 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePetar Veličković
Categorical Deep Learning: An Algebraic Theory of Architectures
Feb 23, 2024
We present our position on the elusive quest for a general-purpose framework for specifying and studying deep learning architectures. Our opinion is that the key attempts made so far lack a coherent bridge between specifying constraints which models must satisfy and specifying their implementations. Focusing on building a such a bridge, we propose to apply category theory -- precisely, the universal algebra of monads valued in a 2-category of parametric maps -- as a single theory elegantly subsuming both of these flavours of neural network design. To defend our position, we show how this theory recovers constraints induced by geometric deep learning, as well as implementations of many architectures drawn from the diverse landscape of neural networks, such as RNNs. We also illustrate how the theory naturally encodes many standard constructs in computer science and automata theory.
Position Paper: Challenges and Opportunities in Topological Deep Learning
Feb 14, 2024Topological deep learning (TDL) is a rapidly evolving field that uses topological features to understand and design deep learning models. This paper posits that TDL may complement graph representation learning and geometric deep learning by incorporating topological concepts, and can thus provide a natural choice for various machine learning settings. To this end, this paper discusses open problems in TDL, ranging from practical benefits to theoretical foundations. For each problem, it outlines potential solutions and future research opportunities. At the same time, this paper serves as an invitation to the scientific community to actively participate in TDL research to unlock the potential of this emerging field.
Finding Increasingly Large Extremal Graphs with AlphaZero and Tabu Search
Nov 06, 2023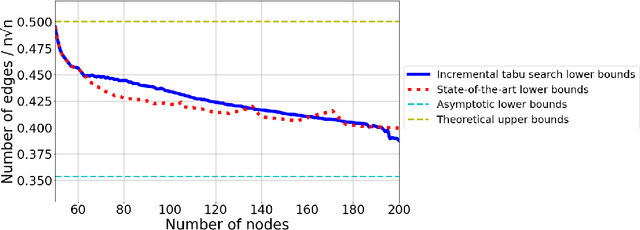
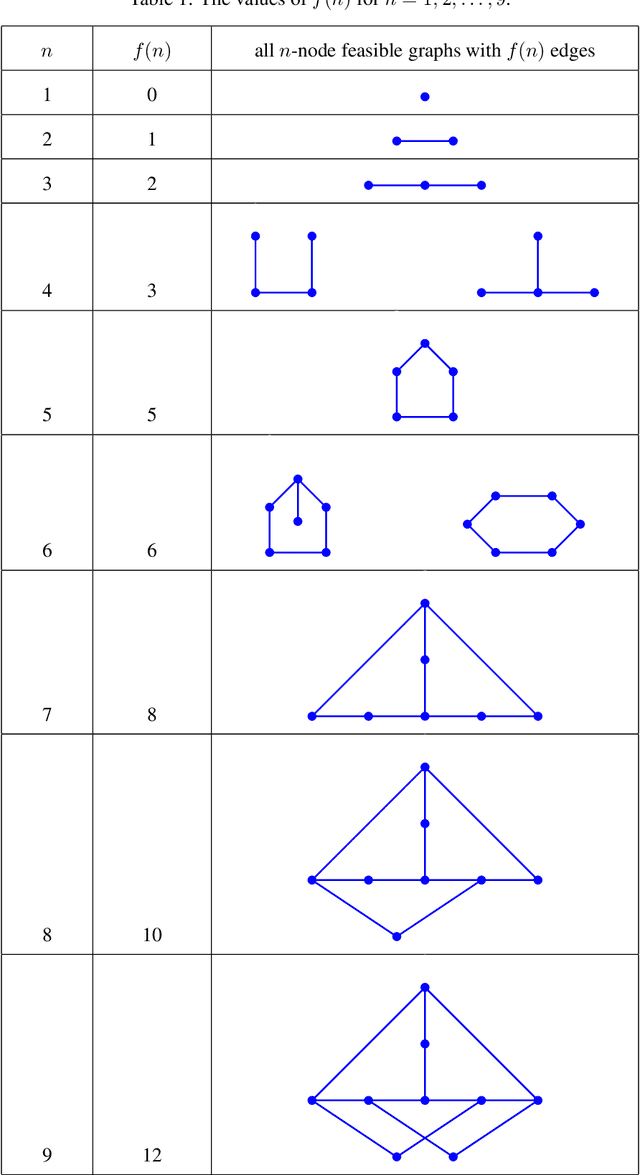
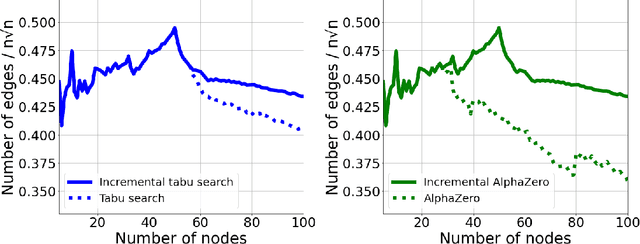

This work studies a central extremal graph theory problem inspired by a 1975 conjecture of Erd\H{o}s, which aims to find graphs with a given size (number of nodes) that maximize the number of edges without having 3- or 4-cycles. We formulate this problem as a sequential decision-making problem and compare AlphaZero, a neural network-guided tree search, with tabu search, a heuristic local search method. Using either method, by introducing a curriculum -- jump-starting the search for larger graphs using good graphs found at smaller sizes -- we improve the state-of-the-art lower bounds for several sizes. We also propose a flexible graph-generation environment and a permutation-invariant network architecture for learning to search in the space of graphs.
