur a reduction in accuracy. In addition, globally reducing the cost for all inputs may be sub-optimal. We observe that for each layer, the full width of the layer may be needed only for a small subset of tokens inside a batch and that the "effective" width needed to process a token can vary from layer to layer. Motivated by this observation, we introduce the Adaptive Computation Module (ACM), a generic module that dynamically adapts its computational load to match the estimated difficulty of the input on a per-token basis. An ACM consists of a sequence of learners that progressively refine the output of their preceding counterparts. An additional gating mechanism determines the optimal number of learners to execute for each token. We also describe a distillation technique to replace any pre-trained model with an "ACMized" variant. The distillation phase is designed to be highly parallelizable across layers while being simple to plug-and-play into existing networks. Our evaluation of transformer models in computer vision and speech recognition demonstrates that substituting layers with ACMs significantly reduces inference costs without degrading the downstream accuracy for a wide interval of user-defined budgets.