 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBei Wang
In-Context Example Ordering Guided by Label Distributions
Feb 18, 2024
By allowing models to predict without task-specific training, in-context learning (ICL) with pretrained LLMs has enormous potential in NLP. However, a number of problems persist in ICL. In particular, its performance is sensitive to the choice and order of in-context examples. Given the same set of in-context examples with different orderings, model performance may vary between near random to near state-of-the-art. In this work, we formulate in-context example ordering as an optimization problem. We examine three problem settings that differ in the assumptions they make about what is known about the task. Inspired by the idea of learning from label proportions, we propose two principles for in-context example ordering guided by model's probability predictions. We apply our proposed principles to thirteen text classification datasets and nine different autoregressive LLMs with 700M to 13B parameters. We demonstrate that our approach outperforms the baselines by improving the classification accuracy, reducing model miscalibration, and also by selecting better in-context examples.
Position Paper: Challenges and Opportunities in Topological Deep Learning
Feb 14, 2024Topological deep learning (TDL) is a rapidly evolving field that uses topological features to understand and design deep learning models. This paper posits that TDL may complement graph representation learning and geometric deep learning by incorporating topological concepts, and can thus provide a natural choice for various machine learning settings. To this end, this paper discusses open problems in TDL, ranging from practical benefits to theoretical foundations. For each problem, it outlines potential solutions and future research opportunities. At the same time, this paper serves as an invitation to the scientific community to actively participate in TDL research to unlock the potential of this emerging field.
TROPHY: A Topologically Robust Physics-Informed Tracking Framework for Tropical Cyclones
Jul 28, 2023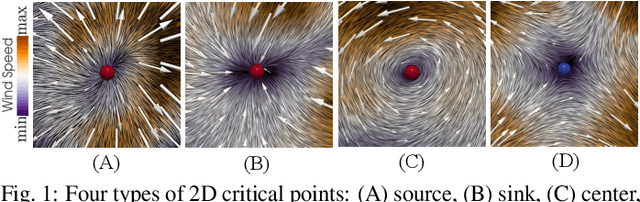
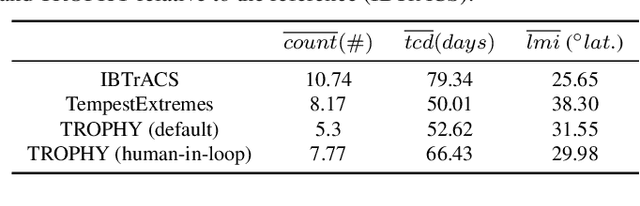
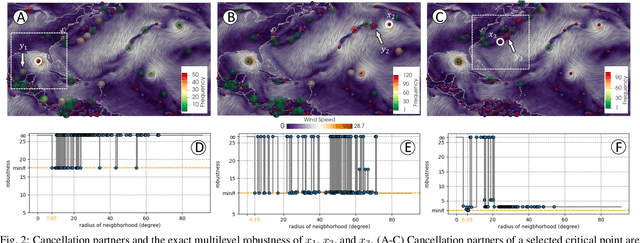
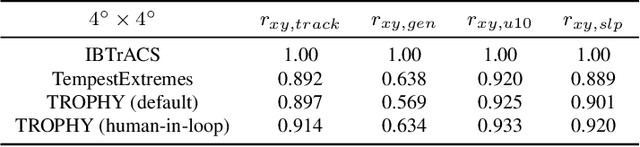
Tropical cyclones (TCs) are among the most destructive weather systems. Realistically and efficiently detecting and tracking TCs are critical for assessing their impacts and risks. Recently, a multilevel robustness framework has been introduced to study the critical points of time-varying vector fields. The framework quantifies the robustness of critical points across varying neighborhoods. By relating the multilevel robustness with critical point tracking, the framework has demonstrated its potential in cyclone tracking. An advantage is that it identifies cyclonic features using only 2D wind vector fields, which is encouraging as most tracking algorithms require multiple dynamic and thermodynamic variables at different altitudes. A disadvantage is that the framework does not scale well computationally for datasets containing a large number of cyclones. This paper introduces a topologically robust physics-informed tracking framework (TROPHY) for TC tracking. The main idea is to integrate physical knowledge of TC to drastically improve the computational efficiency of multilevel robustness framework for large-scale climate datasets. First, during preprocessing, we propose a physics-informed feature selection strategy to filter 90% of critical points that are short-lived and have low stability, thus preserving good candidates for TC tracking. Second, during in-processing, we impose constraints during the multilevel robustness computation to focus only on physics-informed neighborhoods of TCs. We apply TROPHY to 30 years of 2D wind fields from reanalysis data in ERA5 and generate a number of TC tracks. In comparison with the observed tracks, we demonstrate that TROPHY can capture TC characteristics that are comparable to and sometimes even better than a well-validated TC tracking algorithm that requires multiple dynamic and thermodynamic scalar fields.