TacticAI: an AI assistant for football tactics
Oct 17, 2023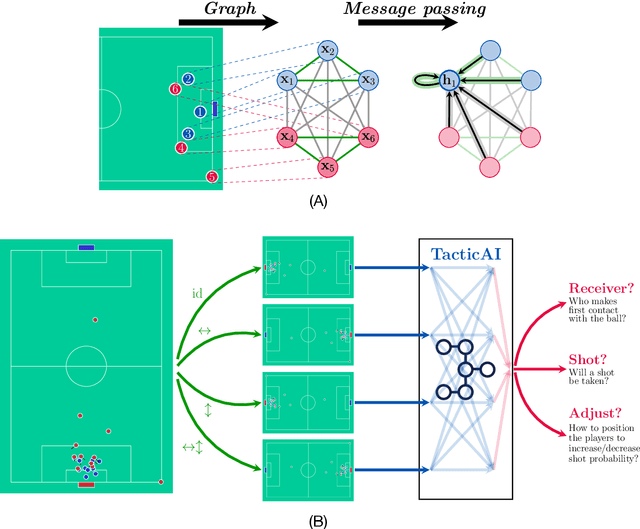
Identifying key patterns of tactics implemented by rival teams, and developing effective responses, lies at the heart of modern football. However, doing so algorithmically remains an open research challenge. To address this unmet need, we propose TacticAI, an AI football tactics assistant developed and evaluated in close collaboration with domain experts from Liverpool FC. We focus on analysing corner kicks, as they offer coaches the most direct opportunities for interventions and improvements. TacticAI incorporates both a predictive and a generative component, allowing the coaches to effectively sample and explore alternative player setups for each corner kick routine and to select those with the highest predicted likelihood of success. We validate TacticAI on a number of relevant benchmark tasks: predicting receivers and shot attempts and recommending player position adjustments. The utility of TacticAI is validated by a qualitative study conducted with football domain experts at Liverpool FC. We show that TacticAI's model suggestions are not only indistinguishable from real tactics, but also favoured over existing tactics 90% of the time, and that TacticAI offers an effective corner kick retrieval system. TacticAI achieves these results despite the limited availability of gold-standard data, achieving data efficiency through geometric deep learning.
Half-Hop: A graph upsampling approach for slowing down message passing
Aug 17, 2023

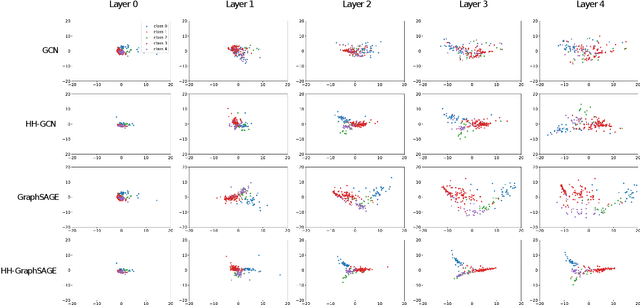
Message passing neural networks have shown a lot of success on graph-structured data. However, there are many instances where message passing can lead to over-smoothing or fail when neighboring nodes belong to different classes. In this work, we introduce a simple yet general framework for improving learning in message passing neural networks. Our approach essentially upsamples edges in the original graph by adding "slow nodes" at each edge that can mediate communication between a source and a target node. Our method only modifies the input graph, making it plug-and-play and easy to use with existing models. To understand the benefits of slowing down message passing, we provide theoretical and empirical analyses. We report results on several supervised and self-supervised benchmarks, and show improvements across the board, notably in heterophilic conditions where adjacent nodes are more likely to have different labels. Finally, we show how our approach can be used to generate augmentations for self-supervised learning, where slow nodes are randomly introduced into different edges in the graph to generate multi-scale views with variable path lengths.
