 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaul Häusner
ICML 2023 Topological Deep Learning Challenge : Design and Results
Oct 02, 2023
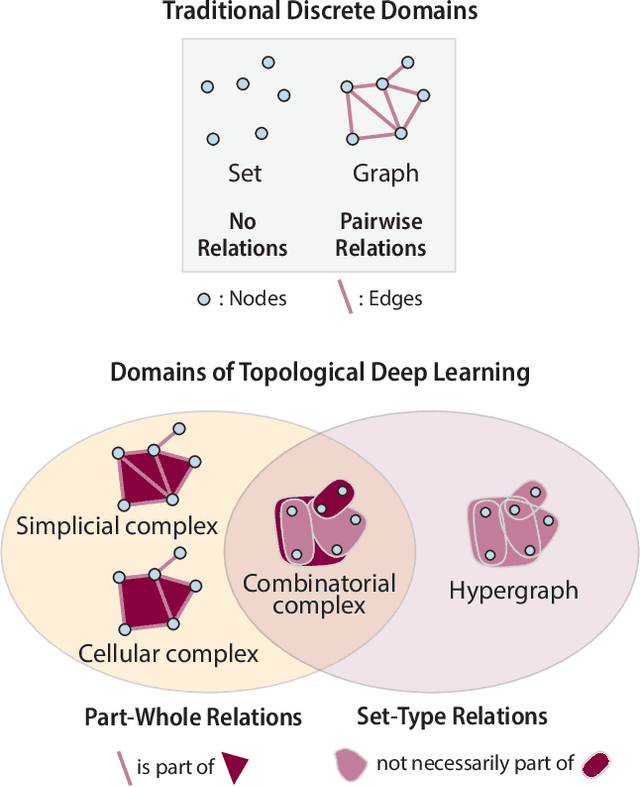
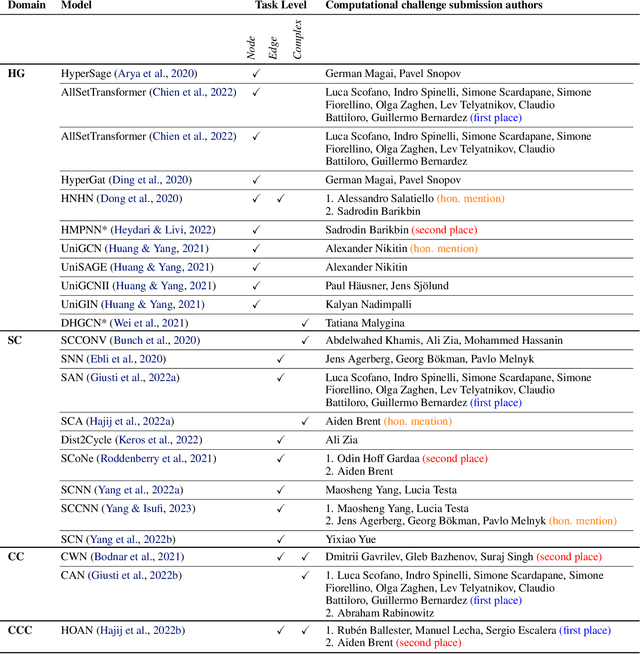
This paper presents the computational challenge on topological deep learning that was hosted within the ICML 2023 Workshop on Topology and Geometry in Machine Learning. The competition asked participants to provide open-source implementations of topological neural networks from the literature by contributing to the python packages TopoNetX (data processing) and TopoModelX (deep learning). The challenge attracted twenty-eight qualifying submissions in its two-month duration. This paper describes the design of the challenge and summarizes its main findings.
Neural incomplete factorization: learning preconditioners for the conjugate gradient method
May 25, 2023

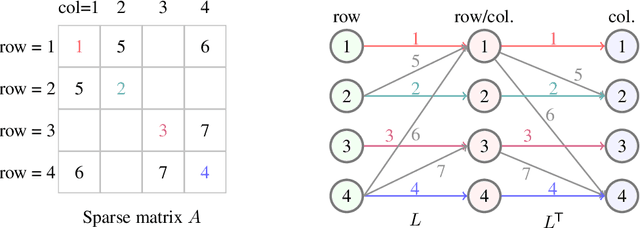

In this paper, we develop a novel data-driven approach to accelerate solving large-scale linear equation systems encountered in scientific computing and optimization. Our method utilizes self-supervised training of a graph neural network to generate an effective preconditioner tailored to the specific problem domain. By replacing conventional hand-crafted preconditioners used with the conjugate gradient method, our approach, named neural incomplete factorization (NeuralIF), significantly speeds-up convergence and computational efficiency. At the core of our method is a novel message-passing block, inspired by sparse matrix theory, that aligns with the objective to find a sparse factorization of the matrix. We evaluate our proposed method on both a synthetic and a real-world problem arising from scientific computing. Our results demonstrate that NeuralIF consistently outperforms the most common general-purpose preconditioners, including the incomplete Cholesky method, achieving competitive performance across various metrics even outside the training data distribution.