Interpreting and generalizing deep learning in physics-based problems with functional linear models
Jul 10, 2023
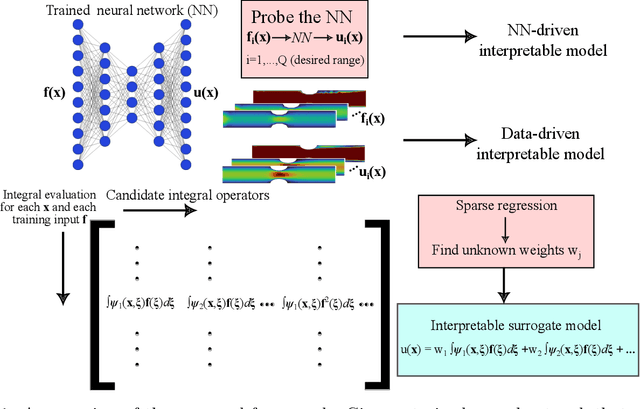
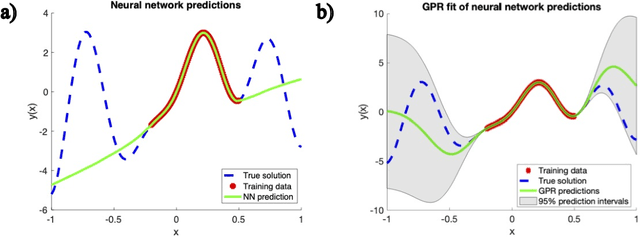

Although deep learning has achieved remarkable success in various scientific machine learning applications, its black-box nature poses concerns regarding interpretability and generalization capabilities beyond the training data. Interpretability is crucial and often desired in modeling physical systems. Moreover, acquiring extensive datasets that encompass the entire range of input features is challenging in many physics-based learning tasks, leading to increased errors when encountering out-of-distribution (OOD) data. In this work, motivated by the field of functional data analysis (FDA), we propose generalized functional linear models as an interpretable surrogate for a trained deep learning model. We demonstrate that our model could be trained either based on a trained neural network (post-hoc interpretation) or directly from training data (interpretable operator learning). A library of generalized functional linear models with different kernel functions is considered and sparse regression is used to discover an interpretable surrogate model that could be analytically presented. We present test cases in solid mechanics, fluid mechanics, and transport. Our results demonstrate that our model can achieve comparable accuracy to deep learning and can improve OOD generalization while providing more transparency and interpretability. Our study underscores the significance of interpretability in scientific machine learning and showcases the potential of functional linear models as a tool for interpreting and generalizing deep learning.
Contrastive Learning for Sleep Staging based on Inter Subject Correlation
May 05, 2023In recent years, multitudes of researches have applied deep learning to automatic sleep stage classification. Whereas actually, these works have paid less attention to the issue of cross-subject in sleep staging. At the same time, emerging neuroscience theories on inter-subject correlations can provide new insights for cross-subject analysis. This paper presents the MViTime model that have been used in sleep staging study. And we implement the inter-subject correlation theory through contrastive learning, providing a feasible solution to address the cross-subject problem in sleep stage classification. Finally, experimental results and conclusions are presented, demonstrating that the developed method has achieved state-of-the-art performance on sleep staging. The results of the ablation experiment also demonstrate the effectiveness of the cross-subject approach based on contrastive learning.