Neural Priority Queues for Graph Neural Networks
Jul 18, 2023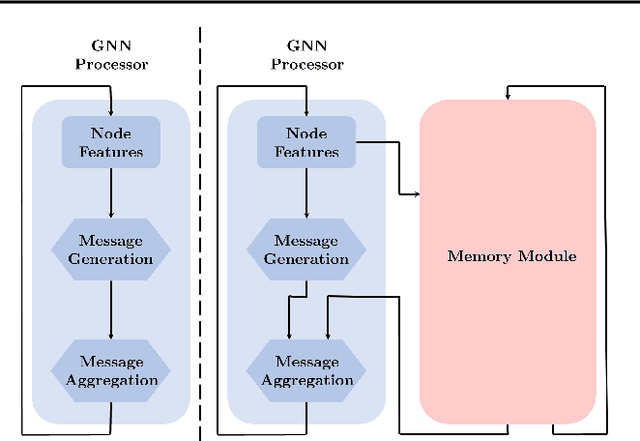
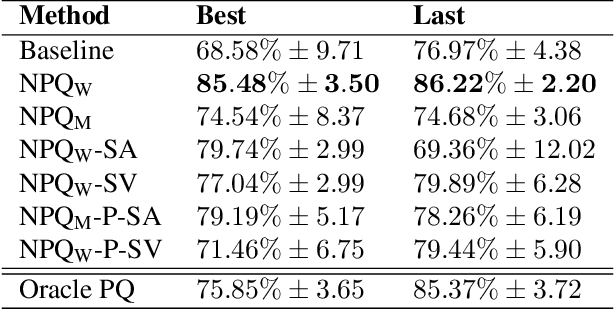
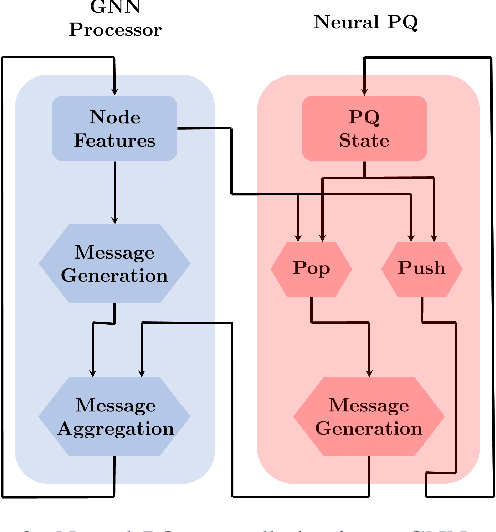

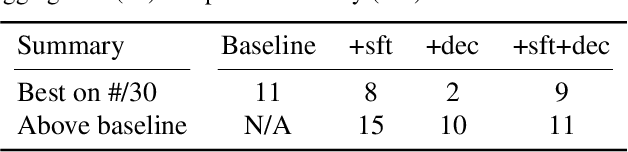
Graph Neural Networks (GNNs) have shown considerable success in neural algorithmic reasoning. Many traditional algorithms make use of an explicit memory in the form of a data structure. However, there has been limited exploration on augmenting GNNs with external memory. In this paper, we present Neural Priority Queues, a differentiable analogue to algorithmic priority queues, for GNNs. We propose and motivate a desiderata for memory modules, and show that Neural PQs exhibit the desiderata, and reason about their use with algorithmic reasoning. This is further demonstrated by empirical results on the CLRS-30 dataset. Furthermore, we find the Neural PQs useful in capturing long-range interactions, as empirically shown on a dataset from the Long-Range Graph Benchmark.
Latent Space Representations of Neural Algorithmic Reasoners
Jul 17, 2023

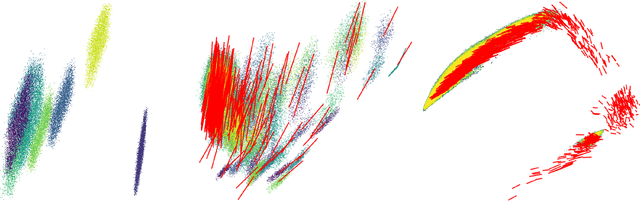
Neural Algorithmic Reasoning (NAR) is a research area focused on designing neural architectures that can reliably capture classical computation, usually by learning to execute algorithms. A typical approach is to rely on Graph Neural Network (GNN) architectures, which encode inputs in high-dimensional latent spaces that are repeatedly transformed during the execution of the algorithm. In this work we perform a detailed analysis of the structure of the latent space induced by the GNN when executing algorithms. We identify two possible failure modes: (i) loss of resolution, making it hard to distinguish similar values; (ii) inability to deal with values outside the range observed during training. We propose to solve the first issue by relying on a softmax aggregator, and propose to decay the latent space in order to deal with out-of-range values. We show that these changes lead to improvements on the majority of algorithms in the standard CLRS-30 benchmark when using the state-of-the-art Triplet-GMPNN processor. Our code is available at \href{https://github.com/mirjanic/nar-latent-spaces}{https://github.com/mirjanic/nar-latent-spaces}.
