 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMichael T. Schaub
Learning From Simplicial Data Based on Random Walks and 1D Convolutions
Apr 04, 2024
Triggered by limitations of graph-based deep learning methods in terms of computational expressivity and model flexibility, recent years have seen a surge of interest in computational models that operate on higher-order topological domains such as hypergraphs and simplicial complexes. While the increased expressivity of these models can indeed lead to a better classification performance and a more faithful representation of the underlying system, the computational cost of these higher-order models can increase dramatically. To this end, we here explore a simplicial complex neural network learning architecture based on random walks and fast 1D convolutions (SCRaWl), in which we can adjust the increase in computational cost by varying the length and number of random walks considered while accounting for higher-order relationships. Importantly, due to the random walk-based design, the expressivity of the proposed architecture is provably incomparable to that of existing message-passing simplicial neural networks. We empirically evaluate SCRaWl on real-world datasets and show that it outperforms other simplicial neural networks.
Position Paper: Challenges and Opportunities in Topological Deep Learning
Feb 14, 2024Topological deep learning (TDL) is a rapidly evolving field that uses topological features to understand and design deep learning models. This paper posits that TDL may complement graph representation learning and geometric deep learning by incorporating topological concepts, and can thus provide a natural choice for various machine learning settings. To this end, this paper discusses open problems in TDL, ranging from practical benefits to theoretical foundations. For each problem, it outlines potential solutions and future research opportunities. At the same time, this paper serves as an invitation to the scientific community to actively participate in TDL research to unlock the potential of this emerging field.
TopoX: A Suite of Python Packages for Machine Learning on Topological Domains
Feb 07, 2024We introduce topox, a Python software suite that provides reliable and user-friendly building blocks for computing and machine learning on topological domains that extend graphs: hypergraphs, simplicial, cellular, path and combinatorial complexes. topox consists of three packages: toponetx facilitates constructing and computing on these domains, including working with nodes, edges and higher-order cells; topoembedx provides methods to embed topological domains into vector spaces, akin to popular graph-based embedding algorithms such as node2vec; topomodelx is built on top of PyTorch and offers a comprehensive toolbox of higher-order message passing functions for neural networks on topological domains. The extensively documented and unit-tested source code of topox is available under MIT license at https://github.com/pyt-team.
Combinatorial Complexes: Bridging the Gap Between Cell Complexes and Hypergraphs
Dec 15, 2023Graph-based signal processing techniques have become essential for handling data in non-Euclidean spaces. However, there is a growing awareness that these graph models might need to be expanded into `higher-order' domains to effectively represent the complex relations found in high-dimensional data. Such higher-order domains are typically modeled either as hypergraphs, or as simplicial, cubical or other cell complexes. In this context, cell complexes are often seen as a subclass of hypergraphs with additional algebraic structure that can be exploited, e.g., to develop a spectral theory. In this article, we promote an alternative perspective. We argue that hypergraphs and cell complexes emphasize \emph{different} types of relations, which may have different utility depending on the application context. Whereas hypergraphs are effective in modeling set-type, multi-body relations between entities, cell complexes provide an effective means to model hierarchical, interior-to-boundary type relations. We discuss the relative advantages of these two choices and elaborate on the previously introduced concept of a combinatorial complex that enables co-existing set-type and hierarchical relations. Finally, we provide a brief numerical experiment to demonstrate that this modelling flexibility can be advantageous in learning tasks.
Disentangling the Spectral Properties of the Hodge Laplacian: Not All Small Eigenvalues Are Equal
Nov 24, 2023The rich spectral information of the graph Laplacian has been instrumental in graph theory, machine learning, and graph signal processing for applications such as graph classification, clustering, or eigenmode analysis. Recently, the Hodge Laplacian has come into focus as a generalisation of the ordinary Laplacian for higher-order graph models such as simplicial and cellular complexes. Akin to the traditional analysis of graph Laplacians, many authors analyse the smallest eigenvalues of the Hodge Laplacian, which are connected to important topological properties such as homology. However, small eigenvalues of the Hodge Laplacian can carry different information depending on whether they are related to curl or gradient eigenmodes, and thus may not be comparable. We therefore introduce the notion of persistent eigenvector similarity and provide a method to track individual harmonic, curl, and gradient eigenvectors/-values through the so-called persistence filtration, leveraging the full information contained in the Hodge-Laplacian spectrum across all possible scales of a point cloud. Finally, we use our insights (a) to introduce a novel form of topological spectral clustering and (b) to classify edges and higher-order simplices based on their relationship to the smallest harmonic, curl, and gradient eigenvectors.