Experimental Observations of the Topology of Convolutional Neural Network Activations
Dec 01, 2022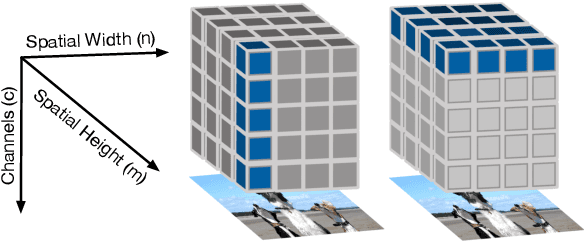
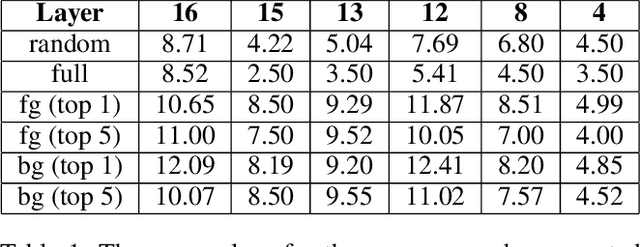
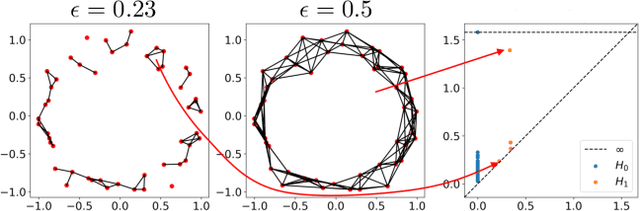
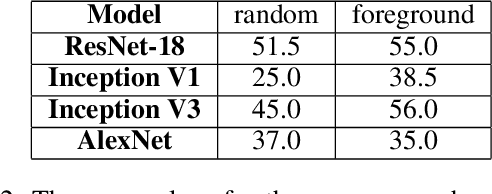
Topological data analysis (TDA) is a branch of computational mathematics, bridging algebraic topology and data science, that provides compact, noise-robust representations of complex structures. Deep neural networks (DNNs) learn millions of parameters associated with a series of transformations defined by the model architecture, resulting in high-dimensional, difficult-to-interpret internal representations of input data. As DNNs become more ubiquitous across multiple sectors of our society, there is increasing recognition that mathematical methods are needed to aid analysts, researchers, and practitioners in understanding and interpreting how these models' internal representations relate to the final classification. In this paper, we apply cutting edge techniques from TDA with the goal of gaining insight into the interpretability of convolutional neural networks used for image classification. We use two common TDA approaches to explore several methods for modeling hidden-layer activations as high-dimensional point clouds, and provide experimental evidence that these point clouds capture valuable structural information about the model's process. First, we demonstrate that a distance metric based on persistent homology can be used to quantify meaningful differences between layers, and we discuss these distances in the broader context of existing representational similarity metrics for neural network interpretability. Second, we show that a mapper graph can provide semantic insight into how these models organize hierarchical class knowledge at each layer. These observations demonstrate that TDA is a useful tool to help deep learning practitioners unlock the hidden structures of their models.
Multilevel Robustness for 2D Vector Field Feature Tracking, Selection, and Comparison
Sep 19, 2022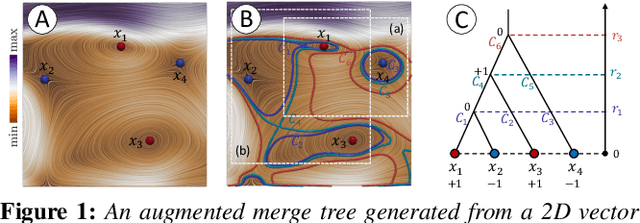
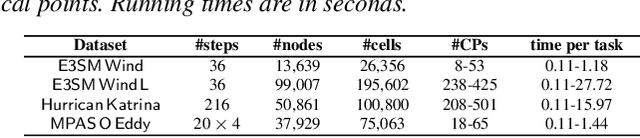

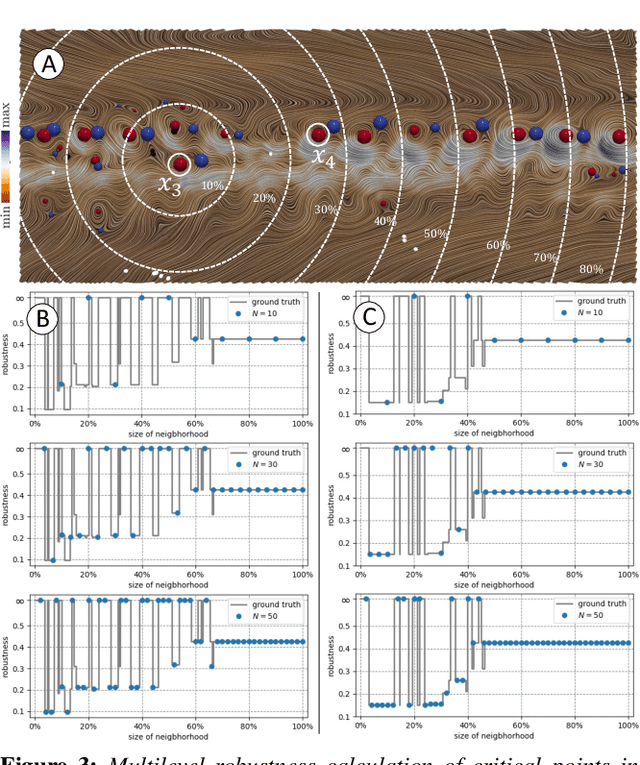