Parallel Algorithms Align with Neural Execution
Jul 08, 2023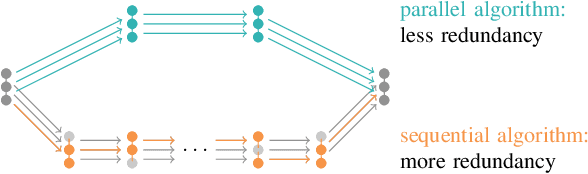


Neural algorithmic reasoners are parallel processors. Teaching them sequential algorithms contradicts this nature, rendering a significant share of their computations redundant. Parallel algorithms however may exploit their full computational power, therefore requiring fewer layers to be executed. This drastically reduces training times, as we observe when comparing parallel implementations of searching, sorting and finding strongly connected components to their sequential counterparts on the CLRS framework. Additionally, parallel versions achieve strongly superior predictive performance in most cases.
Recursive Algorithmic Reasoning
Jul 01, 2023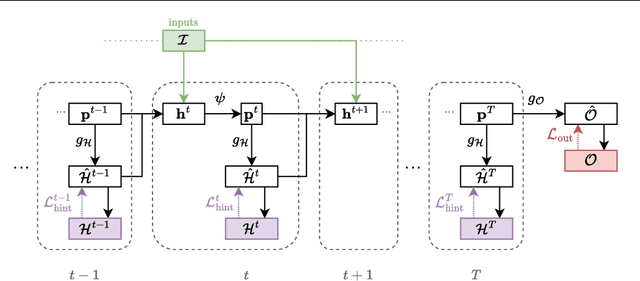

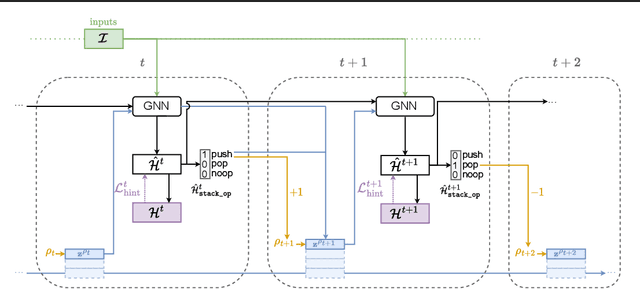
Learning models that execute algorithms can enable us to address a key problem in deep learning: generalizing to out-of-distribution data. However, neural networks are currently unable to execute recursive algorithms because they do not have arbitrarily large memory to store and recall state. To address this, we (1) propose a way to augment graph neural networks (GNNs) with a stack, and (2) develop an approach for capturing intermediate algorithm trajectories that improves algorithmic alignment with recursive algorithms over previous methods. The stack allows the network to learn to store and recall a portion of the state of the network at a particular time, analogous to the action of a call stack in a recursive algorithm. This augmentation permits the network to reason recursively. We empirically demonstrate that our proposals significantly improve generalization to larger input graphs over prior work on depth-first search (DFS).
Asynchronous Algorithmic Alignment with Cocycles
Jun 28, 2023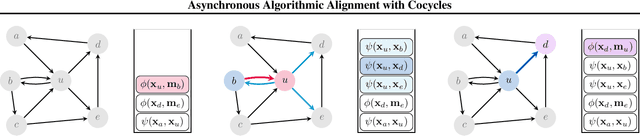
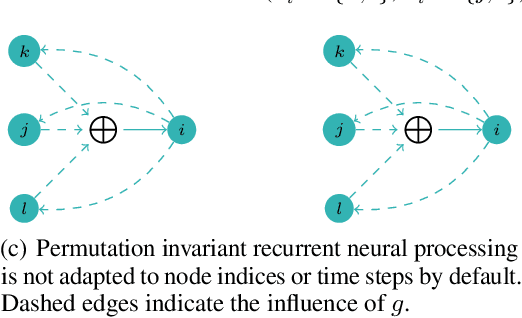
State-of-the-art neural algorithmic reasoners make use of message passing in graph neural networks (GNNs). But typical GNNs blur the distinction between the definition and invocation of the message function, forcing a node to send messages to its neighbours at every layer, synchronously. When applying GNNs to learn to execute dynamic programming algorithms, however, on most steps only a handful of the nodes would have meaningful updates to send. One, hence, runs the risk of inefficiencies by sending too much irrelevant data across the graph -- with many intermediate GNN steps having to learn identity functions. In this work, we explicitly separate the concepts of node state update and message function invocation. With this separation, we obtain a mathematical formulation that allows us to reason about asynchronous computation in both algorithms and neural networks.