 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubhomogeneous Deep Equilibrium Models
Mar 01, 2024



Implicit-depth neural networks have grown as powerful alternatives to traditional networks in various applications in recent years. However, these models often lack guarantees of existence and uniqueness, raising stability, performance, and reproducibility issues. In this paper, we present a new analysis of the existence and uniqueness of fixed points for implicit-depth neural networks based on the concept of subhomogeneous operators and the nonlinear Perron-Frobenius theory. Compared to previous similar analyses, our theory allows for weaker assumptions on the parameter matrices, thus yielding a more flexible framework for well-defined implicit networks. We illustrate the performance of the resulting subhomogeneous networks on feed-forward, convolutional, and graph neural network examples.
Neural Rank Collapse: Weight Decay and Small Within-Class Variability Yield Low-Rank Bias
Feb 06, 2024Recent work in deep learning has shown strong empirical and theoretical evidence of an implicit low-rank bias: weight matrices in deep networks tend to be approximately low-rank and removing relatively small singular values during training or from available trained models may significantly reduce model size while maintaining or even improving model performance. However, the majority of the theoretical investigations around low-rank bias in neural networks deal with oversimplified deep linear networks. In this work, we consider general networks with nonlinear activations and the weight decay parameter, and we show the presence of an intriguing neural rank collapse phenomenon, connecting the low-rank bias of trained networks with networks' neural collapse properties: as the weight decay parameter grows, the rank of each layer in the network decreases proportionally to the within-class variability of the hidden-space embeddings of the previous layers. Our theoretical findings are supported by a range of experimental evaluations illustrating the phenomenon.
Robust low-rank training via approximate orthonormal constraints
Jun 02, 2023



With the growth of model and data sizes, a broad effort has been made to design pruning techniques that reduce the resource demand of deep learning pipelines, while retaining model performance. In order to reduce both inference and training costs, a prominent line of work uses low-rank matrix factorizations to represent the network weights. Although able to retain accuracy, we observe that low-rank methods tend to compromise model robustness against adversarial perturbations. By modeling robustness in terms of the condition number of the neural network, we argue that this loss of robustness is due to the exploding singular values of the low-rank weight matrices. Thus, we introduce a robust low-rank training algorithm that maintains the network's weights on the low-rank matrix manifold while simultaneously enforcing approximate orthonormal constraints. The resulting model reduces both training and inference costs while ensuring well-conditioning and thus better adversarial robustness, without compromising model accuracy. This is shown by extensive numerical evidence and by our main approximation theorem that shows the computed robust low-rank network well-approximates the ideal full model, provided a highly performing low-rank sub-network exists.
Learning the effective order of a hypergraph dynamical system
Jun 02, 2023
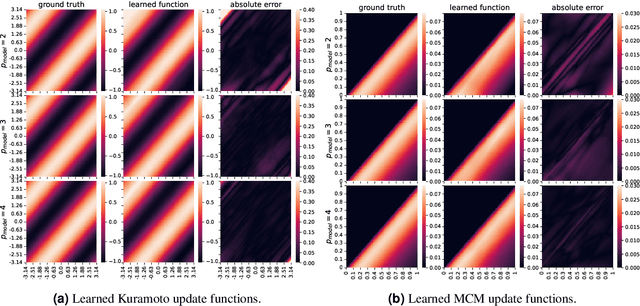
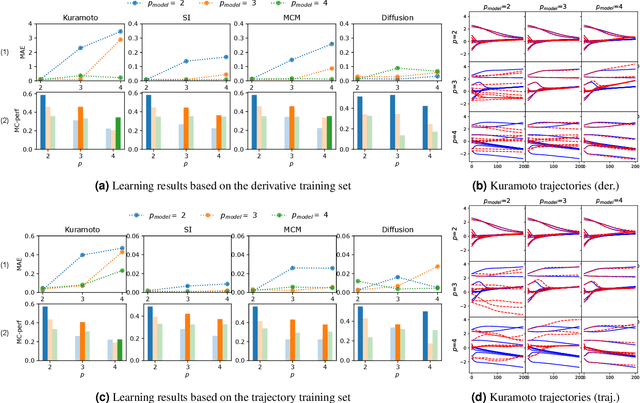
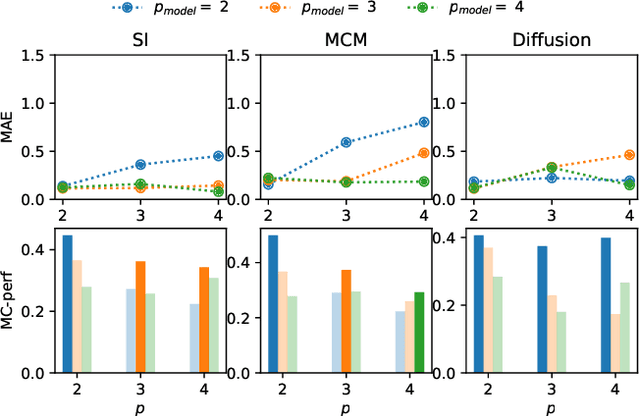
Dynamical systems on hypergraphs can display a rich set of behaviours not observable for systems with pairwise interactions. Given a distributed dynamical system with a putative hypergraph structure, an interesting question is thus how much of this hypergraph structure is actually necessary to faithfully replicate the observed dynamical behaviour. To answer this question, we propose a method to determine the minimum order of a hypergraph necessary to approximate the corresponding dynamics accurately. Specifically, we develop an analytical framework that allows us to determine this order when the type of dynamics is known. We utilize these ideas in conjunction with a hypergraph neural network to directly learn the dynamics itself and the resulting order of the hypergraph from both synthetic and real data sets consisting of observed system trajectories.
Learning the Right Layers: a Data-Driven Layer-Aggregation Strategy for Semi-Supervised Learning on Multilayer Graphs
May 31, 2023