Non-isotropic Persistent Homology: Leveraging the Metric Dependency of PH
Oct 25, 2023Persistent Homology is a widely used topological data analysis tool that creates a concise description of the topological properties of a point cloud based on a specified filtration. Most filtrations used for persistent homology depend (implicitly) on a chosen metric, which is typically agnostically chosen as the standard Euclidean metric on $\mathbb{R}^n$. Recent work has tried to uncover the 'true' metric on the point cloud using distance-to-measure functions, in order to obtain more meaningful persistent homology results. Here we propose an alternative look at this problem: we posit that information on the point cloud is lost when restricting persistent homology to a single (correct) distance function. Instead, we show how by varying the distance function on the underlying space and analysing the corresponding shifts in the persistence diagrams, we can extract additional topological and geometrical information. Finally, we numerically show that non-isotropic persistent homology can extract information on orientation, orientational variance, and scaling of randomly generated point clouds with good accuracy and conduct some experiments on real-world data.
ICML 2023 Topological Deep Learning Challenge : Design and Results
Oct 02, 2023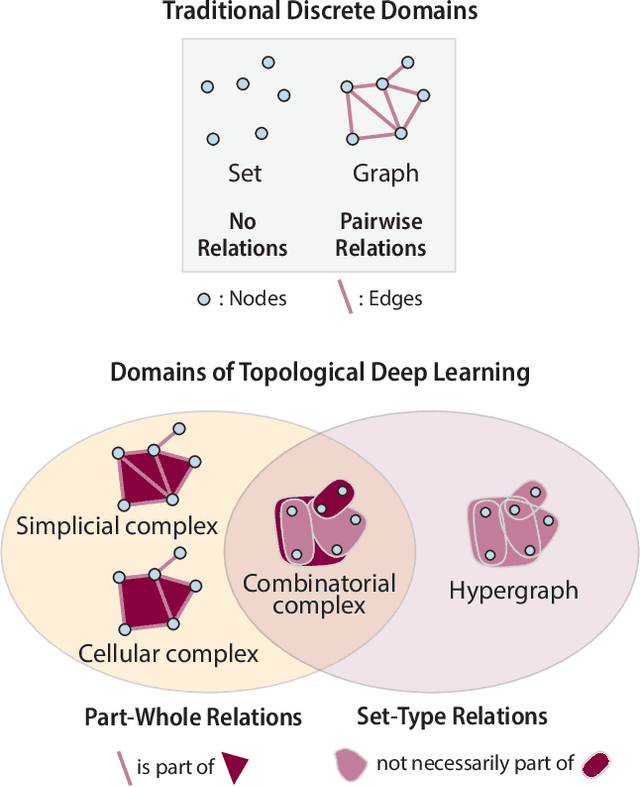
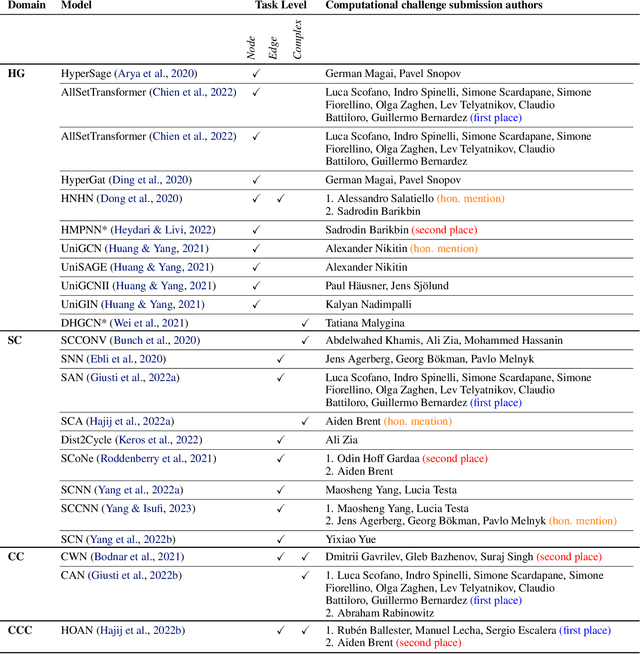
This paper presents the computational challenge on topological deep learning that was hosted within the ICML 2023 Workshop on Topology and Geometry in Machine Learning. The competition asked participants to provide open-source implementations of topological neural networks from the literature by contributing to the python packages TopoNetX (data processing) and TopoModelX (deep learning). The challenge attracted twenty-eight qualifying submissions in its two-month duration. This paper describes the design of the challenge and summarizes its main findings.