Critical point tracking is a core topic in scientific visualization for understanding the dynamic behavior of time-varying vector field data. The topological notion of robustness has been introduced recently to quantify the structural stability of critical points, that is, the robustness of a critical point is the minimum amount of perturbation to the vector field necessary to cancel it. A theoretical basis has been established previously that relates critical point tracking with the notion of robustness, in particular, critical points could be tracked based on their closeness in stability, measured by robustness, instead of just distance proximities within the domain. However, in practice, the computation of classic robustness may produce artifacts when a critical point is close to the boundary of the domain; thus, we do not have a complete picture of the vector field behavior within its local neighborhood. To alleviate these issues, we introduce a multilevel robustness framework for the study of 2D time-varying vector fields. We compute the robustness of critical points across varying neighborhoods to capture the multiscale nature of the data and to mitigate the boundary effect suffered by the classic robustness computation. We demonstrate via experiments that such a new notion of robustness can be combined seamlessly with existing feature tracking algorithms to improve the visual interpretability of vector fields in terms of feature tracking, selection, and comparison for large-scale scientific simulations. We observe, for the first time, that the minimum multilevel robustness is highly correlated with physical quantities used by domain scientists in studying a real-world tropical cyclone dataset. Such observation helps to increase the physical interpretability of robustness.
The SVD of Convolutional Weights: A CNN Interpretability Framework
Aug 14, 2022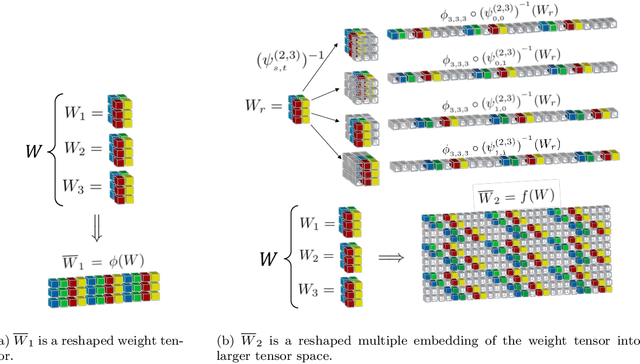
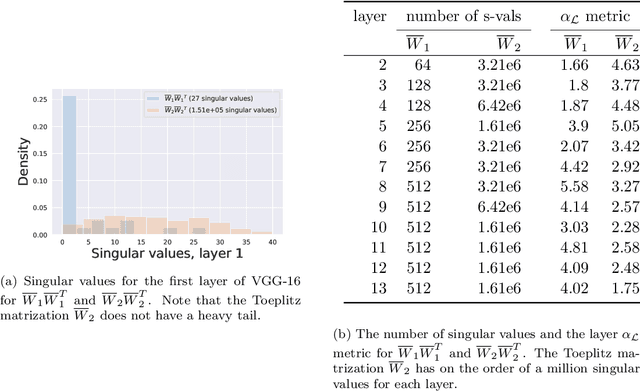
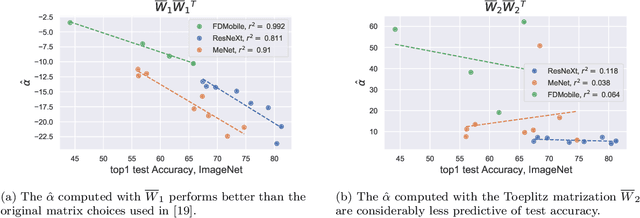
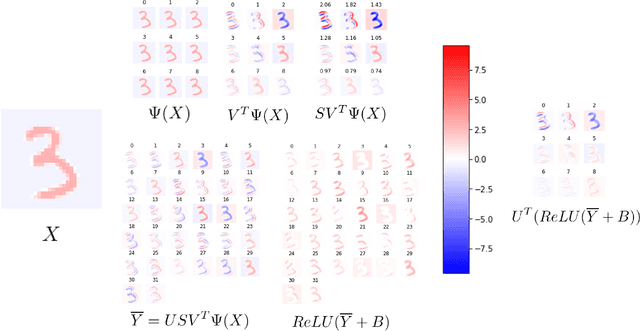
Deep neural networks used for image classification often use convolutional filters to extract distinguishing features before passing them to a linear classifier. Most interpretability literature focuses on providing semantic meaning to convolutional filters to explain a model's reasoning process and confirm its use of relevant information from the input domain. Fully connected layers can be studied by decomposing their