Clustering (or community detection) on multilayer graphs poses several additional complications with respect to standard graphs as different layers may be characterized by different structures and types of information. One of the major challenges is to establish the extent to which each layer contributes to the cluster assignment in order to effectively take advantage of the multilayer structure and improve upon the classification obtained using the individual layers or their union. However, making an informed a-priori assessment about the clustering information content of the layers can be very complicated. In this work, we assume a semi-supervised learning setting, where the class of a small percentage of nodes is initially provided, and we propose a parameter-free Laplacian-regularized model that learns an optimal nonlinear combination of the different layers from the available input labels. The learning algorithm is based on a Frank-Wolfe optimization scheme with inexact gradient, combined with a modified Label Propagation iteration. We provide a detailed convergence analysis of the algorithm and extensive experiments on synthetic and real-world datasets, showing that the proposed method compares favourably with a variety of baselines and outperforms each individual layer when used in isolation.
Rank-adaptive spectral pruning of convolutional layers during training
May 30, 2023



The computing cost and memory demand of deep learning pipelines have grown fast in recent years and thus a variety of pruning techniques have been developed to reduce model parameters. The majority of these techniques focus on reducing inference costs by pruning the network after a pass of full training. A smaller number of methods address the reduction of training costs, mostly based on compressing the network via low-rank layer factorizations. Despite their efficiency for linear layers, these methods fail to effectively handle convolutional filters. In this work, we propose a low-parametric training method that factorizes the convolutions into tensor Tucker format and adaptively prunes the Tucker ranks of the convolutional kernel during training. Leveraging fundamental results from geometric integration theory of differential equations on tensor manifolds, we obtain a robust training algorithm that provably approximates the full baseline performance and guarantees loss descent. A variety of experiments against the full model and alternative low-rank baselines are implemented, showing that the proposed method drastically reduces the training costs, while achieving high performance, comparable to or better than the full baseline, and consistently outperforms competing low-rank approaches.
Laplacian-based Semi-Supervised Learning in Multilayer Hypergraphs by Coordinate Descent
Jan 28, 2023



Graph Semi-Supervised learning is an important data analysis tool, where given a graph and a set of labeled nodes, the aim is to infer the labels to the remaining unlabeled nodes. In this paper, we start by considering an optimization-based formulation of the problem for an undirected graph, and then we extend this formulation to multilayer hypergraphs. We solve the problem using different coordinate descent approaches and compare the results with the ones obtained by the classic gradient descent method. Experiments on synthetic and real-world datasets show the potential of using coordinate descent methods with suitable selection rules.
Low-rank lottery tickets: finding efficient low-rank neural networks via matrix differential equations
May 26, 2022



Neural networks have achieved tremendous success in a large variety of applications. However, their memory footprint and computational demand can render them impractical in application settings with limited hardware or energy resources. In this work, we propose a novel algorithm to find efficient low-rank subnetworks. Remarkably, these subnetworks are determined and adapted already during the training phase and the overall time and memory resources required by both training and evaluating them is significantly reduced. The main idea is to restrict the weight matrices to a low-rank manifold and to update the low-rank factors rather than the full matrix during training. To derive training updates that are restricted to the prescribed manifold, we employ techniques from dynamic model order reduction for matrix differential equations. Moreover, our method automatically and dynamically adapts the ranks during training to achieve a desired approximation accuracy. The efficiency of the proposed method is demonstrated through a variety of numerical experiments on fully-connected and convolutional networks.
A nonlinear diffusion method for semi-supervised learning on hypergraphs
Mar 27, 2021



Hypergraphs are a common model for multiway relationships in data, and hypergraph semi-supervised learning is the problem of assigning labels to all nodes in a hypergraph, given labels on just a few nodes. Diffusions and label spreading are classical techniques for semi-supervised learning in the graph setting, and there are some standard ways to extend them to hypergraphs. However, these methods are linear models, and do not offer an obvious way of incorporating node features for making predictions. Here, we develop a nonlinear diffusion process on hypergraphs that spreads both features and labels following the hypergraph structure, which can be interpreted as a hypergraph equilibrium network. Even though the process is nonlinear, we show global convergence to a unique limiting point for a broad class of nonlinearities, which is the global optimum of a interpretable, regularized semi-supervised learning loss function. The limiting point serves as a node embedding from which we make predictions with a linear model. Our approach is much more accurate than several hypergraph neural networks, and also takes less time to train.
Nonlinear Higher-Order Label Spreading
Jun 08, 2020


Label spreading is a general technique for semi-supervised learning with point cloud or network data, which can be interpreted as a diffusion of labels on a graph. While there are many variants of label spreading, nearly all of them are linear models, where the incoming information to a node is a weighted sum of information from neighboring nodes. Here, we add nonlinearity to label spreading through nonlinear functions of higher-order structure in the graph, namely triangles in the graph. For a broad class of nonlinear functions, we prove convergence of our nonlinear higher-order label spreading algorithm to the global solution of a constrained semi-supervised loss function. We demonstrate the efficiency and efficacy of our approach on a variety of point cloud and network datasets, where the nonlinear higher-order model compares favorably to classical label spreading, as well as hypergraph models and graph neural networks.