Representing Edge Flows on Graphs via Sparse Cell Complexes
Sep 15, 2023Obtaining sparse, interpretable representations of observable data is crucial in many machine learning and signal processing tasks. For data representing flows along the edges of a graph, an intuitively interpretable way to obtain such representations is to lift the graph structure to a simplicial complex: The eigenvectors of the associated Hodge-Laplacian, respectively the incidence matrices of the corresponding simplicial complex then induce a Hodge decomposition, which can be used to represent the observed data in terms of gradient, curl, and harmonic flows. In this paper, we generalize this approach to cellular complexes and introduce the cell inference optimization problem, i.e., the problem of augmenting the observed graph by a set of cells, such that the eigenvectors of the associated Hodge Laplacian provide a sparse, interpretable representation of the observed edge flows on the graph. We show that this problem is NP-hard and introduce an efficient approximation algorithm for its solution. Experiments on real-world and synthetic data demonstrate that our algorithm outperforms current state-of-the-art methods while being computationally efficient.
Optimal transport distances for directed, weighted graphs: a case study with cell-cell communication networks
Sep 14, 2023Comparing graphs by means of optimal transport has recently gained significant attention, as the distances induced by optimal transport provide both a principled metric between graphs as well as an interpretable description of the associated changes between graphs in terms of a transport plan. As the lack of symmetry introduces challenges in the typically considered formulations, optimal transport distances for graphs have mostly been developed for undirected graphs. Here, we propose two distance measures to compare directed graphs based on variants of optimal transport: (i) an earth movers distance (Wasserstein) and (ii) a Gromov-Wasserstein (GW) distance. We evaluate these two distances and discuss their relative performance for both simulated graph data and real-world directed cell-cell communication graphs, inferred from single-cell RNA-seq data.
Learning the effective order of a hypergraph dynamical system
Jun 02, 2023
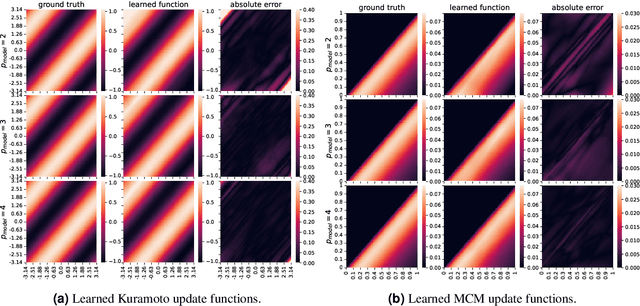
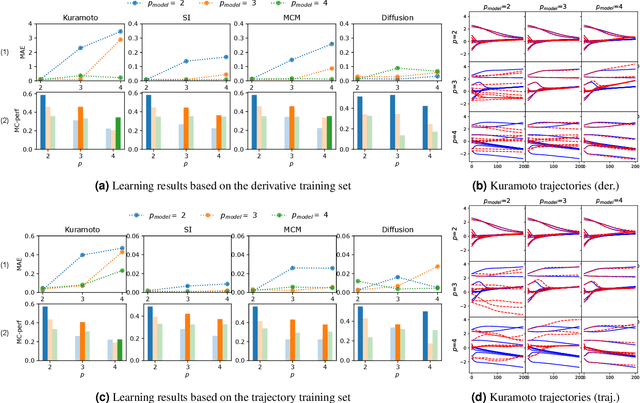
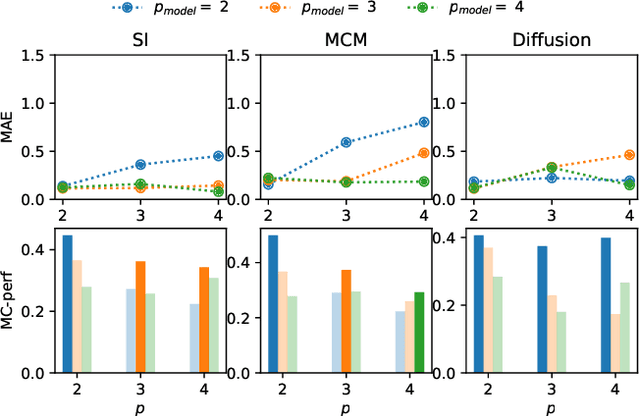
Dynamical systems on hypergraphs can display a rich set of behaviours not observable for systems with pairwise interactions. Given a distributed dynamical system with a putative hypergraph structure, an interesting question is thus how much of this hypergraph structure is actually necessary to faithfully replicate the observed dynamical behaviour. To answer this question, we propose a method to determine the minimum order of a hypergraph necessary to approximate the corresponding dynamics accurately. Specifically, we develop an analytical framework that allows us to determine this order when the type of dynamics is known. We utilize these ideas in conjunction with a hypergraph neural network to directly learn the dynamics itself and the resulting order of the hypergraph from both synthetic and real data sets consisting of observed system trajectories.