weight matrices using a singular value decomposition, in effect studying the correlations between the rows in each matrix to discover the dynamics of the map. In this work we define a singular value decomposition for the weight tensor of a convolutional layer, which provides an analogous understanding of the correlations between filters, exposing the dynamics of the convolutional map. We validate our definition using recent results in random matrix theory. By applying the decomposition across the linear layers of an image classification network we suggest a framework against which interpretability methods might be applied using hypergraphs to model class separation. Rather than looking to the activations to explain the network, we use the singular vectors with the greatest corresponding singular values for each linear layer to identify those features most important to the network. We illustrate our approach with examples and introduce the DeepDataProfiler library, the analysis tool used for this study.
Residual Graph Convolutional Recurrent Networks For Multi-step Traffic Flow Forecasting
May 03, 2022

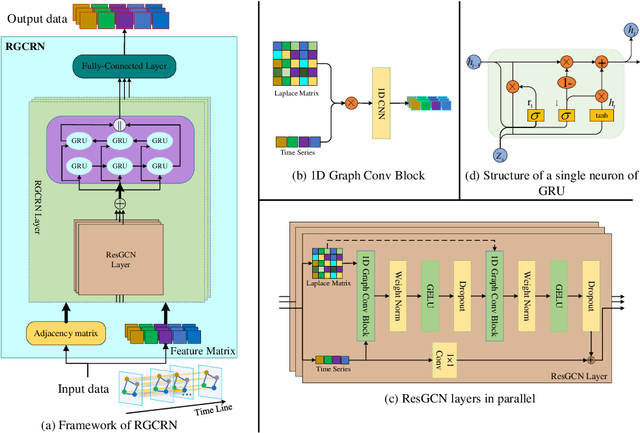
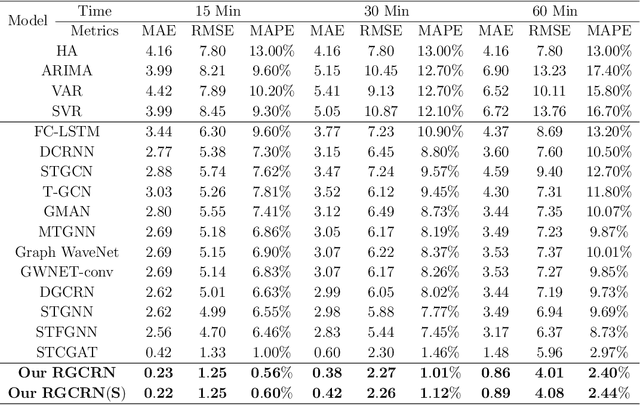
Traffic flow forecasting is essential for traffic planning, control and management. The main challenge of traffic forecasting tasks is accurately capturing traffic networks' spatial and temporal correlation. Although there are many traffic forecasting methods, most of them still have limitations in capturing spatial and temporal correlations. To improve traffic forecasting accuracy, we propose a new Spatial-temporal forecasting model, namely the Residual Graph Convolutional Recurrent Network (RGCRN). The model uses our proposed Residual Graph Convolutional Network (ResGCN) to capture the fine-grained spatial correlation of the traffic road network and then uses a Bi-directional Gated Recurrent Unit (BiGRU) to model time series with spatial information and obtains the temporal correlation by analysing the change in information transfer between the forward and reverse neurons of the time series data. Our comparative experimental results on two real datasets show that RGCRN improves on average by 20.66% compared to the best baseline model. You can get our source code and data through https://github.com/zhangshqii/RGCRN.
STCGAT: Spatial-temporal causal networks for complex urban road traffic flow prediction
Mar 21, 2022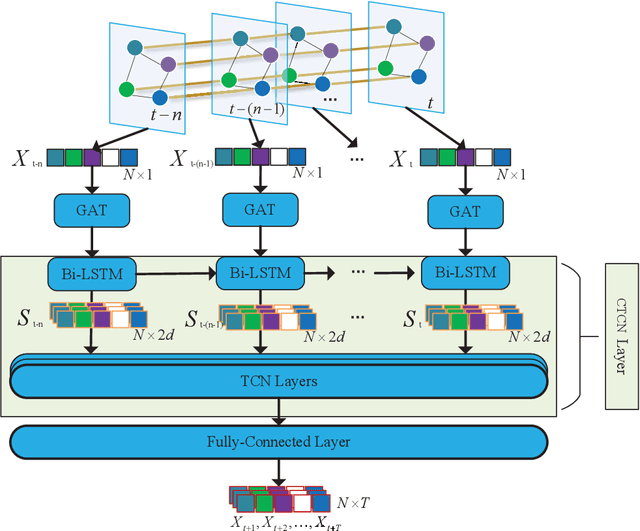
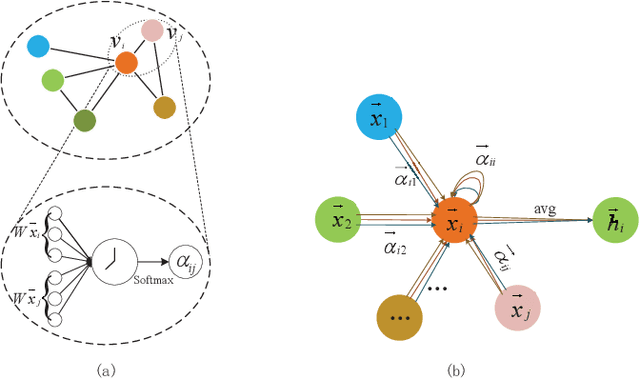
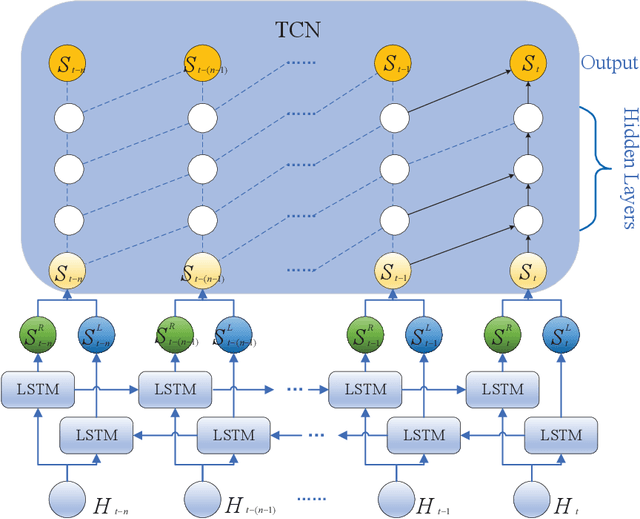
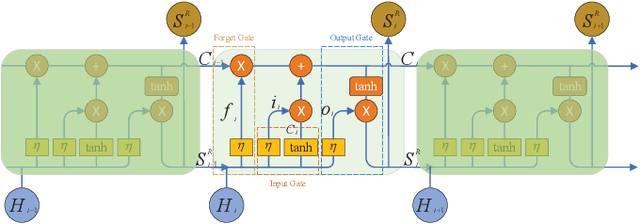
Traffic forecasting is an essential component of intelligent transportation systems. However, traffic data are highly nonlinear and have complex spatial correlations between road nodes. Therefore, it is incredibly challenging to dig deeper into the underlying Spatial-temporal relationships from the complex traffic data. Existing approaches usually use fixed traffic road network topology maps and independent time series modules to capture Spatial-temporal correlations, ignoring the dynamic changes of traffic road networks and the inherent temporal causal relationships between traffic events. Therefore, a new prediction model is proposed in this study. The model dynamically captures the spatial dependence of the traffic network through a Graph Attention Network(GAT) and then analyzes the causal relationship of the traffic data using our proposed Causal Temporal Convolutional Network(CTCN) to obtain the overall temporal dependence. We conducted extensive comparison experiments with other traffic prediction methods on two real traffic datasets to evaluate the model's prediction performance. Compared with the best experimental results of different prediction methods, the prediction performance of our approach is improved by more than 50%. You can get our source code and data through https://github.com/zhangshqii/STCGAT.